I-FailSense: Towards General Robotic Failure Detection with Vision-Language Models
作者: Clemence Grislain, Hamed Rahimi, Olivier Sigaud, Mohamed Chetouani
分类: cs.RO
发布日期: 2025-09-19 (更新: 2025-09-22)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
I-FailSense:利用视觉-语言模型实现通用机器人故障检测
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人故障检测 视觉-语言模型 语义错位 模型后训练 集成学习 机器人操作 开放世界 零样本学习
📋 核心要点
- 现有VLM在机器人故障检测,特别是语义错位错误检测方面存在不足,限制了其在真实环境中的鲁棒性。
- 提出I-FailSense框架,通过后训练VLM和集成轻量级分类头,实现对语义错位故障的有效检测。
- 实验表明,I-FailSense在语义错位检测上优于现有VLM,并能泛化到其他故障类别和环境。
📝 摘要(中文)
在开放世界环境中,基于语言条件的机器人操作不仅需要精确的任务执行,还需要具备检测故障的能力,以确保在真实环境中的稳健部署。尽管视觉-语言模型(VLM)的最新进展显著提高了机器人的空间推理和任务规划能力,但它们在识别自身故障方面的能力仍然有限。特别是一个关键但未被充分探索的挑战是检测语义错位错误,即机器人执行的任务在语义上是有意义的,但与给定的指令不一致。为了解决这个问题,我们提出了一种从现有的基于语言条件的操作数据集中构建针对语义错位故障检测的数据集的方法。我们还提出了I-FailSense,一个具有基础仲裁的开源VLM框架,专门用于故障检测。我们的方法依赖于对基础VLM进行后训练,然后训练轻量级的分类头,称为FS块,这些分类头连接到VLM的不同内部层,并且它们的预测使用集成机制进行聚合。实验表明,I-FailSense在检测语义错位错误方面优于最先进的VLM,无论是在规模上可比的还是更大的VLM。值得注意的是,尽管仅在语义错位检测上进行训练,但I-FailSense可以推广到更广泛的机器人故障类别,并有效地转移到其他模拟环境和真实世界,具有零样本或最小的后训练。
🔬 方法详解
问题定义:论文旨在解决机器人操作中,视觉-语言模型(VLM)难以检测语义错位故障的问题。语义错位故障指的是机器人执行的任务在语义上合理,但与用户指令不符的情况。现有方法难以有效识别此类故障,降低了机器人在复杂环境中的可靠性。
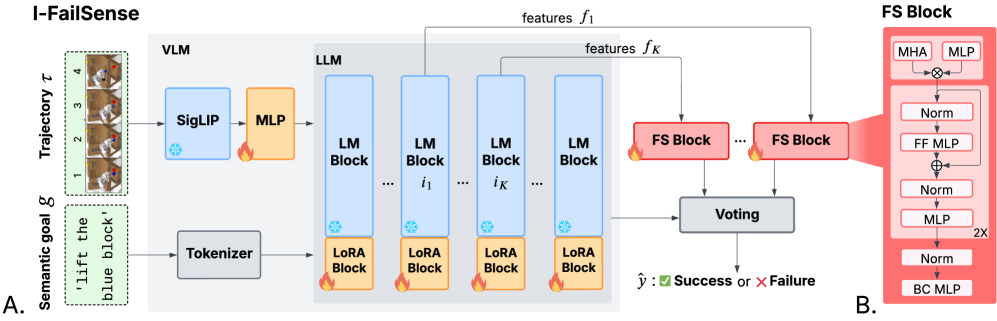
核心思路:论文的核心思路是利用后训练的基础VLM,并附加多个轻量级的分类头(FS blocks)到VLM的不同内部层。通过集成这些分类头的预测结果,可以更准确地判断机器人是否发生了语义错位故障。这种方法旨在利用VLM强大的语义理解能力,同时降低计算成本。
技术框架:I-FailSense框架包含以下主要步骤:1) 数据集构建:从现有的语言条件操作数据集中构建针对语义错位故障检测的数据集。2) 基础VLM后训练:对预训练的VLM进行后训练,使其更适应机器人操作任务。3) FS块训练:在VLM的不同内部层附加轻量级的分类头(FS blocks),并训练这些分类头来预测故障类型。4) 集成预测:使用集成机制聚合来自不同FS块的预测结果,得到最终的故障检测结果。
关键创新:论文的关键创新在于提出了基于VLM内部层特征集成的故障检测方法。通过在VLM的不同层级添加分类头,并集成它们的预测结果,可以更全面地利用VLM的语义信息,从而提高故障检测的准确性。此外,论文还提出了一种构建语义错位故障检测数据集的方法。
关键设计:FS块是轻量级的分类头,可以使用简单的全连接层或卷积层实现。集成的具体方法可以是加权平均或更复杂的学习方法。论文可能还涉及损失函数的设计,例如交叉熵损失函数,用于训练FS块。具体的VLM选择以及后训练的参数设置也是关键设计。
🖼️ 关键图片


📊 实验亮点
I-FailSense在语义错位错误检测方面优于现有VLM,包括规模相当甚至更大的模型。实验结果表明,该方法不仅在训练数据集上表现良好,而且能够泛化到其他机器人故障类别、模拟环境和真实世界,具有良好的零样本或少量样本迁移能力。具体的性能提升数据需要在论文中查找。
🎯 应用场景
该研究成果可应用于各种需要机器人进行复杂操作的场景,例如智能制造、家庭服务、医疗辅助等。通过提高机器人对自身故障的检测能力,可以显著提升其在真实环境中的可靠性和安全性,降低人为干预的需求,并最终实现更智能、更自主的机器人系统。
📄 摘要(原文)
Language-conditioned robotic manipulation in open-world settings requires not only accurate task execution but also the ability to detect failures for robust deployment in real-world environments. Although recent advances in vision-language models (VLMs) have significantly improved the spatial reasoning and task-planning capabilities of robots, they remain limited in their ability to recognize their own failures. In particular, a critical yet underexplored challenge lies in detecting semantic misalignment errors, where the robot executes a task that is semantically meaningful but inconsistent with the given instruction. To address this, we propose a method for building datasets targeting Semantic Misalignment Failures detection, from existing language-conditioned manipulation datasets. We also present I-FailSense, an open-source VLM framework with grounded arbitration designed specifically for failure detection. Our approach relies on post-training a base VLM, followed by training lightweight classification heads, called FS blocks, attached to different internal layers of the VLM and whose predictions are aggregated using an ensembling mechanism. Experiments show that I-FailSense outperforms state-of-the-art VLMs, both comparable in size and larger, in detecting semantic misalignment errors. Notably, despite being trained only on semantic misalignment detection, I-FailSense generalizes to broader robotic failure categories and effectively transfers to other simulation environments and real-world with zero-shot or minimal post-training. The datasets and models are publicly released on HuggingFace (Webpage: https://clemgris.github.io/I-FailSense/).