A Vision-Language-Action-Critic Model for Robotic Real-World Reinforcement Learning
作者: Shaopeng Zhai, Qi Zhang, Tianyi Zhang, Fuxian Huang, Haoran Zhang, Ming Zhou, Shengzhe Zhang, Litao Liu, Sixu Lin, Jiangmiao Pang
分类: cs.RO, cs.AI
发布日期: 2025-09-19
备注: 26 pages,10 figures
💡 一句话要点
提出VLAC模型,解决机器人真实世界强化学习中奖励稀疏和探索低效问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人强化学习 视觉语言模型 奖励函数设计 真实世界机器人 人工参与学习
📋 核心要点
- 现有机器人强化学习方法依赖手工设计的稀疏奖励,导致探索效率低下,难以适应新任务。
- VLAC模型通过学习视觉-语言-动作之间的关系,自动生成密集奖励信号,无需人工设计,支持零样本迁移。
- 实验表明,VLAC在真实机器人任务中显著提升了成功率和样本效率,结合人工干预效果更佳。
📝 摘要(中文)
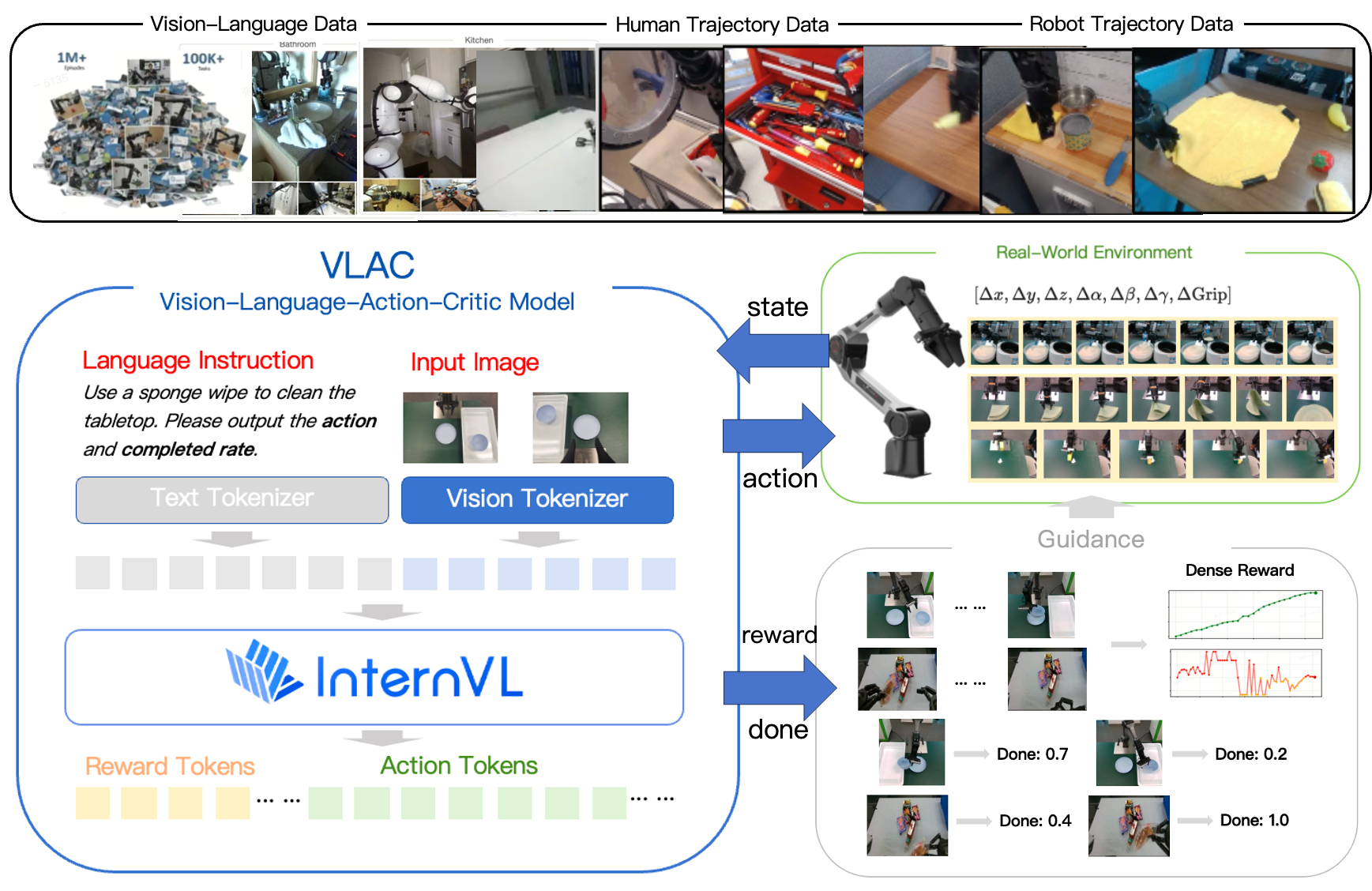
本文提出了一种视觉-语言-动作-评论(VLAC)模型,用于解决机器人真实世界强化学习中奖励稀疏和探索效率低下的问题。VLAC是一个通用的过程奖励模型,基于InternVL构建,并在大规模异构数据集上进行训练。给定成对的观察和语言目标,VLAC输出密集的进度增量和完成信号,消除了特定于任务的奖励工程,并支持一次性上下文迁移到未见过的任务和环境。VLAC在视觉-语言数据集上进行训练,以加强感知、对话和推理能力,同时利用机器人和人类轨迹数据来 grounding 动作生成和进度估计,并通过构建大量的负样本和语义不匹配的样本来拒绝不相关的提示并检测退化或停滞。通过提示控制,单个VLAC模型交替生成奖励和动作token,统一了评论和策略。在异步真实世界强化学习循环中部署,我们分层了一个分级的人工参与协议(离线演示回放、return and explore、人工引导探索),加速了探索并稳定了早期学习。在四个不同的真实世界操作任务中,VLAC将成功率从大约30%提高到大约90%,在200个真实世界交互episode内;结合人工参与干预,样本效率进一步提高了50%,并实现了高达100%的最终成功率。
🔬 方法详解
问题定义:机器人真实世界强化学习面临奖励函数设计困难和探索效率低下的挑战。传统方法依赖于手工设计的稀疏奖励,这需要大量的领域知识,并且难以泛化到新的任务和环境中。此外,由于奖励信号稀疏,机器人难以有效地探索环境,导致学习效率低下。
核心思路:本文的核心思路是利用视觉-语言模型学习一个通用的过程奖励模型,该模型能够根据视觉输入和语言目标,自动生成密集的奖励信号。通过学习视觉、语言和动作之间的关系,模型可以理解任务目标,并评估当前状态与目标状态之间的差距,从而为机器人提供有效的学习信号。
技术框架:VLAC模型基于InternVL构建,整体框架包含以下几个主要模块:1) 视觉编码器:用于提取视觉输入的特征表示;2) 语言编码器:用于提取语言目标的特征表示;3) 动作生成器:用于生成机器人的动作;4) 奖励预测器:用于预测当前状态的奖励值和完成信号。模型通过异步强化学习循环进行训练,并结合人工参与协议,加速探索和稳定学习。
关键创新:VLAC的关键创新在于其通用的过程奖励模型,该模型无需人工设计奖励函数,即可自动生成密集的奖励信号。此外,VLAC还通过构建大量的负样本和语义不匹配的样本,提高了模型的鲁棒性和泛化能力。通过提示控制,VLAC模型可以交替生成奖励和动作token,统一了评论和策略。
关键设计:VLAC模型使用InternVL作为基础模型,并在此基础上进行了改进。模型采用了对比学习的方法,通过最大化正样本之间的相似度,最小化负样本之间的相似度,来学习视觉、语言和动作之间的关系。此外,模型还使用了prompt控制技术,通过不同的prompt来控制模型的行为,例如生成奖励或生成动作。
🖼️ 关键图片


📊 实验亮点
VLAC模型在四个不同的真实世界操作任务中,将成功率从大约30%提高到大约90%,在200个真实世界交互episode内。结合人工参与干预,样本效率进一步提高了50%,并实现了高达100%的最终成功率。这些结果表明,VLAC模型能够有效地解决机器人强化学习中的奖励稀疏和探索低效问题。
🎯 应用场景
该研究成果可广泛应用于各种机器人操作任务,例如家庭服务机器人、工业自动化机器人和医疗机器人等。通过自动生成奖励信号,可以降低机器人学习的成本,提高机器人的智能化水平,使其能够更好地适应复杂和动态的环境。未来,该技术有望推动机器人技术的普及和应用。
📄 摘要(原文)
Robotic real-world reinforcement learning (RL) with vision-language-action (VLA) models is bottlenecked by sparse, handcrafted rewards and inefficient exploration. We introduce VLAC, a general process reward model built upon InternVL and trained on large scale heterogeneous datasets. Given pairwise observations and a language goal, it outputs dense progress delta and done signal, eliminating task-specific reward engineering, and supports one-shot in-context transfer to unseen tasks and environments. VLAC is trained on vision-language datasets to strengthen perception, dialogic and reasoning capabilities, together with robot and human trajectories data that ground action generation and progress estimation, and additionally strengthened to reject irrelevant prompts as well as detect regression or stagnation by constructing large numbers of negative and semantically mismatched samples. With prompt control, a single VLAC model alternately generating reward and action tokens, unifying critic and policy. Deployed inside an asynchronous real-world RL loop, we layer a graded human-in-the-loop protocol (offline demonstration replay, return and explore, human guided explore) that accelerates exploration and stabilizes early learning. Across four distinct real-world manipulation tasks, VLAC lifts success rates from about 30\% to about 90\% within 200 real-world interaction episodes; incorporating human-in-the-loop interventions yields a further 50% improvement in sample efficiency and achieves up to 100% final success.