Improving Robotic Manipulation with Efficient Geometry-Aware Vision Encoder
作者: An Dinh Vuong, Minh Nhat Vu, Ian Reid
分类: cs.RO
发布日期: 2025-09-19
备注: 9 figures, 7 tables. Project page: https://evggt.github.io/
💡 一句话要点
提出高效几何感知视觉编码器eVGGT,提升机器人操作性能
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人操作 模仿学习 几何感知 视觉编码器 知识蒸馏 3D推理 高效模型
📋 核心要点
- 现有基于RGB的机器人模仿学习方法依赖的视觉编码器缺乏3D推理能力,限制了操作性能。
- 论文提出高效几何感知视觉编码器eVGGT,通过知识蒸馏,在保持3D推理能力的同时显著降低计算成本。
- 实验表明,将eVGGT集成到模仿学习框架中,在模拟和真实环境中均能提升机器人操作的成功率。
📝 摘要(中文)
现有的基于RGB图像的模仿学习方法通常采用ResNet或ViT等传统视觉编码器,缺乏显式的3D推理能力。最近的几何感知视觉模型,如VGGT,提供了强大的空间理解能力,有望解决这一局限性。本文研究了将几何感知视觉表示集成到机器人操作中。结果表明,在模仿学习框架(包括ACT和DP)中加入几何感知视觉编码器,在模拟和真实环境中的单手和双手操作任务中,成功率比标准视觉编码器提高了6.5%。尽管有这些优点,但大多数几何感知模型需要很高的计算成本,限制了它们在实际机器人系统中的部署。为了解决这个问题,我们提出了一种从VGGT中提炼出的高效几何感知编码器eVGGT。eVGGT比VGGT快近9倍,小5倍,同时保持了强大的3D推理能力。代码和预训练模型将被发布,以促进几何感知机器人领域的进一步研究。
🔬 方法详解
问题定义:现有基于RGB图像的机器人操作模仿学习方法,通常使用ResNet或ViT等传统视觉编码器。这些编码器缺乏对场景几何信息的显式建模和推理能力,导致机器人难以准确理解和执行复杂的操作任务。现有几何感知的模型虽然能提供更强的空间理解,但计算成本过高,难以部署到实际机器人系统中。
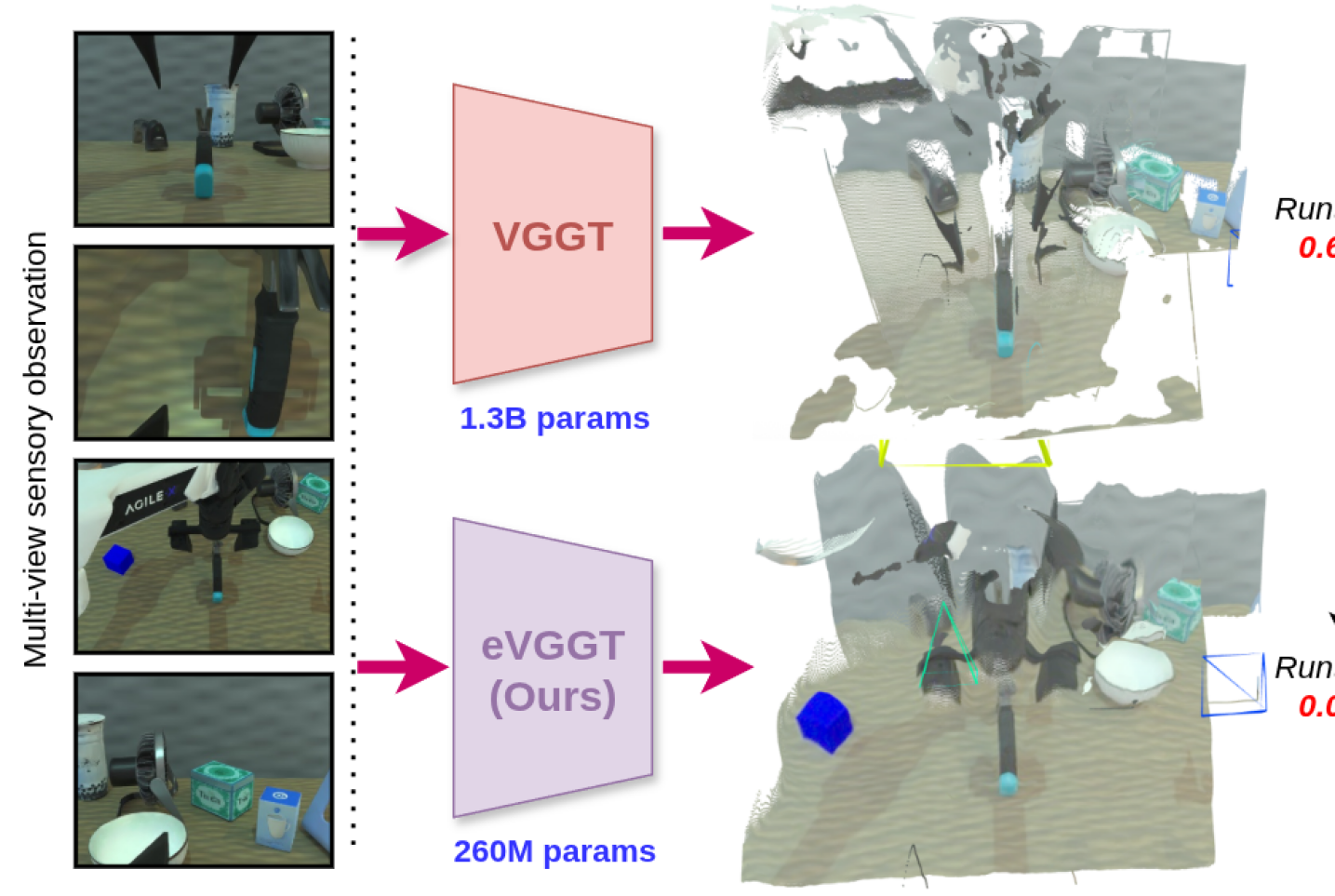
核心思路:论文的核心思路是利用知识蒸馏技术,从计算量大的几何感知模型VGGT中提取知识,训练一个计算效率更高的轻量级模型eVGGT。这样既能保留VGGT强大的3D推理能力,又能显著降低计算成本,使其更适合在资源受限的机器人平台上部署。
技术框架:整体框架包含两个阶段:首先,使用VGGT作为教师模型,生成带有几何信息的视觉特征。然后,使用这些特征作为监督信号,训练学生模型eVGGT。训练完成后,将eVGGT集成到模仿学习框架(如ACT或DP)中,用于机器人的操作策略学习。整体流程是从VGGT提取知识,然后用提取的知识训练一个更高效的模型,最后将这个高效的模型应用到机器人操作任务中。
关键创新:最重要的技术创新点是提出了高效的几何感知视觉编码器eVGGT,它通过知识蒸馏,在保持3D推理能力的同时,显著降低了计算成本。与直接使用VGGT相比,eVGGT在计算效率上有了显著提升,使其更适合在实际机器人系统中部署。
关键设计:eVGGT的网络结构设计目标是尽可能地简化模型,同时保留VGGT的关键特征提取能力。具体的蒸馏训练过程可能涉及到特定的损失函数,例如最小化VGGT和eVGGT输出特征之间的差异。论文可能还对eVGGT的网络结构进行了微调,以进一步提高其效率和性能。具体的参数设置和网络结构细节需要在论文中查找。
🖼️ 关键图片


📊 实验亮点
实验结果表明,将eVGGT集成到模仿学习框架中,在单手和双手操作任务中,成功率比标准视觉编码器提高了高达6.5%。同时,eVGGT比VGGT快近9倍,小5倍,在保持性能的同时显著降低了计算成本,使其更适合在实际机器人系统中部署。
🎯 应用场景
该研究成果可广泛应用于各种需要机器人进行精确操作的场景,如工业自动化、医疗手术、家庭服务等。通过提升机器人对环境的3D感知能力,可以提高操作的准确性和鲁棒性,降低对环境的依赖,从而实现更智能、更可靠的机器人操作。
📄 摘要(原文)
Existing RGB-based imitation learning approaches typically employ traditional vision encoders such as ResNet or ViT, which lack explicit 3D reasoning capabilities. Recent geometry-grounded vision models, such as VGGT~\cite{wang2025vggt}, provide robust spatial understanding and are promising candidates to address this limitation. This work investigates the integration of geometry-aware visual representations into robotic manipulation. Our results suggest that incorporating the geometry-aware vision encoder into imitation learning frameworks, including ACT and DP, yields up to 6.5% improvement over standard vision encoders in success rate across single- and bi-manual manipulation tasks in both simulation and real-world settings. Despite these benefits, most geometry-grounded models require high computational cost, limiting their deployment in practical robotic systems. To address this challenge, we propose eVGGT, an efficient geometry-aware encoder distilled from VGGT. eVGGT is nearly 9 times faster and 5 times smaller than VGGT, while preserving strong 3D reasoning capabilities. Code and pretrained models will be released to facilitate further research in geometry-aware robotics.