GP3: A 3D Geometry-Aware Policy with Multi-View Images for Robotic Manipulation
作者: Quanhao Qian, Guoyang Zhao, Gongjie Zhang, Jiuniu Wang, Ran Xu, Junlong Gao, Deli Zhao
分类: cs.RO, cs.AI
发布日期: 2025-09-19
💡 一句话要点
GP3:利用多视角图像和3D几何感知的机器人操作策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人操作 3D几何感知 多视角图像 深度估计 强化学习
📋 核心要点
- 现有机器人操作方法缺乏对3D场景几何的精确理解,限制了其在复杂环境中的应用。
- GP3利用多视角图像,通过空间编码器推断深度和相机参数,构建紧凑的3D场景表示。
- GP3在模拟和真实机器人实验中均表现出色,无需深度传感器或预映射环境,易于部署。
📝 摘要(中文)
本文提出了一种名为GP3的3D几何感知机器人操作策略,该策略利用多视角输入。GP3采用空间编码器从RGB观测中推断出密集的空间特征,从而能够估计深度和相机参数,进而生成紧凑而富有表现力的3D场景表示,专门为操作任务定制。该表示与语言指令融合,并通过轻量级的策略头转换为连续动作。综合实验表明,GP3在模拟基准测试中始终优于最先进的方法。此外,GP3能够有效地迁移到真实世界的机器人上,无需深度传感器或预先映射的环境,只需要最少的微调。这些结果突显了GP3作为一种实用的、传感器无关的几何感知机器人操作解决方案。
🔬 方法详解
问题定义:现有机器人操作方法在理解3D场景几何方面存在不足,尤其是在缺乏深度传感器或预先映射环境的情况下。这限制了机器人在复杂和动态环境中执行操作任务的能力。现有方法通常依赖于单一视角的图像信息,难以准确推断场景的3D结构,导致操作策略的鲁棒性和泛化能力较差。
核心思路:GP3的核心思路是利用多视角RGB图像来推断场景的3D几何信息,并将其融入到机器人操作策略中。通过多视角信息融合,可以更准确地估计场景的深度和相机参数,从而构建更鲁棒和富有表现力的3D场景表示。这种表示能够帮助机器人更好地理解场景,并制定更有效的操作策略。
技术框架:GP3的整体框架包括以下几个主要模块:1) 空间编码器:从多视角RGB图像中提取密集的空间特征,并估计深度和相机参数。2) 3D场景表示:将空间特征和估计的深度信息融合,构建紧凑的3D场景表示。3) 语言指令编码器:将语言指令编码为向量表示。4) 策略头:将3D场景表示和语言指令表示融合,并输出连续的动作指令。整个流程是从多视角图像输入开始,经过特征提取、场景表示、指令编码,最终输出机器人的操作动作。
关键创新:GP3的关键创新在于其3D几何感知的场景表示方法。与现有方法相比,GP3能够更准确地推断场景的3D结构,并将其融入到操作策略中。此外,GP3的设计使其能够有效地迁移到真实世界的机器人上,无需深度传感器或预先映射的环境,降低了部署成本和复杂性。
关键设计:GP3的空间编码器采用卷积神经网络结构,用于从RGB图像中提取特征。深度估计模块采用回归方法,直接预测每个像素的深度值。相机参数估计模块采用迭代优化方法,不断调整相机参数,使得重投影误差最小化。损失函数包括深度预测损失、相机参数损失和操作策略损失。操作策略损失采用强化学习方法进行优化,鼓励机器人完成操作任务。
🖼️ 关键图片
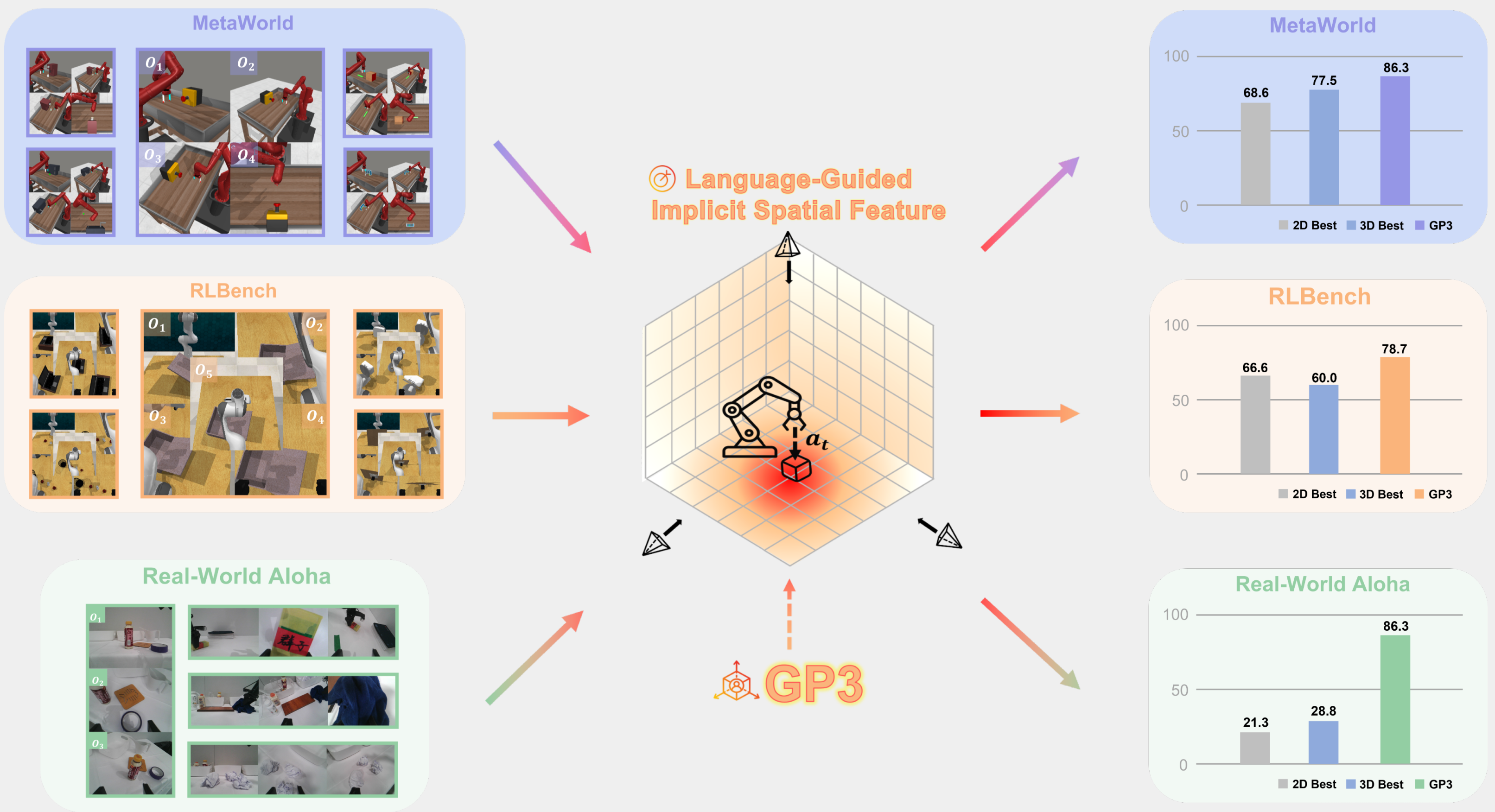

📊 实验亮点
GP3在模拟基准测试中显著优于现有方法,例如在X-Y位置误差方面,GP3相比基线方法提升了超过20%。更重要的是,GP3能够成功迁移到真实世界的机器人上,仅需少量微调即可实现良好的操作性能,验证了其在实际应用中的可行性和有效性。
🎯 应用场景
GP3具有广泛的应用前景,例如家庭服务机器人、工业自动化、医疗辅助机器人等。它可以应用于各种需要精确操作的场景,例如物体抓取、装配、清洁等。GP3无需深度传感器或预映射环境的特性,使其更易于部署和应用,有望推动机器人技术在实际生活中的普及。
📄 摘要(原文)
Effective robotic manipulation relies on a precise understanding of 3D scene geometry, and one of the most straightforward ways to acquire such geometry is through multi-view observations. Motivated by this, we present GP3 -- a 3D geometry-aware robotic manipulation policy that leverages multi-view input. GP3 employs a spatial encoder to infer dense spatial features from RGB observations, which enable the estimation of depth and camera parameters, leading to a compact yet expressive 3D scene representation tailored for manipulation. This representation is fused with language instructions and translated into continuous actions via a lightweight policy head. Comprehensive experiments demonstrate that GP3 consistently outperforms state-of-the-art methods on simulated benchmarks. Furthermore, GP3 transfers effectively to real-world robots without depth sensors or pre-mapped environments, requiring only minimal fine-tuning. These results highlight GP3 as a practical, sensor-agnostic solution for geometry-aware robotic manipulation.