Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
作者: Fei Ni, Min Zhang, Pengyi Li, Yifu Yuan, Lingfeng Zhang, Yuecheng Liu, Peilong Han, Longxin Kou, Shaojin Ma, Jinbin Qiao, David Gamaliel Arcos Bravo, Yuening Wang, Xiao Hu, Zhanguang Zhang, Xianze Yao, Yutong Li, Zhao Zhang, Ying Wen, Ying-Cong Chen, Xiaodan Liang, Liang Lin, Bin He, Haitham Bou-Ammar, He Wang, Huazhe Xu, Jiankang Deng, Shan Luo, Shuqiang Jiang, Wei Pan, Yang Gao, Stefanos Zafeiriou, Jan Peters, Yuzheng Zhuang, Yingxue Zhang, Yan Zheng, Hongyao Tang, Jianye Hao
分类: cs.RO
发布日期: 2025-09-18 (更新: 2025-09-23)
备注: 32 pages, 5 figures, Embodied Arena Technical Report
💡 一句话要点
Embodied Arena:构建全面、统一、可演进的具身智能评估平台
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 评估平台 机器人 自动化数据生成 大型语言模型 基准测试 能力分类 实时排行榜
📋 核心要点
- 具身智能发展受限于缺乏系统性能力理解、统一评估标准和可扩展数据获取方法。
- Embodied Arena平台通过构建能力分类、统一评估系统和自动化数据生成管道来解决这些问题。
- 平台发布实时排行榜,提供模型能力全面概览,并总结九个发现,指明研究方向。
📝 摘要(中文)
具身智能的发展显著落后于大型基础模型,这归因于三个关键挑战:(1) 缺乏对具身智能所需核心能力的系统性理解,导致研究缺乏明确目标;(2) 缺乏统一和标准化的评估系统,使得跨基准评估不可行;(3) 用于具身数据的自动化和可扩展获取方法不发达,为模型扩展造成严重瓶颈。为了解决这些障碍,我们提出了Embodied Arena,这是一个全面、统一和不断发展的具身智能评估平台。我们的平台建立了一个系统的具身能力分类法,涵盖三个层次(感知、推理、任务执行)、七个核心能力和25个细粒度维度,从而实现具有系统研究目标的统一评估。我们引入了一个标准化的评估系统,该系统建立在统一的基础设施之上,支持跨三个领域(2D/3D具身问答、导航、任务规划)的22个不同基准和来自20多个全球机构的30多个高级模型的灵活集成。此外,我们开发了一种新颖的LLM驱动的自动化生成管道,确保可扩展的具身评估数据,并不断发展以实现多样性和全面性。Embodied Arena发布了三个实时排行榜(具身问答、导航、任务规划),具有双重视角(基准视图和能力视图),提供了高级模型能力的全面概述。特别地,我们总结了从Embodied Arena排行榜的评估结果中得出的九个发现。这有助于建立明确的研究方向并查明关键的研究问题,从而推动具身智能领域的进步。
🔬 方法详解
问题定义:具身智能领域面临缺乏系统性评估标准和可扩展数据的问题,导致研究目标不明确,模型难以有效扩展。现有方法难以在不同任务和模型之间进行公平比较,阻碍了领域发展。
核心思路:Embodied Arena的核心思路是构建一个全面、统一、可演进的评估平台,通过系统化的能力分类、标准化的评估体系和自动化的数据生成,为具身智能研究提供清晰的目标和可扩展的资源。这样设计旨在促进不同模型之间的公平比较,并推动领域内的持续进步。
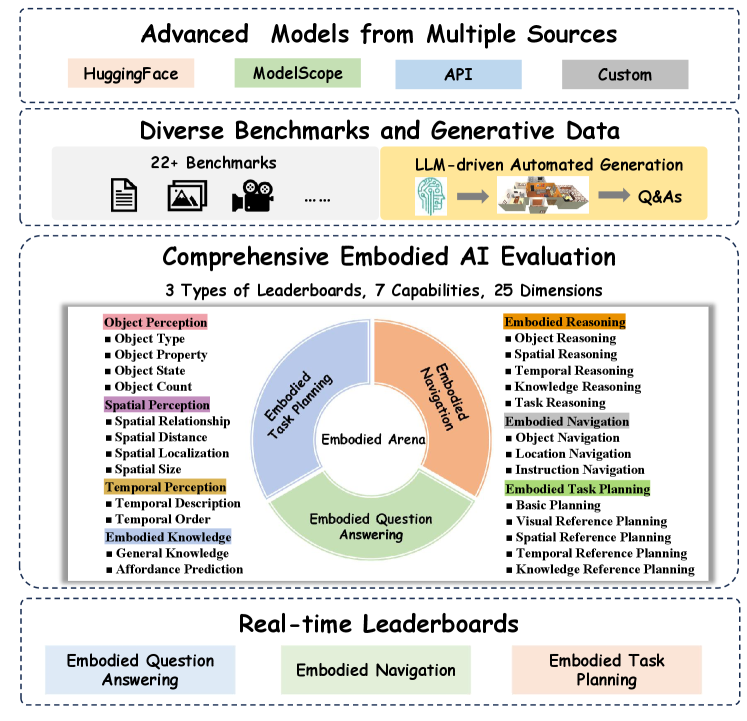
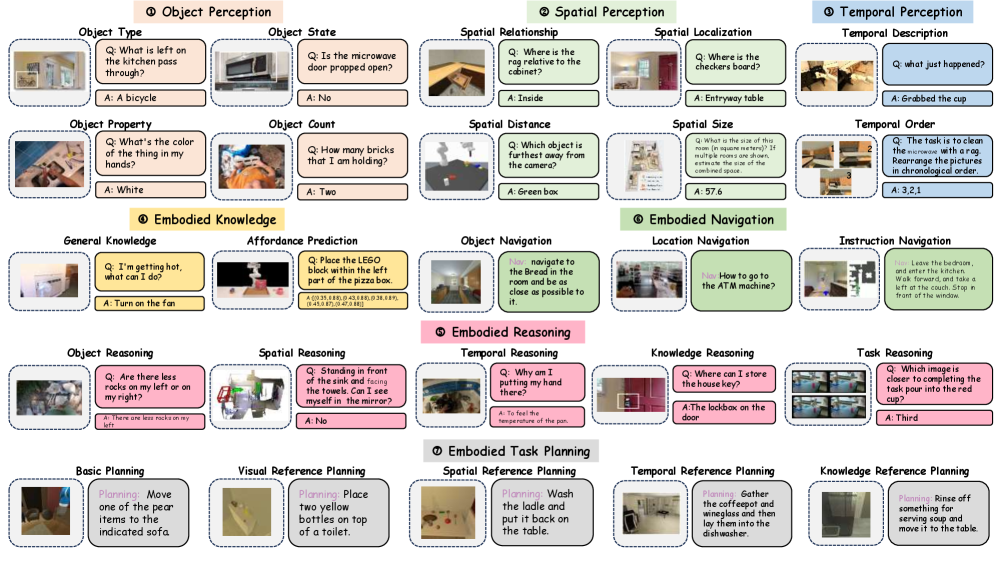
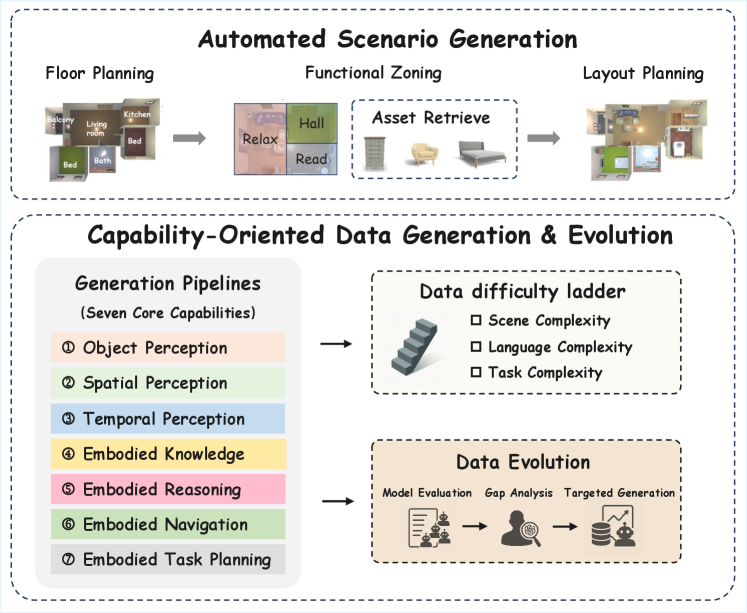
技术框架:Embodied Arena平台包含三个主要组成部分:(1) 能力分类体系:将具身智能能力划分为感知、推理和任务执行三个层次,并进一步细分为七个核心能力和25个细粒度维度。(2) 统一评估系统:构建在统一的基础设施之上,支持集成22个不同的基准测试,涵盖2D/3D具身问答、导航和任务规划等领域。(3) 自动化数据生成管道:利用大型语言模型(LLM)驱动的自动化生成流程,确保评估数据的可扩展性、多样性和全面性。平台还提供实时排行榜,从基准和能力两个角度展示模型性能。
关键创新:Embodied Arena的关键创新在于其综合性和统一性。它不仅提供了一个标准化的评估平台,还构建了一个系统的能力分类体系,并利用LLM实现了评估数据的自动化生成。这种综合性的方法使得研究人员能够更清晰地理解模型的能力,并更有效地进行模型训练和评估。与现有方法相比,Embodied Arena更加全面、灵活和可扩展。
关键设计:平台采用模块化设计,方便集成新的基准测试和模型。自动化数据生成管道利用LLM生成多样化的场景和任务,并采用过滤和验证机制确保数据质量。排行榜采用双重视角,从基准和能力两个维度展示模型性能,方便研究人员进行分析和比较。具体参数设置和网络结构取决于集成的具体模型和基准测试。
🖼️ 关键图片
📊 实验亮点
Embodied Arena平台发布了三个实时排行榜,涵盖具身问答、导航和任务规划。通过对排行榜数据的分析,论文总结了九个关键发现,例如,现有模型在复杂推理和长期规划方面仍存在不足,这为未来的研究方向提供了重要参考。
🎯 应用场景
Embodied Arena平台可应用于机器人导航、智能家居、自动驾驶等领域。通过提供标准化的评估和可扩展的数据,该平台能够加速具身智能算法的研发和部署,提升机器人在复杂环境中的感知、推理和决策能力,最终实现更智能、更自主的机器人系统。
📄 摘要(原文)
Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.