Scalable Multi-Objective Robot Reinforcement Learning through Gradient Conflict Resolution
作者: Humphrey Munn, Brendan Tidd, Peter Böhm, Marcus Gallagher, David Howard
分类: cs.RO, cs.LG
发布日期: 2025-09-18
🔗 代码/项目: GITHUB
💡 一句话要点
提出GCR-PPO算法,通过梯度冲突解决实现可扩展的多目标机器人强化学习。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多目标强化学习 机器人控制 梯度冲突解决 近端策略优化 Actor-Critic IsaacLab 可扩展性
📋 核心要点
- 传统强化学习在多目标机器人控制中面临奖励函数调整困难和易陷入局部最优的挑战,限制了其可扩展性。
- GCR-PPO通过分解actor更新为目标方向梯度,并根据目标优先级解决梯度冲突,从而优化多目标任务。
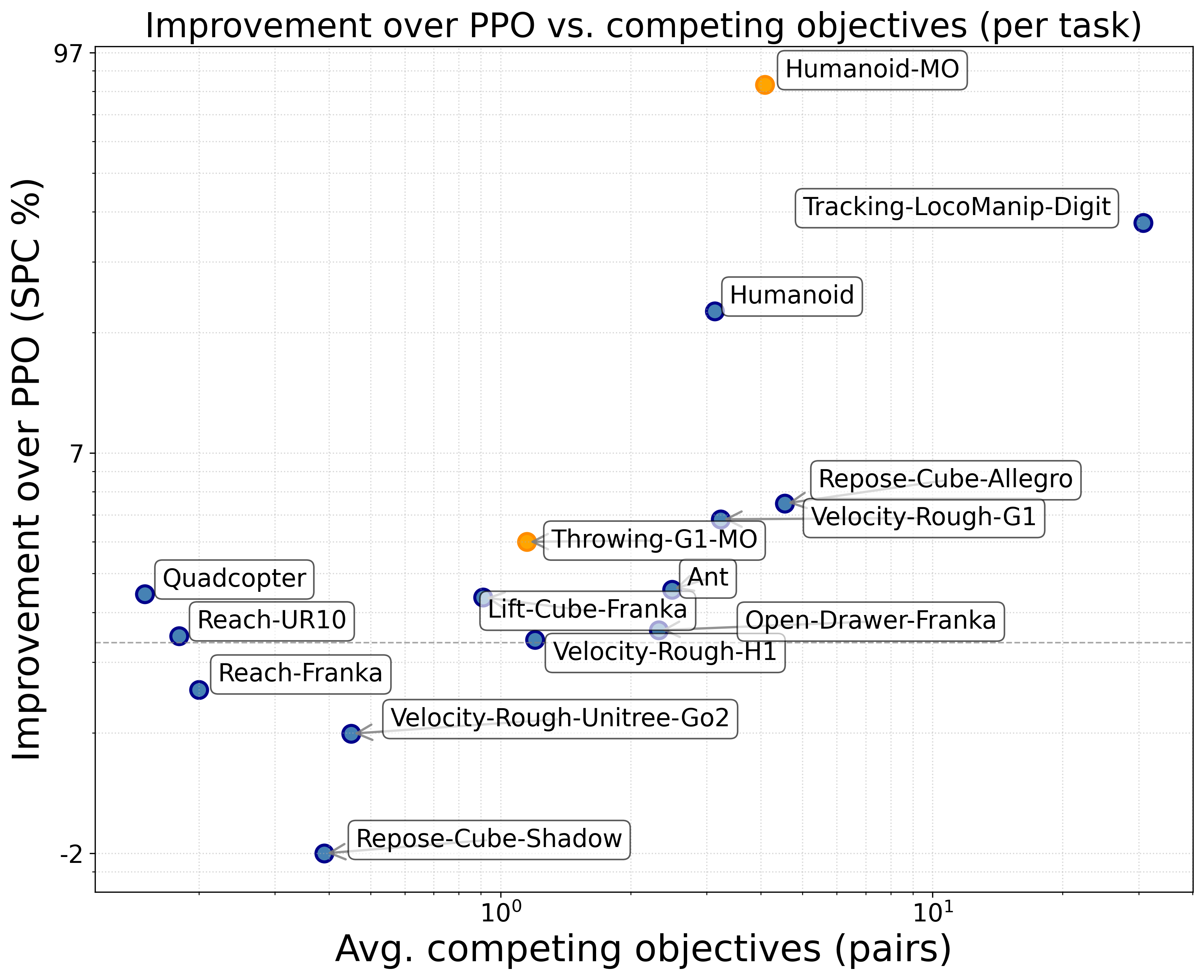
- 实验表明,GCR-PPO在IsaacLab基准测试中优于并行PPO,尤其在高冲突任务中性能提升显著,平均提升9.5%。
📝 摘要(中文)
强化学习(RL)机器人控制器通常将多个任务目标聚合为单一标量奖励。虽然大规模近端策略优化(PPO)已在现实世界中实现了强大的机器人运动等成果,但许多任务仍然需要仔细的奖励调整,并且容易受到局部最优解的影响,成本调整和次优性随着目标数量的增加而增长,限制了可扩展性。对奖励向量及其权衡进行建模可以解决这些问题;然而,由于计算成本和优化难度,多目标方法在机器人RL中仍然未被充分利用。在这项工作中,我们研究了从标量化任务目标中产生的每个目标的梯度贡献之间的冲突。特别是,我们明确地解决了基于任务的奖励与将策略规范化为现实行为的项之间的冲突。我们提出了GCR-PPO,这是一种对actor-critic优化的修改,它使用多头critic将actor更新分解为目标方向梯度,并根据目标优先级解决冲突。我们的方法GCR-PPO在著名的IsaacLab操作和运动基准以及两个相关任务的其他多目标修改上进行了评估。我们展示了优于并行PPO的可扩展性(p = 0.04),而没有显著的计算开销。我们还展示了在更多冲突任务中更高的性能。GCR-PPO改进了大规模PPO,平均改进了9.5%,高冲突任务观察到更大的改进。代码可在https://github.com/humphreymunn/GCR-PPO获得。
🔬 方法详解
问题定义:现有强化学习机器人控制器通常将多个任务目标合并为单一标量奖励,这需要精细的奖励函数调整,并且容易陷入局部最优,尤其是在目标数量增加时,可扩展性受到限制。现有的多目标强化学习方法由于计算成本和优化难度,在机器人领域应用不足。
核心思路:论文的核心思路是显式地解决不同目标之间的梯度冲突。通过将actor的更新分解为每个目标的梯度贡献,并根据预定义的优先级来解决这些冲突,从而避免了不同目标之间的负面影响,提高了学习效率和性能。
技术框架:GCR-PPO是对标准Actor-Critic框架的改进。它使用一个多头Critic网络,每个头对应一个目标。Actor的更新不再是基于单一标量奖励的梯度,而是分解为每个目标的梯度。然后,一个冲突解决机制根据目标的优先级来决定如何组合这些梯度,最终更新Actor的策略。
关键创新:GCR-PPO的关键创新在于其梯度冲突解决机制。传统方法通常简单地将多个目标的奖励加权求和,忽略了不同目标之间可能存在的冲突。GCR-PPO通过显式地分解和解决梯度冲突,能够更有效地学习多目标任务。与现有方法的本质区别在于,GCR-PPO关注并解决了多目标优化中的梯度冲突问题,而不仅仅是简单地加权求和。
关键设计:GCR-PPO的关键设计包括:1) 多头Critic网络,为每个目标提供独立的价值估计;2) 梯度分解,将Actor的更新分解为每个目标的梯度贡献;3) 冲突解决机制,根据目标优先级来决定如何组合这些梯度。具体实现中,可以使用不同的冲突解决策略,例如基于优先级的加权平均或基于投影的方法。损失函数方面,每个Critic头使用标准的时序差分(TD)误差,Actor的更新则基于解决冲突后的梯度。
🖼️ 关键图片
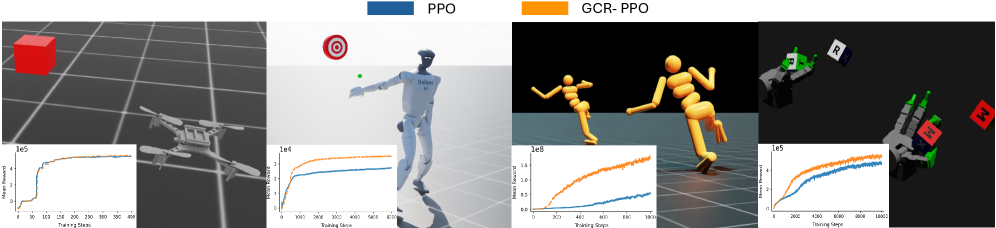

📊 实验亮点
实验结果表明,GCR-PPO在IsaacLab的操纵和运动基准测试中,相较于并行PPO,展现出更优的可扩展性(p=0.04),且在高冲突任务中性能提升更为显著,平均提升9.5%。这验证了GCR-PPO在解决多目标强化学习问题上的有效性,尤其是在目标之间存在冲突的情况下。
🎯 应用场景
GCR-PPO算法可应用于各种需要平衡多个目标的机器人任务,例如复杂环境下的机器人导航、多任务操作、以及需要同时优化效率和安全性的自动驾驶等领域。该方法能够提升机器人在复杂场景下的适应性和鲁棒性,降低人工调整奖励函数的成本,加速机器人智能化进程。
📄 摘要(原文)
Reinforcement Learning (RL) robot controllers usually aggregate many task objectives into one scalar reward. While large-scale proximal policy optimisation (PPO) has enabled impressive results such as robust robot locomotion in the real world, many tasks still require careful reward tuning and are brittle to local optima. Tuning cost and sub-optimality grow with the number of objectives, limiting scalability. Modelling reward vectors and their trade-offs can address these issues; however, multi-objective methods remain underused in RL for robotics because of computational cost and optimisation difficulty. In this work, we investigate the conflict between gradient contributions for each objective that emerge from scalarising the task objectives. In particular, we explicitly address the conflict between task-based rewards and terms that regularise the policy towards realistic behaviour. We propose GCR-PPO, a modification to actor-critic optimisation that decomposes the actor update into objective-wise gradients using a multi-headed critic and resolves conflicts based on the objective priority. Our methodology, GCR-PPO, is evaluated on the well-known IsaacLab manipulation and locomotion benchmarks and additional multi-objective modifications on two related tasks. We show superior scalability compared to parallel PPO (p = 0.04), without significant computational overhead. We also show higher performance with more conflicting tasks. GCR-PPO improves on large-scale PPO with an average improvement of 9.5%, with high-conflict tasks observing a greater improvement. The code is available at https://github.com/humphreymunn/GCR-PPO.