RLBind: Adversarial-Invariant Cross-Modal Alignment for Unified Robust Embeddings
作者: Yuhong Lu
分类: cs.RO, cs.CV
发布日期: 2025-09-17
备注: This paper is submitted to IEEE International Conference on Robotics and Automation (ICRA) 2026
💡 一句话要点
RLBind:对抗不变跨模态对齐,用于统一鲁棒嵌入
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 对抗鲁棒性 跨模态对齐 机器人感知 对比学习
📋 核心要点
- 现有方法在CLIP类编码器中对齐干净和对抗样本特征,忽略了更广泛的跨模态对应关系,导致鲁棒性提升有限。
- RLBind通过两阶段对抗不变跨模态对齐框架,首先增强视觉编码器,然后利用跨模态对应关系进行对齐。
- 实验表明,RLBind在干净数据和对抗攻击下均优于LanguageBind和标准微调方法,提升了多传感器融合的安全性。
📝 摘要(中文)
统一的多模态编码器将视觉、音频和其他传感器绑定到共享的嵌入空间中,是机器人感知和决策的理想构建块。然而,在机器人上的部署使视觉分支暴露于对抗性和自然损坏,使得鲁棒性成为安全性的先决条件。先前的防御通常在CLIP风格的编码器中对齐干净和对抗性特征,而忽略了更广泛的跨模态对应关系,导致收益甚微,并且经常降低零样本迁移性能。我们引入了RLBind,这是一个用于鲁棒统一嵌入的两阶段对抗不变跨模态对齐框架。第一阶段对干净-对抗样本对进行无监督微调,以增强视觉编码器。第二阶段通过最小化干净/对抗特征与文本锚点之间的差异,同时强制跨模态的类间分布对齐,来利用跨模态对应关系。在图像、音频、热成像和视频数据上的大量实验表明,RLBind在干净准确率和范数有界对抗鲁棒性方面始终优于LanguageBind骨干网络和标准微调基线。通过在不牺牲泛化能力的情况下提高弹性,RLBind为导航、操作和其他自主设置中具身机器人的更安全的多传感器感知堆栈提供了一条切实可行的途径。
🔬 方法详解
问题定义:论文旨在解决多模态融合模型在机器人应用中,视觉模态易受对抗攻击影响,导致模型鲁棒性不足的问题。现有方法主要关注视觉模态内部的对抗防御,忽略了跨模态信息的互补性,导致防御效果不佳,且泛化能力下降。
核心思路:论文的核心思路是利用跨模态信息作为锚点,增强视觉模态的对抗鲁棒性。具体来说,通过将对抗样本的视觉特征与对应的文本特征对齐,并强制类间分布对齐,从而提高模型对对抗攻击的抵抗能力。这种方法充分利用了多模态数据的互补性,避免了仅依赖视觉模态内部信息进行防御的局限性。
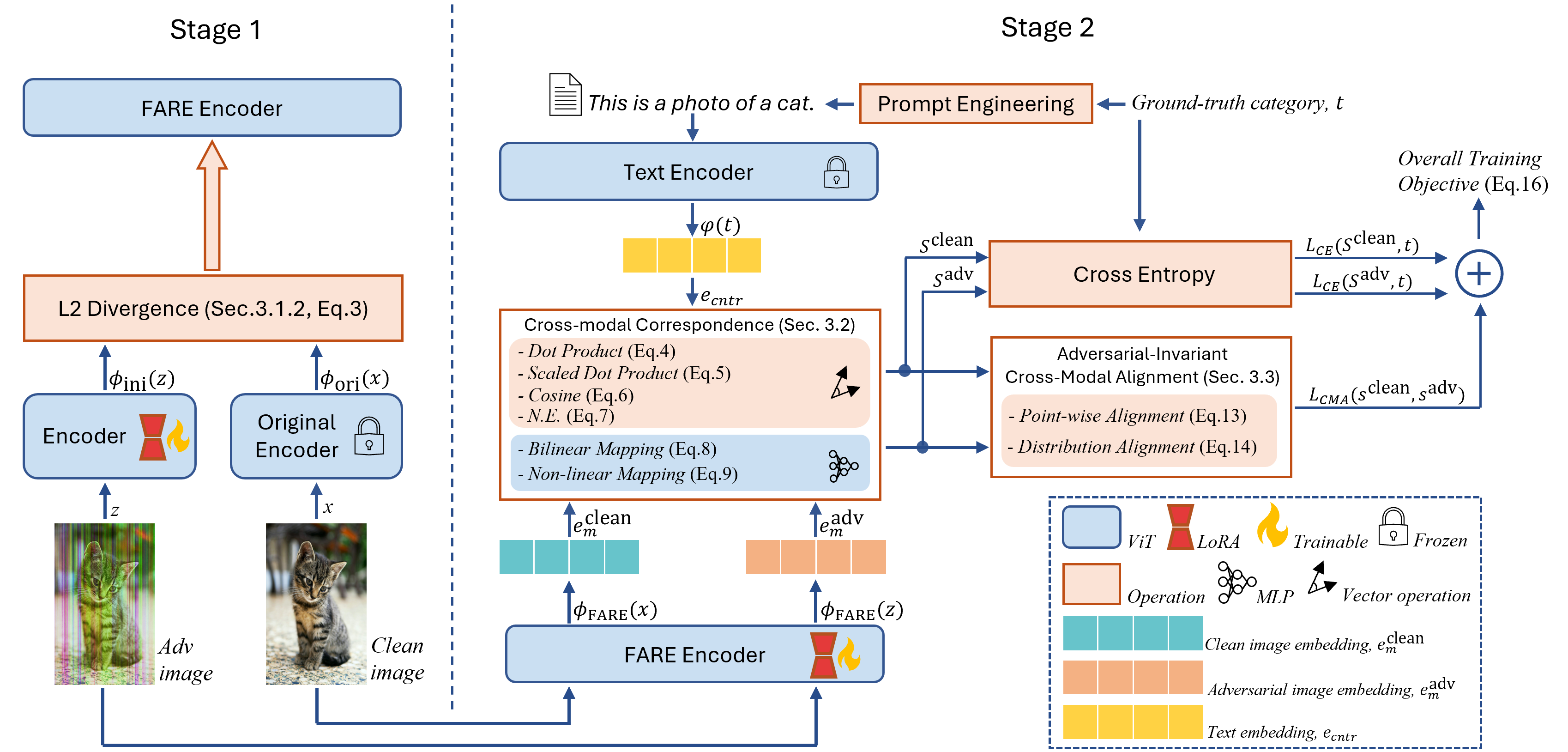
技术框架:RLBind框架包含两个阶段:第一阶段是无监督微调,使用干净-对抗样本对来增强视觉编码器。第二阶段是跨模态对齐,通过最小化干净/对抗特征与文本锚点之间的差异,并强制跨模态的类间分布对齐,来利用跨模态对应关系。整体流程是先增强视觉编码器的鲁棒性,再利用跨模态信息进行精细化对齐。
关键创新:RLBind的关键创新在于其两阶段的跨模态对齐策略。第一阶段的无监督微调增强了视觉编码器的初始鲁棒性,第二阶段的跨模态对齐则利用文本信息作为锚点,进一步提升了模型对对抗攻击的抵抗能力。这种两阶段策略避免了单一模态防御的局限性,充分利用了多模态信息的互补性。
关键设计:RLBind的关键设计包括:1) 使用对比学习损失来最小化干净/对抗特征与文本锚点之间的差异;2) 使用类间分布对齐损失来强制跨模态的类间分布一致性;3) 使用无监督微调来增强视觉编码器的初始鲁棒性。具体的损失函数和网络结构细节在论文中有详细描述,包括对比学习损失的具体形式和类间分布对齐损失的计算方法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RLBind在Image、Audio、Thermal和Video数据集上均优于LanguageBind骨干网络和标准微调基线。在干净数据上,RLBind保持了较高的准确率;在对抗攻击下,RLBind的鲁棒性得到了显著提升。具体的数据指标和提升幅度在论文中有详细展示,证明了RLBind的有效性。
🎯 应用场景
RLBind的研究成果可应用于机器人导航、操作等自主系统中,提高机器人在复杂环境下的感知能力和安全性。例如,在自动驾驶中,可以利用RLBind增强视觉系统对恶意攻击的抵抗能力,避免因对抗样本导致的误判。此外,该方法还可以应用于其他多模态融合场景,如医疗诊断、智能监控等。
📄 摘要(原文)
Unified multi-modal encoders that bind vision, audio, and other sensors into a shared embedding space are attractive building blocks for robot perception and decision-making. However, on-robot deployment exposes the vision branch to adversarial and natural corruptions, making robustness a prerequisite for safety. Prior defenses typically align clean and adversarial features within CLIP-style encoders and overlook broader cross-modal correspondence, yielding modest gains and often degrading zero-shot transfer. We introduce RLBind, a two-stage adversarial-invariant cross-modal alignment framework for robust unified embeddings. Stage 1 performs unsupervised fine-tuning on clean-adversarial pairs to harden the visual encoder. Stage 2 leverages cross-modal correspondence by minimizing the discrepancy between clean/adversarial features and a text anchor, while enforcing class-wise distributional alignment across modalities. Extensive experiments on Image, Audio, Thermal, and Video data show that RLBind consistently outperforms the LanguageBind backbone and standard fine-tuning baselines in both clean accuracy and norm-bounded adversarial robustness. By improving resilience without sacrificing generalization, RLBind provides a practical path toward safer multi-sensor perception stacks for embodied robots in navigation, manipulation, and other autonomy settings.