SeqVLA: Sequential Task Execution for Long-Horizon Manipulation with Completion-Aware Vision-Language-Action Model
作者: Ran Yang, Zijian An, Lifeng ZHou, Yiming Feng
分类: cs.RO
发布日期: 2025-09-17
备注: 8 pages, 9 figures, 1 table
💡 一句话要点
SeqVLA:面向长时程操作任务,基于完成感知的视觉-语言-动作模型实现序列化任务执行
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉语言动作模型 序列任务执行 完成感知 长时程任务
📋 核心要点
- 现有VLA模型在长时程操作任务中,缺乏子任务完成的内部信号,导致序列任务执行脆弱,易出错。
- SeqVLA通过增加一个轻量级的检测头来感知子任务是否完成,从而实现动作生成和子任务切换的自主控制。
- 实验表明,SeqVLA在沙拉包装和糖果包装等多阶段任务中,显著优于基线模型,提升了总体成功率。
📝 摘要(中文)
长时程机器人操作任务需要在严格的序列中执行多个相互依赖的子任务,而子任务完成检测中的错误会扩散到下游任务中,导致失败。现有的视觉-语言-动作(VLA)模型,如$π_0$,擅长连续的低级控制,但缺乏识别子任务何时完成的内部信号,这使得它们在序列化设置中表现脆弱。我们提出了SeqVLA,它是$π_0$的一个完成感知扩展,通过增加一个轻量级的检测头来感知当前子任务是否完成,从而增强了基础架构。这种双头设计使SeqVLA不仅能够生成操作动作,还能够自主地触发子任务之间的转换。我们研究了四种微调策略,这些策略在动作头和检测头的优化方式(联合微调与顺序微调)以及预训练知识的保留方式(完全微调与冻结骨干网络)上有所不同。在两个多阶段任务(包含七个不同子任务的沙拉包装和包含四个不同子任务的糖果包装)上进行了实验。结果表明,SeqVLA在总体成功率方面显著优于基线$π_0$和其他强大的基线。特别是,具有未冻结骨干网络的联合微调产生了最果断和统计上可靠的完成预测,消除了与序列相关的失败,并实现了鲁棒的长时程执行。我们的结果强调了将动作生成与子任务感知检测相结合对于可扩展的序列化操作的重要性。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在处理长时程机器人操作任务时,缺乏对子任务完成状态的感知能力。这意味着模型无法准确判断何时完成一个子任务并开始下一个子任务,导致错误累积,最终影响整个任务的成功率。现有方法主要关注连续的低级控制,而忽略了序列化任务中子任务切换的关键问题。
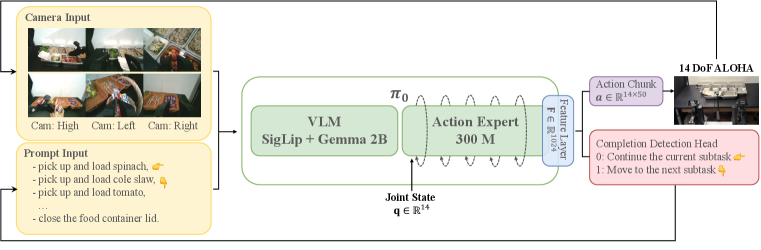
核心思路:SeqVLA的核心思路是在现有的VLA模型基础上,增加一个专门用于检测子任务完成状态的检测头。通过同时优化动作生成和完成状态检测,模型可以学习到更鲁棒的序列化任务执行策略。这种设计使得模型能够自主地判断何时切换到下一个子任务,从而减少了人为干预和错误传播。
技术框架:SeqVLA的整体架构基于现有的VLA模型$π_0$,并在此基础上增加了一个轻量级的检测头。该检测头接收与动作生成模块相同的视觉和语言输入,并输出一个表示当前子任务是否完成的概率值。整个模型包含两个主要模块:动作生成模块和完成状态检测模块。这两个模块可以联合训练,也可以分别训练。
关键创新:SeqVLA最重要的技术创新点在于引入了完成感知机制,使得VLA模型能够自主地判断子任务的完成状态。这与现有方法只关注动作生成而忽略子任务切换的策略形成了鲜明对比。通过将动作生成和完成状态检测相结合,SeqVLA能够更有效地处理长时程序列化任务。
关键设计:论文研究了四种微调策略:(1)联合微调与完全微调,(2)联合微调与冻结骨干网络,(3)顺序微调与完全微调,(4)顺序微调与冻结骨干网络。其中,联合微调指的是同时优化动作生成模块和完成状态检测模块,而顺序微调指的是先优化动作生成模块,再优化完成状态检测模块。完全微调指的是更新整个模型的参数,而冻结骨干网络指的是只更新检测头的参数,保持原有VLA模型的参数不变。实验结果表明,联合微调与完全微调的策略效果最好。
🖼️ 关键图片


📊 实验亮点
SeqVLA在沙拉包装和糖果包装任务中显著优于基线模型$π_0$和其他基线。特别是在沙拉包装任务中,SeqVLA的成功率提升了显著幅度。联合微调与完全微调的策略表现最佳,能够产生最可靠的完成预测,有效避免序列相关的错误,实现鲁棒的长时程任务执行。
🎯 应用场景
SeqVLA技术可广泛应用于自动化装配、物流分拣、医疗手术机器人等领域。通过提升机器人对复杂任务的自主执行能力,降低人工干预需求,提高生产效率和操作安全性。未来,该技术有望推动机器人更广泛地应用于各行各业,实现更智能化的自动化生产。
📄 摘要(原文)
Long-horizon robotic manipulation tasks require executing multiple interdependent subtasks in strict sequence, where errors in detecting subtask completion can cascade into downstream failures. Existing Vision-Language-Action (VLA) models such as $π_0$ excel at continuous low-level control but lack an internal signal for identifying when a subtask has finished, making them brittle in sequential settings. We propose SeqVLA, a completion-aware extension of $π_0$ that augments the base architecture with a lightweight detection head perceiving whether the current subtask is complete. This dual-head design enables SeqVLA not only to generate manipulation actions but also to autonomously trigger transitions between subtasks. We investigate four finetuning strategies that vary in how the action and detection heads are optimized (joint vs. sequential finetuning) and how pretrained knowledge is preserved (full finetuning vs. frozen backbone). Experiments are performed on two multi-stage tasks: salad packing with seven distinct subtasks and candy packing with four distinct subtasks. Results show that SeqVLA significantly outperforms the baseline $π_0$ and other strong baselines in overall success rate. In particular, joint finetuning with an unfrozen backbone yields the most decisive and statistically reliable completion predictions, eliminating sequence-related failures and enabling robust long-horizon execution. Our results highlight the importance of coupling action generation with subtask-aware detection for scalable sequential manipulation.