GeoAware-VLA: Implicit Geometry Aware Vision-Language-Action Model
作者: Ali Abouzeid, Malak Mansour, Zezhou Sun, Dezhen Song
分类: cs.RO
发布日期: 2025-09-17 (更新: 2025-11-07)
备注: Under Review, Project Page https://alisharey.github.io/GeoAware-VLA/
💡 一句话要点
GeoAware-VLA:利用几何先验提升VLA模型视角泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 几何先验 视角泛化 机器人控制 零样本学习
📋 核心要点
- VLA模型在处理不同视角下的任务时面临挑战,因为它们难以从2D图像中准确推断3D几何信息。
- GeoAware-VLA通过利用预训练的几何视觉模型提取几何特征,并将其融入VLA模型,从而增强视角不变性。
- 实验表明,GeoAware-VLA在模拟和真实机器人环境中均显著提升了零样本泛化能力,成功率提高超过2倍。
📝 摘要(中文)
视觉-语言-动作(VLA)模型常常难以泛化到新的相机视角,这源于它们难以从2D图像中推断出鲁棒的3D几何信息。我们提出了GeoAware-VLA,一种简单而有效的方法,通过将强几何先验集成到视觉骨干网络中来增强视角不变性。我们没有训练视觉编码器或依赖显式的3D数据,而是利用一个冻结的、预训练的几何视觉模型作为特征提取器。然后,一个可训练的投影层调整这些富含几何信息的特征,以供策略解码器使用,从而减轻了从头开始学习3D一致性的负担。通过在LIBERO基准子集上的大量评估,我们表明GeoAware-VLA在零样本泛化到新的相机姿态方面取得了显著的改进,在模拟中将成功率提高了2倍以上。至关重要的是,这些优势转化为物理世界;我们的模型在真实机器人上表现出显著的性能提升,尤其是在从未见过的相机角度进行评估时。我们的方法在连续和离散动作空间中都证明是有效的,突出了鲁棒的几何基础是创建更具泛化能力的机器人代理的关键组成部分。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在面对新的相机视角时,泛化能力较差。这是因为这些模型难以从2D图像中学习到鲁棒的3D几何信息,导致在不同视角下对环境的理解不一致。现有方法通常需要从头训练视觉编码器,或者依赖显式的3D数据,计算成本高昂且效果有限。
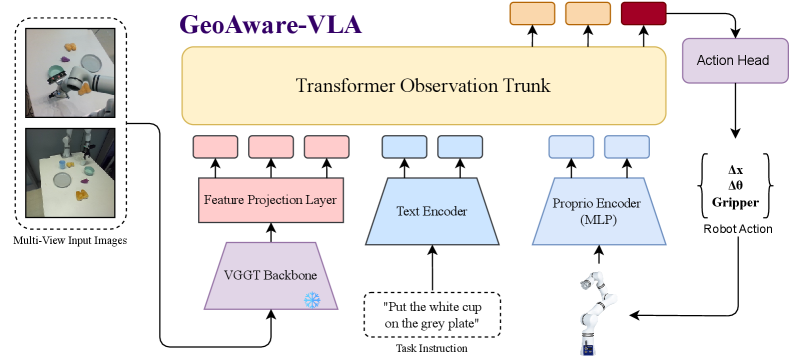
核心思路:GeoAware-VLA的核心思路是利用预训练的几何视觉模型来提取图像中的几何特征,并将这些特征融入到VLA模型中。这样可以有效地将几何先验知识引入模型,从而增强模型对不同视角的鲁棒性。通过冻结预训练的几何视觉模型,可以避免从头训练的成本,并利用已有的几何知识。
技术框架:GeoAware-VLA的整体框架包括三个主要模块:一个冻结的预训练几何视觉模型、一个可训练的投影层和一个策略解码器。首先,输入图像通过预训练的几何视觉模型提取几何特征。然后,这些特征通过一个可训练的投影层进行调整,使其适应策略解码器的输入格式。最后,策略解码器根据调整后的几何特征生成动作指令。
关键创新:GeoAware-VLA的关键创新在于利用预训练的几何视觉模型作为特征提取器,从而将几何先验知识融入到VLA模型中。与现有方法相比,GeoAware-VLA不需要从头训练视觉编码器,也不需要依赖显式的3D数据,从而降低了计算成本,并提高了模型的泛化能力。此外,可训练的投影层能够有效地将几何特征与策略解码器进行适配。
关键设计:GeoAware-VLA的关键设计包括选择合适的预训练几何视觉模型(具体模型未知),以及设计有效的投影层。投影层可以使用简单的线性层或更复杂的神经网络结构。损失函数的设计需要考虑动作空间的类型(连续或离散),并选择合适的损失函数进行优化。具体的参数设置和网络结构细节在论文中可能没有详细描述,需要参考相关代码或补充材料。
🖼️ 关键图片

📊 实验亮点
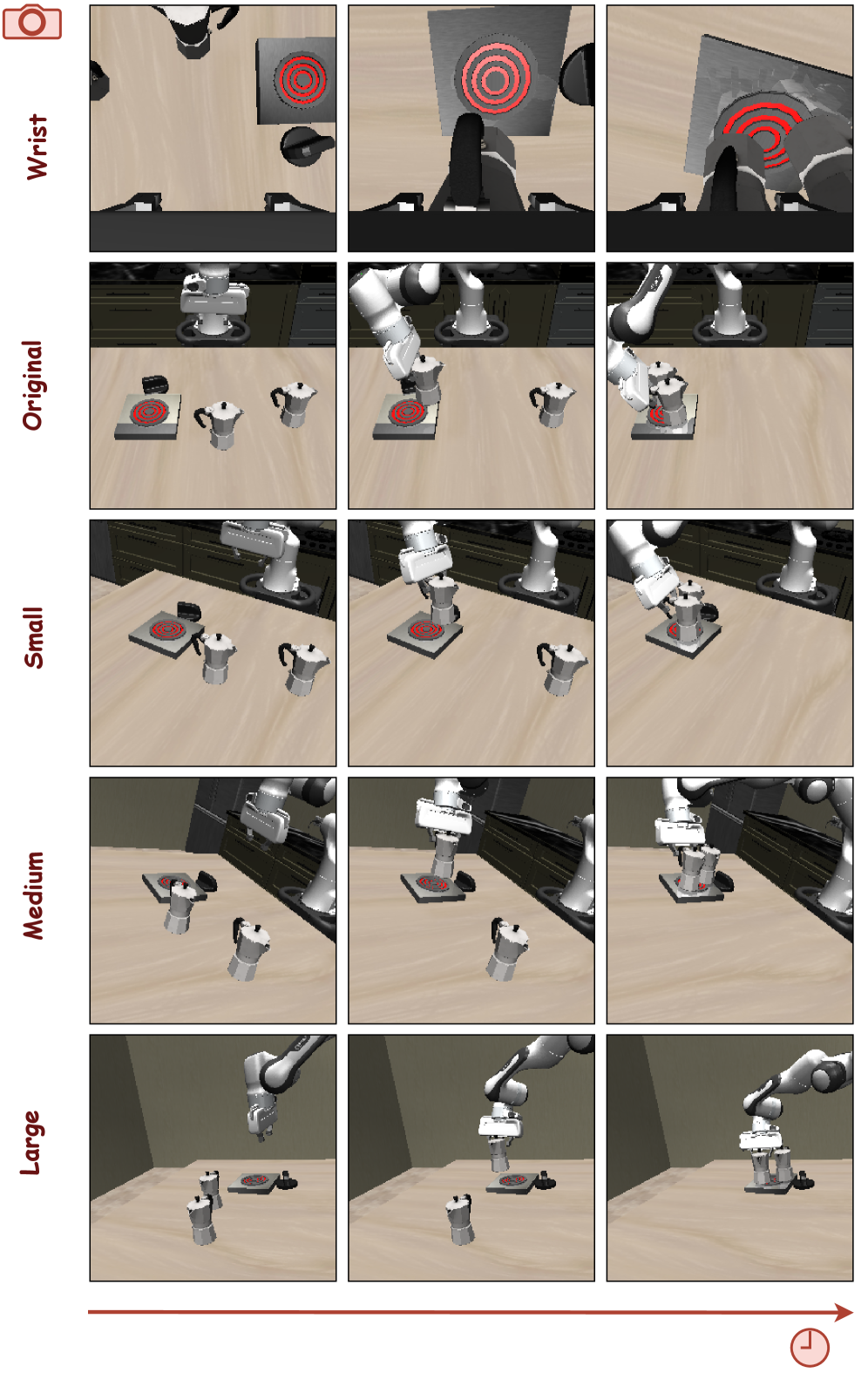
GeoAware-VLA在LIBERO基准测试中表现出色,在零样本泛化到新的相机姿态方面取得了显著的改进,在模拟环境中成功率提高了2倍以上。更重要的是,这些优势成功迁移到了真实机器人环境中,尤其是在从未见过的相机角度下,性能提升显著。这表明GeoAware-VLA具有很强的实用价值。
🎯 应用场景
GeoAware-VLA具有广泛的应用前景,例如机器人导航、自动驾驶、增强现实等领域。该模型可以帮助机器人在不同的视角下更好地理解环境,从而实现更鲁棒的控制和决策。此外,该模型还可以应用于虚拟现实环境中,增强用户在不同视角下的沉浸感。
📄 摘要(原文)
Vision-Language-Action (VLA) models often fail to generalize to novel camera viewpoints, a limitation stemming from their difficulty in inferring robust 3D geometry from 2D images. We introduce GeoAware-VLA, a simple yet effective approach that enhances viewpoint invariance by integrating strong geometric priors into the vision backbone. Instead of training a visual encoder or relying on explicit 3D data, we leverage a frozen, pretrained geometric vision model as a feature extractor. A trainable projection layer then adapts these geometrically-rich features for the policy decoder, relieving it of the burden of learning 3D consistency from scratch. Through extensive evaluations on LIBERO benchmark subsets, we show GeoAware-VLA achieves substantial improvements in zero-shot generalization to novel camera poses, boosting success rates by over 2x in simulation. Crucially, these benefits translate to the physical world; our model shows a significant performance gain on a real robot, especially when evaluated from unseen camera angles. Our approach proves effective across both continuous and discrete action spaces, highlighting that robust geometric grounding is a key component for creating more generalizable robotic agents.