FlightDiffusion: Revolutionising Autonomous Drone Training with Diffusion Models Generating FPV Video
作者: Valerii Serpiva, Artem Lykov, Faryal Batool, Vladislav Kozlovskiy, Miguel Altamirano Cabrera, Dzmitry Tsetserukou
分类: cs.RO
发布日期: 2025-09-17 (更新: 2025-09-19)
备注: Submitted to conference
💡 一句话要点
FlightDiffusion:利用扩散模型生成FPV视频,革新无人机自主训练
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 无人机自主导航 扩散模型 第一人称视角 数据生成 Sim-to-Real 策略学习 空中机器人
📋 核心要点
- 现有无人机自主导航训练依赖大量真实数据,成本高昂且难以覆盖所有场景。
- FlightDiffusion利用扩散模型从单帧生成逼真FPV视频,并合成多样化轨迹和状态-动作对。
- 实验表明,生成轨迹物理合理且可执行,实现了优秀的sim-to-real迁移,提升了导航性能。
📝 摘要(中文)
本文提出FlightDiffusion,一个基于扩散模型的框架,用于从第一人称视角(FPV)视频训练自主无人机。该模型从单帧生成逼真的视频序列,并丰富了相应的动作空间,从而能够在动态环境中进行基于推理的导航。除了直接策略学习,FlightDiffusion还利用其生成能力来合成多样化的FPV轨迹和状态-动作对,从而促进大规模训练数据集的创建,而无需高昂的真实世界数据收集成本。评估表明,生成的轨迹在物理上是合理的且可执行的,平均位置误差为0.25米(RMSE 0.28米),平均方向误差为0.19弧度(RMSE 0.24弧度)。这种方法能够改进策略学习和数据集可扩展性,从而在下游导航任务中实现卓越的性能。在模拟环境中的结果突出了增强的鲁棒性、更平滑的轨迹规划以及对未见条件的适应性。方差分析显示,模拟和现实之间的性能没有统计学上的显著差异(F(1, 16) = 0.394, p = 0.541),成功率分别为M = 0.628(SD = 0.162)和M = 0.617(SD = 0.177),表明强大的sim-to-real迁移能力。生成的数据集为未来的无人机研究提供了宝贵的资源。这项工作引入了基于扩散的推理,作为统一空中机器人导航、动作生成和数据合成的一种有前途的范例。
🔬 方法详解
问题定义:无人机自主导航的训练通常需要大量的真实世界数据,这不仅成本高昂,而且难以覆盖各种复杂和动态的环境。现有的方法在数据收集、标注和泛化能力方面存在局限性,阻碍了无人机在实际应用中的部署。
核心思路:FlightDiffusion的核心思路是利用扩散模型强大的生成能力,从单张FPV图像生成连续的、逼真的视频序列,并同时生成对应的动作空间。通过这种方式,可以有效地扩充训练数据集,降低对真实世界数据的依赖,并提高无人机在未知环境中的泛化能力。
技术框架:FlightDiffusion框架主要包含以下几个模块:1) 扩散模型:用于生成逼真的FPV视频序列;2) 动作空间生成器:用于生成与视频序列相对应的动作空间;3) 策略学习模块:利用生成的数据集训练无人机的导航策略。整体流程是从单帧图像开始,通过扩散模型生成视频序列,然后利用动作空间生成器生成对应的动作,最后将生成的数据用于训练无人机的导航策略。
关键创新:FlightDiffusion最重要的技术创新点在于将扩散模型应用于无人机自主导航的数据生成。与传统的基于GAN或VAE的方法相比,扩散模型能够生成更高质量、更多样化的视频序列,从而提高训练数据的质量和数量。此外,FlightDiffusion还能够同时生成与视频序列相对应的动作空间,从而实现端到端的训练。
关键设计:FlightDiffusion的关键设计包括:1) 扩散模型的选择和训练:选择合适的扩散模型结构,并使用大量的真实世界数据进行训练,以提高生成视频的逼真度;2) 动作空间的表示和生成:设计合适的动作空间表示方法,并利用神经网络学习从视频帧到动作的映射关系;3) 损失函数的设计:设计合适的损失函数,以鼓励生成的视频序列和动作空间与真实世界数据保持一致。
🖼️ 关键图片


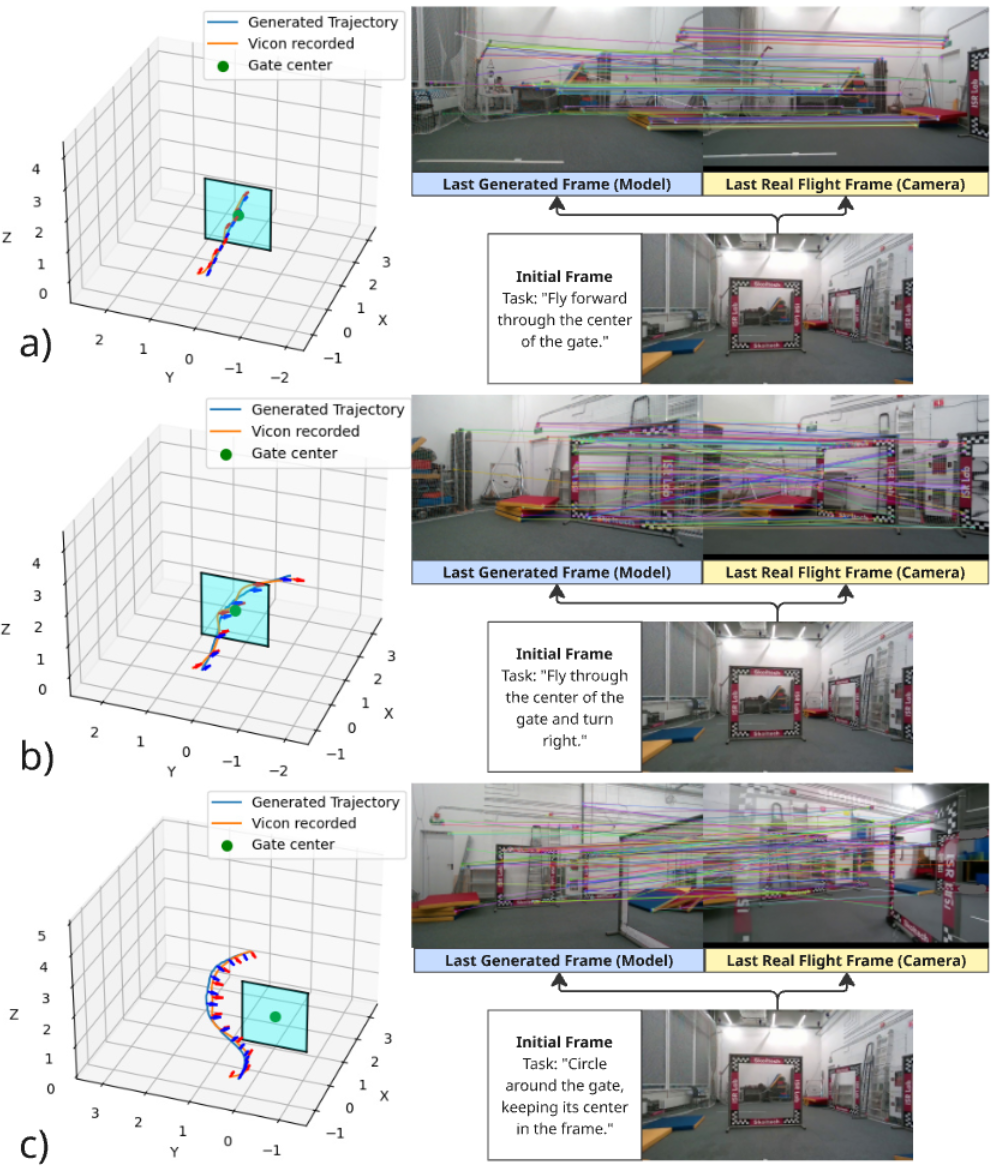
📊 实验亮点
实验结果表明,FlightDiffusion生成的轨迹在物理上是合理的且可执行的,平均位置误差为0.25米(RMSE 0.28米),平均方向误差为0.19弧度(RMSE 0.24弧度)。在模拟环境和真实环境中的性能没有显著差异(p=0.541),成功率分别为0.628和0.617,表明具有良好的sim-to-real迁移能力。相较于其他方法,FlightDiffusion能够生成更高质量、更多样化的训练数据,从而显著提高无人机在未知环境中的导航性能。
🎯 应用场景
FlightDiffusion具有广泛的应用前景,可用于无人机自主导航、智能交通、环境监测、灾害救援等领域。通过生成高质量的训练数据,可以降低无人机训练的成本和难度,提高无人机在复杂环境中的适应性和鲁棒性。此外,该方法还可以用于生成虚拟现实环境,为无人机操作员提供更逼真的训练体验。
📄 摘要(原文)
We present FlightDiffusion, a diffusion-model-based framework for training autonomous drones from first-person view (FPV) video. Our model generates realistic video sequences from a single frame, enriched with corresponding action spaces to enable reasoning-driven navigation in dynamic environments. Beyond direct policy learning, FlightDiffusion leverages its generative capabilities to synthesize diverse FPV trajectories and state-action pairs, facilitating the creation of large-scale training datasets without the high cost of real-world data collection. Our evaluation demonstrates that the generated trajectories are physically plausible and executable, with a mean position error of 0.25 m (RMSE 0.28 m) and a mean orientation error of 0.19 rad (RMSE 0.24 rad). This approach enables improved policy learning and dataset scalability, leading to superior performance in downstream navigation tasks. Results in simulated environments highlight enhanced robustness, smoother trajectory planning, and adaptability to unseen conditions. An ANOVA revealed no statistically significant difference between performance in simulation and reality (F(1, 16) = 0.394, p = 0.541), with success rates of M = 0.628 (SD = 0.162) and M = 0.617 (SD = 0.177), respectively, indicating strong sim-to-real transfer. The generated datasets provide a valuable resource for future UAV research. This work introduces diffusion-based reasoning as a promising paradigm for unifying navigation, action generation, and data synthesis in aerial robotics.