PhysicalAgent: Towards General Cognitive Robotics with Foundation World Models
作者: Artem Lykov, Jeffrin Sam, Hung Khang Nguyen, Vladislav Kozlovskiy, Yara Mahmoud, Valerii Serpiva, Miguel Altamirano Cabrera, Mikhail Konenkov, Dzmitry Tsetserukou
分类: cs.RO
发布日期: 2025-09-17
备注: submitted to IEEE conference
💡 一句话要点
PhysicalAgent:基于世界模型的通用认知机器人框架,实现迭代推理和闭环执行。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱六:视频提取与匹配 (Video Extraction)
关键词: 机器人操作 世界模型 视频生成 迭代推理 闭环控制
📋 核心要点
- 现有机器人操作方法泛化性差,难以应对复杂环境和任务中的执行错误,鲁棒性不足。
- PhysicalAgent通过生成视频演示、闭环执行和迭代重规划,使机器人能够从失败中恢复并完成任务。
- 实验表明,PhysicalAgent在多种机器人平台和感知模态下均优于现有方法,成功率显著提升。
📝 摘要(中文)
本文提出PhysicalAgent,一个用于机器人操作的代理框架,它集成了迭代推理、基于扩散的视频生成和闭环执行。给定文本指令,该方法生成候选轨迹的短视频演示,在机器人上执行这些轨迹,并迭代地重新规划以应对失败。这种方法能够从执行错误中稳健地恢复。我们在多种感知模态(自我中心、第三人称和模拟)和机器人平台(双臂UR3、Unitree G1人形机器人、模拟GR1)上评估PhysicalAgent,并与最先进的特定任务基线进行比较。实验表明,我们的方法始终优于先前的方法,在人类熟悉的任务中成功率高达83%。实际试验表明,首次尝试的成功率有限(20-30%),但迭代纠正将所有平台的总体成功率提高到80%。这些结果突出了基于视频的生成推理在通用机器人操作中的潜力,并强调了迭代执行对于从初始失败中恢复的重要性。我们的框架为可扩展、适应性强且鲁棒的机器人控制铺平了道路。
🔬 方法详解
问题定义:论文旨在解决机器人操作任务中,现有方法泛化能力不足、难以应对执行错误的问题。现有方法通常依赖于特定任务的训练数据,难以适应新的环境和任务,并且缺乏从错误中恢复的能力。
核心思路:论文的核心思路是利用世界模型进行视频生成,模拟机器人操作的候选轨迹,并通过闭环执行和迭代重规划,使机器人能够根据实际情况调整行动,从而提高任务成功率和鲁棒性。这种方法将规划和执行解耦,允许机器人从错误中学习和改进。
技术框架:PhysicalAgent框架包含以下主要模块:1) 文本指令输入;2) 基于扩散模型的视频生成器,用于生成候选轨迹的视频演示;3) 机器人执行器,用于在真实环境中执行生成的轨迹;4) 错误检测模块,用于识别执行过程中的错误;5) 迭代重规划模块,用于根据错误信息重新生成轨迹。整个流程是一个闭环系统,机器人不断尝试、评估和改进,直到成功完成任务。
关键创新:最重要的技术创新点在于将视频生成模型与机器人控制相结合,利用视频作为中间表示,实现了从文本指令到机器人动作的映射。这种方法允许机器人利用视觉信息进行推理和规划,提高了对环境变化的适应性。此外,迭代重规划机制使机器人能够从失败中学习,提高了鲁棒性。
关键设计:论文使用了基于扩散模型的视频生成器,该模型能够生成高质量、多样化的视频演示。在迭代重规划过程中,论文采用了一种基于策略梯度的方法,根据执行结果调整生成策略。具体的参数设置和网络结构细节在论文中进行了详细描述(此处省略,请参考原文)。
🖼️ 关键图片


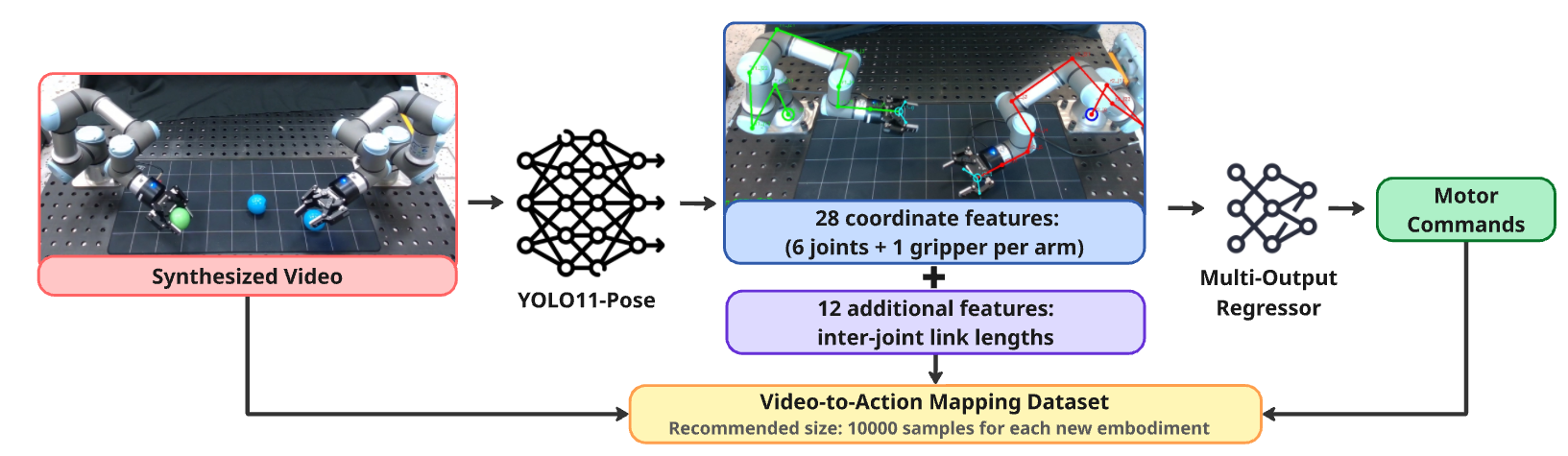
📊 实验亮点
实验结果表明,PhysicalAgent在多个机器人平台和感知模态下均取得了显著的性能提升。在人类熟悉的任务中,PhysicalAgent的成功率高达83%,远高于现有方法。实际试验表明,迭代纠正机制能够显著提高任务成功率,从首次尝试的20-30%提升到80%。
🎯 应用场景
PhysicalAgent具有广泛的应用前景,例如家庭服务机器人、工业自动化、医疗辅助机器人等。该框架可以使机器人更好地理解人类指令,适应复杂环境,并完成各种操作任务。通过不断学习和改进,机器人可以变得更加智能和可靠,从而为人类提供更好的服务。
📄 摘要(原文)
We introduce PhysicalAgent, an agentic framework for robotic manipulation that integrates iterative reasoning, diffusion-based video generation, and closed-loop execution. Given a textual instruction, our method generates short video demonstrations of candidate trajectories, executes them on the robot, and iteratively re-plans in response to failures. This approach enables robust recovery from execution errors. We evaluate PhysicalAgent across multiple perceptual modalities (egocentric, third-person, and simulated) and robotic embodiments (bimanual UR3, Unitree G1 humanoid, simulated GR1), comparing against state-of-the-art task-specific baselines. Experiments demonstrate that our method consistently outperforms prior approaches, achieving up to 83% success on human-familiar tasks. Physical trials reveal that first-attempt success is limited (20-30%), yet iterative correction increases overall success to 80% across platforms. These results highlight the potential of video-based generative reasoning for general-purpose robotic manipulation and underscore the importance of iterative execution for recovering from initial failures. Our framework paves the way for scalable, adaptable, and robust robot control.