FSR-VLN: Fast and Slow Reasoning for Vision-Language Navigation with Hierarchical Multi-modal Scene Graph
作者: Xiaolin Zhou, Tingyang Xiao, Liu Liu, Yucheng Wang, Maiyue Chen, Xinrui Meng, Xinjie Wang, Wei Feng, Wei Sui, Zhizhong Su
分类: cs.RO
发布日期: 2025-09-17 (更新: 2025-11-25)
备注: Demo video are available at https://horizonrobotics.github.io/robot_lab/fsr-vln/
💡 一句话要点
提出FSR-VLN,结合分层多模态场景图与快慢推理,提升视觉语言导航性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 分层场景图 快慢推理 机器人导航 多模态融合
📋 核心要点
- 现有视觉语言导航方法在长距离空间推理方面存在局限性,导致成功率低和推理延迟高,尤其是在长距离导航任务中。
- FSR-VLN结合分层多模态场景图(HMSG)与快慢导航推理(FSR),实现从粗到细的渐进式目标检索与选择。
- 实验表明,FSR-VLN在多个数据集上达到SOTA性能,并显著降低响应时间,同时集成了人形机器人平台,支持自然语言交互。
📝 摘要(中文)
本文提出FSR-VLN,一种用于视觉语言导航的系统,它结合了分层多模态场景图(HMSG)与快慢导航推理(FSR)。HMSG提供了一种多模态地图表示,支持从粗粒度的房间级定位到细粒度的目标视图和对象识别的渐进式检索。基于HMSG,FSR首先执行快速匹配以高效地选择候选房间、视图和对象,然后应用VLM驱动的细化来进行最终目标选择。在由人形机器人收集的四个综合室内数据集上评估了FSR-VLN,数据集包含87条涵盖各种对象类别的指令。实验结果表明,FSR-VLN在所有数据集上都实现了最先进的性能,并通过仅在快速直觉失败时激活慢速推理,将tour视频的响应时间相比于基于VLM的方法减少了82%。此外,我们将FSR-VLN与Unitree-G1人形机器人上的语音交互、规划和控制模块集成,实现了自然语言交互和实时导航。
🔬 方法详解
问题定义:视觉语言导航(VLN)旨在让智能体根据自然语言指令在真实环境中导航。现有方法在长距离导航中面临挑战,主要痛点在于推理效率低,难以在复杂环境中快速定位目标,导致导航失败率高,响应时间长。
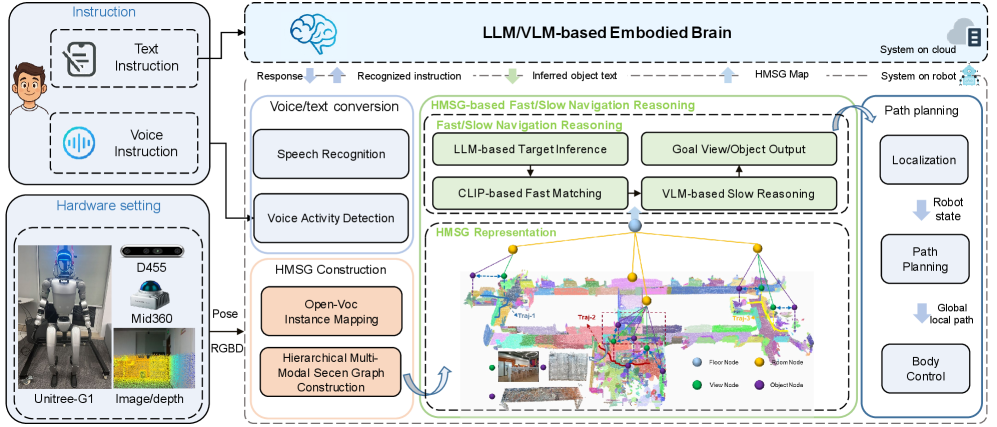
核心思路:FSR-VLN的核心思路是模拟人类的认知过程,采用“快慢推理”机制。首先通过快速匹配迅速缩小搜索范围,然后利用更精细的VLM推理进行目标确认。这种分层推理方式旨在提高效率,避免在不必要的区域进行耗时的计算。同时,使用分层多模态场景图(HMSG)来组织环境信息,支持快速检索。
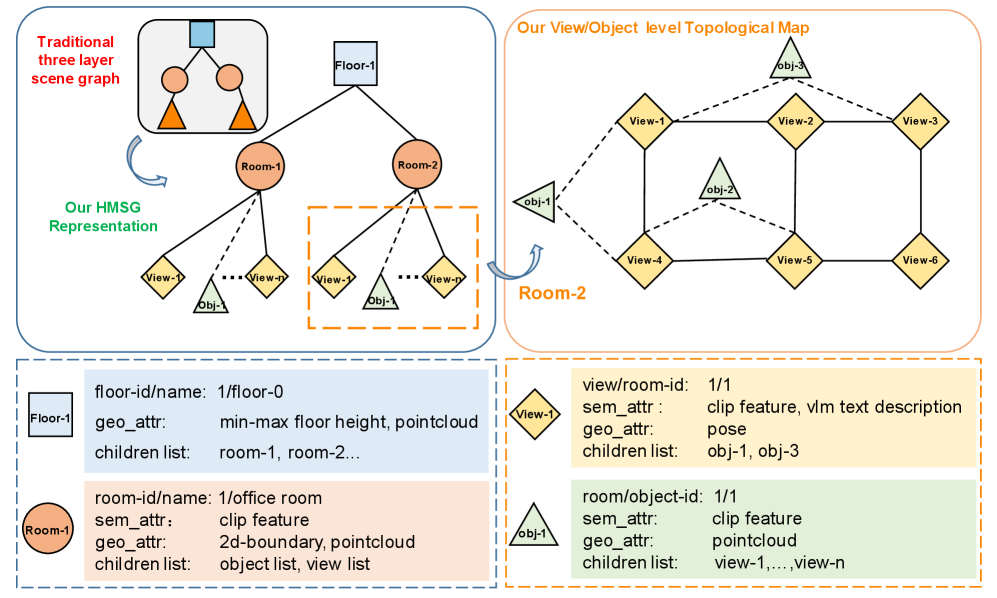
技术框架:FSR-VLN系统主要包含两个阶段:快速推理阶段和慢速推理阶段。快速推理阶段利用HMSG进行粗粒度的房间、视图和对象匹配,筛选出候选目标。慢速推理阶段则利用视觉语言模型(VLM)对候选目标进行细化,最终确定导航目标。HMSG包含房间层、视图层和对象层,每一层都包含多模态信息(视觉、语义)。
关键创新:该论文的关键创新在于结合了分层多模态场景图和快慢推理机制。HMSG提供了一种高效的环境表示,支持快速检索。快慢推理机制则通过分阶段的推理过程,在保证导航精度的同时,显著提高了推理效率。与现有方法相比,FSR-VLN能够更好地平衡导航精度和推理速度。
关键设计:HMSG的构建涉及对环境进行多模态信息的提取和组织。快慢推理的阈值设置需要根据具体任务进行调整,以平衡精度和效率。VLM的选择和微调也是关键,需要选择适合视觉语言导航任务的模型,并进行针对性的训练。损失函数的设计需要考虑导航的成功率和路径长度。
🖼️ 关键图片
📊 实验亮点
FSR-VLN在四个室内导航数据集上取得了SOTA性能,检索成功率(RSR)显著提升。更重要的是,FSR-VLN相比于基于VLM的方法,在tour视频上的响应时间减少了82%,表明其在推理效率方面具有显著优势。该系统成功集成到Unitree-G1人形机器人上,验证了其在真实环境中的可行性。
🎯 应用场景
FSR-VLN在机器人导航领域具有广泛的应用前景,可用于家庭服务机器人、仓储物流机器人、安防巡逻机器人等。该研究成果有助于提升机器人在复杂环境中的自主导航能力,实现更自然的人机交互,并为智能家居、智慧城市等领域的发展提供技术支持。
📄 摘要(原文)
Visual-Language Navigation (VLN) is a fundamental challenge in robotic systems, with broad applications for the deployment of embodied agents in real-world environments. Despite recent advances, existing approaches are limited in long-range spatial reasoning, often exhibiting low success rates and high inference latency, particularly in long-range navigation tasks. To address these limitations, we propose FSR-VLN, a vision-language navigation system that combines a Hierarchical Multi-modal Scene Graph (HMSG) with Fast-to-Slow Navigation Reasoning (FSR). The HMSG provides a multi-modal map representation supporting progressive retrieval, from coarse room-level localization to fine-grained goal view and object identification. Building on HMSG, FSR first performs fast matching to efficiently select candidate rooms, views, and objects, then applies VLM-driven refinement for final goal selection. We evaluated FSR-VLN across four comprehensive indoor datasets collected by humanoid robots, utilizing 87 instructions that encompass a diverse range of object categories. FSR-VLN achieves state-of-the-art (SOTA) performance in all datasets, measured by the retrieval success rate (RSR), while reducing the response time by 82% compared to VLM-based methods on tour videos by activating slow reasoning only when fast intuition fails. Furthermore, we integrate FSR-VLN with speech interaction, planning, and control modules on a Unitree-G1 humanoid robot, enabling natural language interaction and real-time navigation.