Dense-Jump Flow Matching with Non-Uniform Time Scheduling for Robotic Policies: Mitigating Multi-Step Inference Degradation
作者: Zidong Chen, Zihao Guo, Peng Wang, ThankGod Itua Egbe, Yan Lyu, Chenghao Qian
分类: cs.RO, cs.AI
发布日期: 2025-09-16
💡 一句话要点
提出Dense-Jump Flow Matching方法,通过非均匀时间调度优化机器人策略,缓解多步推理性能退化问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人策略学习 Flow Matching 非均匀时间调度 多步推理 泛化能力 机器人控制 轨迹生成
📋 核心要点
- 现有Flow Matching方法在机器人策略学习中存在泛化能力饱和和多步推理性能退化的问题。
- 提出Dense-Jump Flow Matching,通过非均匀时间调度训练和密集跳跃积分推理来解决上述问题。
- 实验表明,该方法在多个机器人任务中显著提升了策略性能,最高提升达23.7%。
📝 摘要(中文)
Flow Matching已成为学习高质量机器人生成策略的有效框架。然而,我们发现泛化能力沿轨迹快速饱和。此外,增加推理期间的欧拉积分步数反而会降低策略性能。我们将其归因于:(i)均匀间隔的积分步长过度采样了后期阶段,限制了动作并降低了泛化能力;(ii)学习到的速度场在积分时间接近1时变为非Lipschitz连续,导致不稳定。为了解决这些问题,我们提出了一种新策略,该策略在训练期间利用非均匀时间调度(例如,U形),强调早期和晚期阶段以正则化策略训练;并在推理时采用密集跳跃积分调度,使用单步积分代替跳跃点之后的多步积分,以避免1附近的不稳定区域。本质上,我们的策略是一种高效的单步学习器,仍然可以通过多步积分来提高性能,在各种机器人任务中,性能比最先进的基线提高了高达23.7%。
🔬 方法详解
问题定义:论文旨在解决Flow Matching在机器人策略学习中,随着推理过程中积分步数增加,策略性能反而下降的问题。现有方法采用均匀时间调度,导致后期阶段过度采样,限制了策略的泛化能力,并且速度场在接近积分终点时变得不稳定。
核心思路:论文的核心思路是通过非均匀时间调度来正则化训练过程,并采用密集跳跃积分策略来避免推理过程中的不稳定区域。具体来说,训练时采用U形时间调度,强调早期和晚期阶段;推理时,在跳跃点之后使用单步积分,避免速度场不稳定区域。
技术框架:整体框架包括两个主要部分:1) 使用非均匀时间调度进行Flow Matching策略训练;2) 使用Dense-Jump积分策略进行推理。训练阶段,通过调整时间步的采样密度,使模型更好地学习整个轨迹上的速度场。推理阶段,在轨迹的早期使用多步积分,在接近终点时切换到单步积分,以避免不稳定。
关键创新:论文的关键创新在于提出了Dense-Jump积分策略,它结合了多步积分的优势和单步积分的稳定性。通过在推理过程中动态调整积分步长,避免了对后期阶段的过度采样,并绕过了速度场的不稳定区域。
关键设计:非均匀时间调度采用U形分布,在轨迹的起始和结束阶段增加采样密度。跳跃点的位置是一个关键参数,需要根据具体任务进行调整,以平衡性能和稳定性。损失函数采用标准的Flow Matching损失函数,但加入了对时间调度的权重,以更好地正则化训练过程。
🖼️ 关键图片
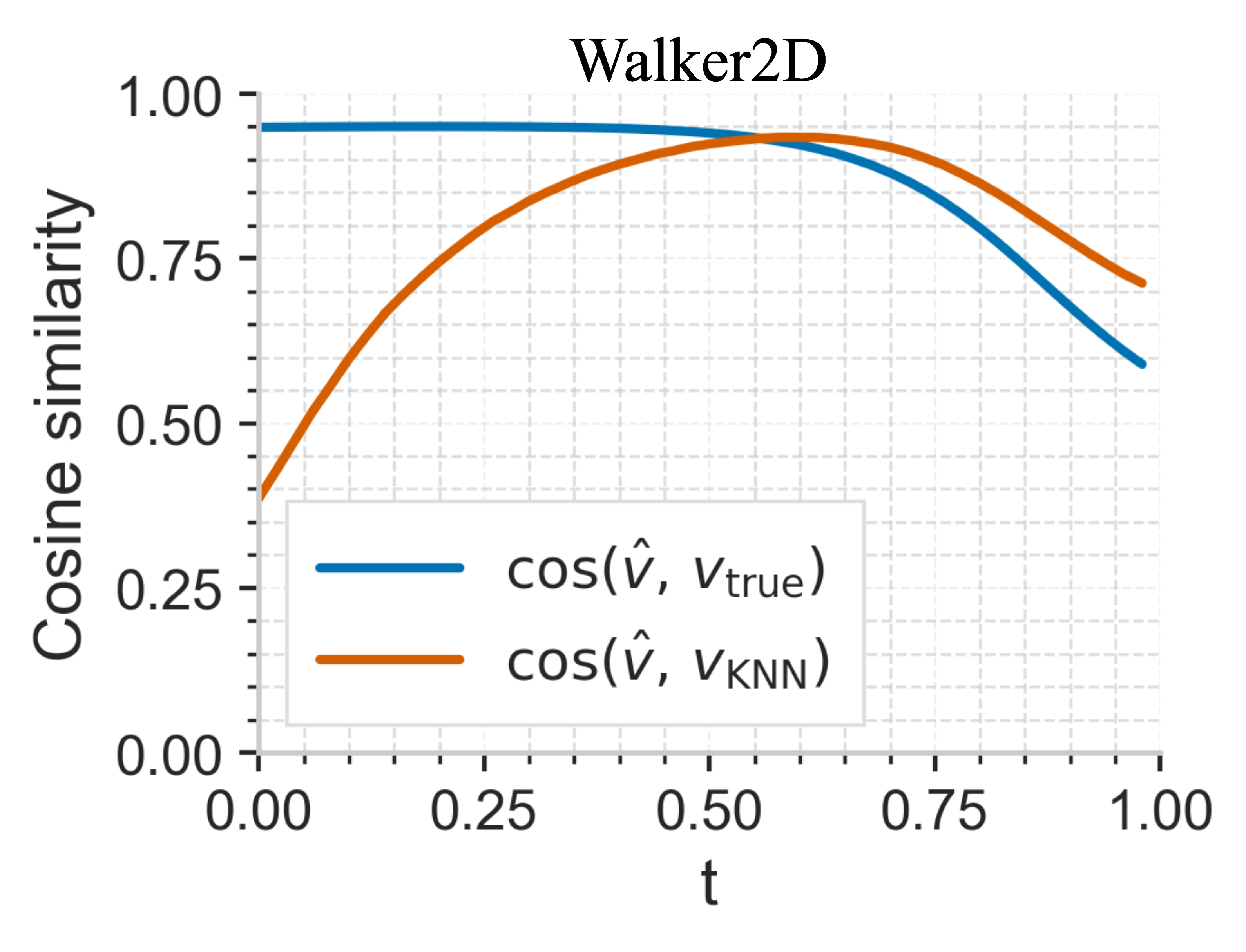

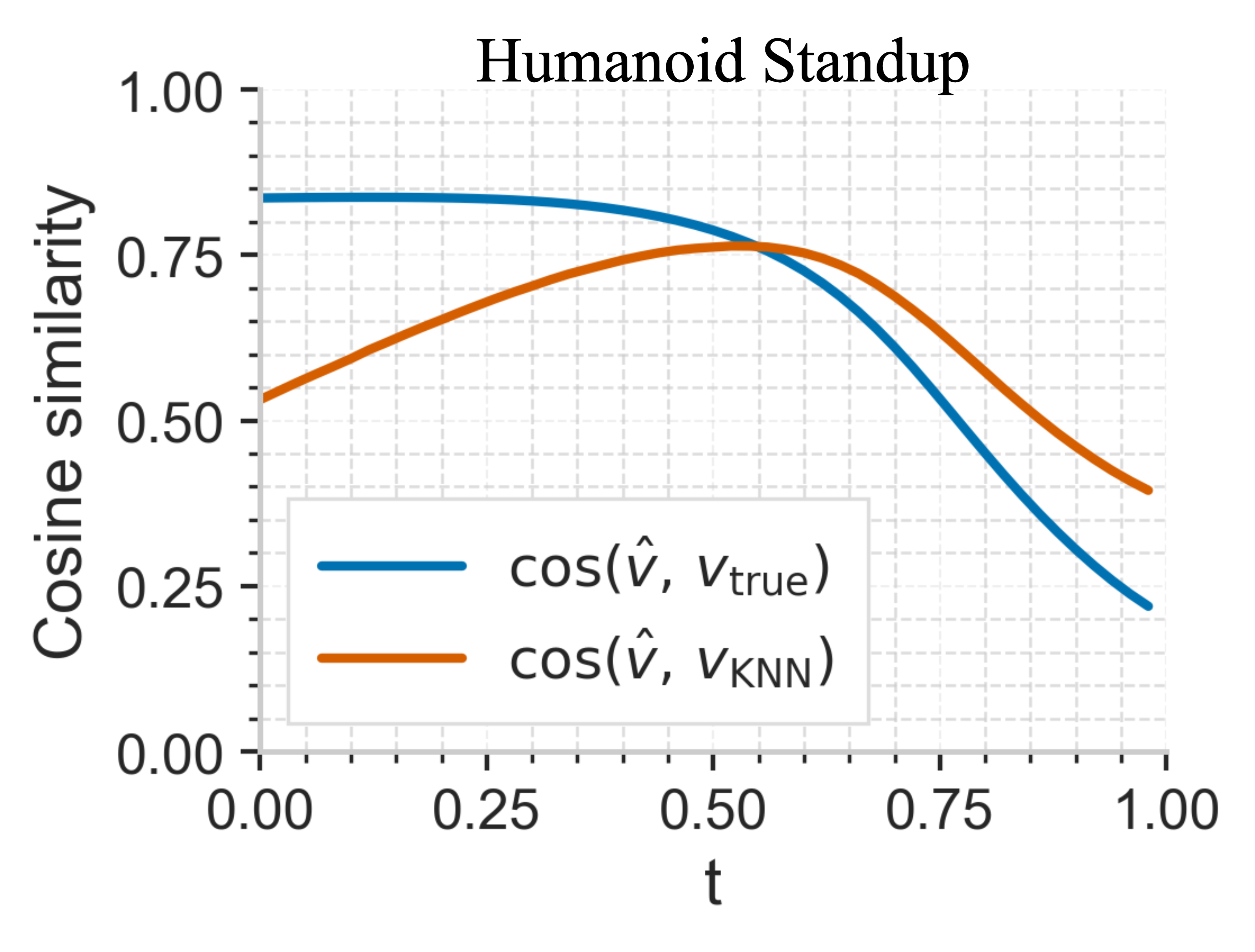
📊 实验亮点
实验结果表明,Dense-Jump Flow Matching在多个机器人任务中显著优于现有基线方法。例如,在某项机械臂控制任务中,该方法相比于最先进的Flow Matching方法,性能提升了23.7%。实验还验证了非均匀时间调度和密集跳跃积分策略的有效性。
🎯 应用场景
该研究成果可应用于各种机器人控制任务,例如机械臂运动规划、无人机导航和自动驾驶等。通过提高机器人策略的泛化能力和稳定性,可以使机器人在复杂和动态环境中更好地完成任务。该方法还有潜力应用于其他生成模型领域,例如图像生成和语音合成。
📄 摘要(原文)
Flow matching has emerged as a competitive framework for learning high-quality generative policies in robotics; however, we find that generalisation arises and saturates early along the flow trajectory, in accordance with recent findings in the literature. We further observe that increasing the number of Euler integration steps during inference counter-intuitively and universally degrades policy performance. We attribute this to (i) additional, uniformly spaced integration steps oversample the late-time region, thereby constraining actions towards the training trajectories and reducing generalisation; and (ii) the learned velocity field becoming non-Lipschitz as integration time approaches 1, causing instability. To address these issues, we propose a novel policy that utilises non-uniform time scheduling (e.g., U-shaped) during training, which emphasises both early and late temporal stages to regularise policy training, and a dense-jump integration schedule at inference, which uses a single-step integration to replace the multi-step integration beyond a jump point, to avoid unstable areas around 1. Essentially, our policy is an efficient one-step learner that still pushes forward performance through multi-step integration, yielding up to 23.7% performance gains over state-of-the-art baselines across diverse robotic tasks.