GRATE: a Graph transformer-based deep Reinforcement learning Approach for Time-efficient autonomous robot Exploration
作者: Haozhan Ni, Jingsong Liang, Chenyu He, Yuhong Cao, Guillaume Sartoretti
分类: cs.RO
发布日期: 2025-09-16
💡 一句话要点
提出GRATE,一种基于图Transformer的深度强化学习方法,用于提升机器人自主探索的时间效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自主机器人探索 深度强化学习 图Transformer 时间效率优化 卡尔曼滤波
📋 核心要点
- 现有基于强化学习的自主探索方法在图结构数据上的推理能力有限,且通常只关注距离优化,忽略了时间效率。
- GRATE利用图Transformer捕获信息图的局部结构和全局依赖,增强了模型在整个环境中的推理能力,并使用卡尔曼滤波平滑路径。
- 实验结果表明,GRATE在探索效率上优于现有方法,距离上提升高达21.5%,时间上提升高达21.3%,并在真实场景中得到验证。
📝 摘要(中文)
自主机器人探索(ARE)是指机器人自主导航并绘制未知环境地图的过程。最近基于强化学习(RL)的方法通常将ARE建模为在无碰撞信息图上定义的序列决策问题。然而,这些方法在图结构化数据上的推理能力有限。此外,由于对机器人运动的考虑不足,由此产生的RL策略通常被优化为最小化行驶距离,而忽略了时间效率。为了克服这些限制,我们提出GRATE,一种基于深度强化学习(DRL)的方法,它利用图Transformer来有效地捕获信息图的局部结构模式和全局上下文依赖关系,从而增强模型在整个环境中的推理能力。此外,我们部署卡尔曼滤波器来平滑航点输出,确保生成的路径在运动学上是机器人可以遵循的。实验结果表明,在各种模拟基准中,我们的方法比最先进的传统和基于学习的基线表现出更好的探索效率(在完成探索的距离上高达21.5%,时间上高达21.3%)。我们还在真实场景中验证了我们的规划器。
🔬 方法详解
问题定义:论文旨在解决自主机器人探索(ARE)中现有强化学习方法推理能力不足和时间效率低下的问题。现有方法通常将ARE建模为在信息图上的序列决策问题,但它们在处理图结构数据时缺乏有效的推理能力,并且通常只关注最小化行驶距离,而忽略了时间效率,导致探索时间较长。
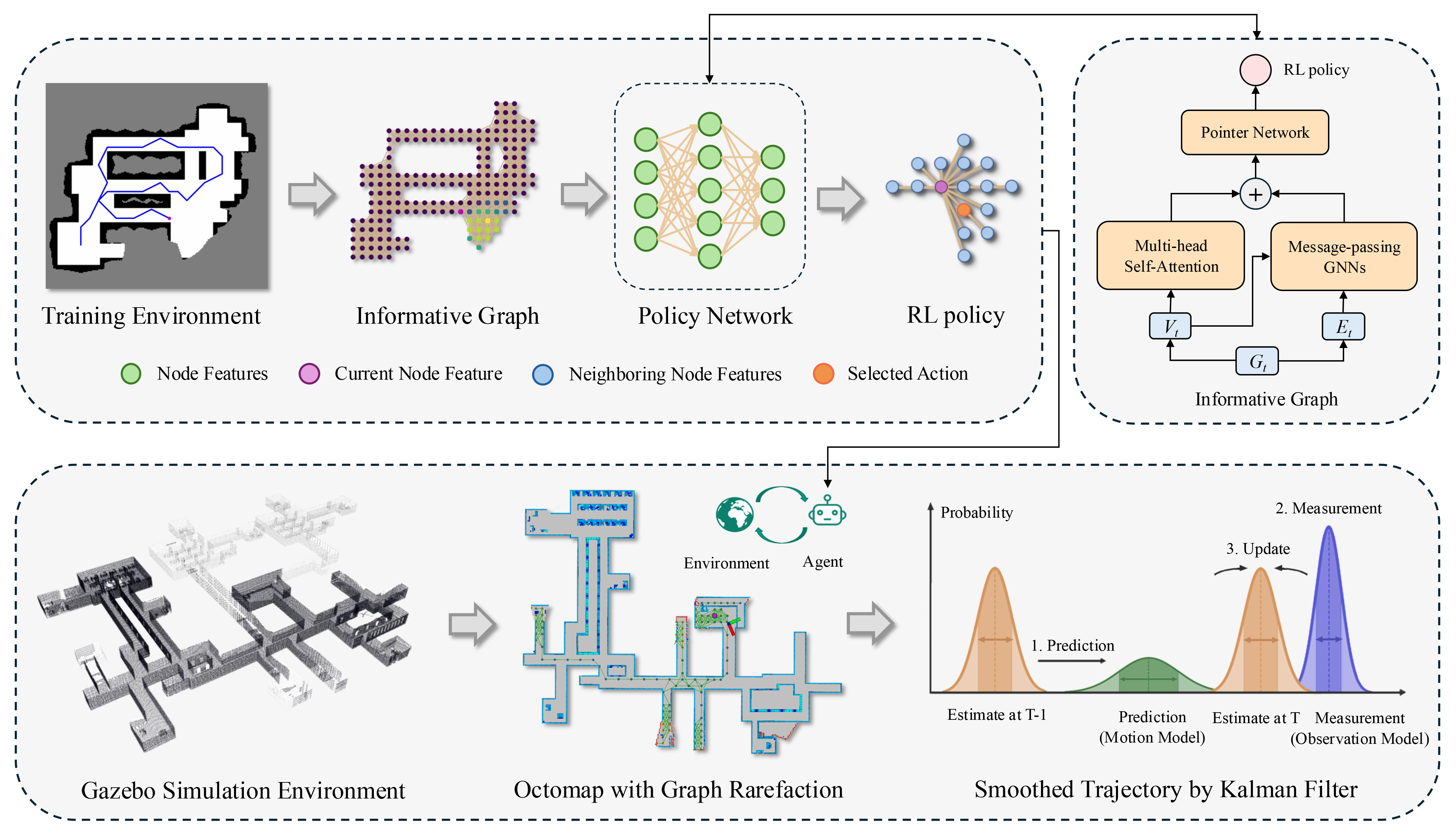
核心思路:论文的核心思路是利用图Transformer来增强模型对环境的理解和推理能力,同时结合卡尔曼滤波来优化路径规划,从而提高探索的时间效率。图Transformer能够有效地捕获信息图的局部结构模式和全局上下文依赖关系,使机器人能够更好地理解整个环境。卡尔曼滤波则用于平滑航点输出,确保生成的路径在运动学上可行,从而减少不必要的运动和时间浪费。
技术框架:GRATE的整体框架包括以下几个主要模块:1) 信息图构建模块:用于构建表示环境的无碰撞信息图。2) 图Transformer模块:用于处理信息图,提取环境的特征表示。3) 强化学习策略网络:基于图Transformer的输出,学习探索策略。4) 卡尔曼滤波模块:用于平滑策略网络输出的航点,生成可执行的机器人运动轨迹。整个流程是,首先构建环境的信息图,然后使用图Transformer提取图特征,接着通过强化学习策略网络选择下一个探索目标点,最后使用卡尔曼滤波平滑路径,控制机器人运动。
关键创新:GRATE的关键创新在于将图Transformer引入到自主机器人探索的强化学习框架中。与传统的图神经网络相比,图Transformer能够更好地捕获图的全局依赖关系,从而提高模型对环境的理解和推理能力。此外,结合卡尔曼滤波进行路径平滑也是一个创新点,它确保了生成的路径在运动学上可行,从而提高了探索的时间效率。
关键设计:在图Transformer的设计上,论文可能采用了多头注意力机制来捕获不同类型的图结构信息。在强化学习方面,可能使用了Actor-Critic算法来训练策略网络。损失函数的设计可能包括探索奖励、时间惩罚等,以鼓励机器人快速有效地探索环境。卡尔曼滤波器的参数设置需要根据机器人的运动学特性进行调整,以获得最佳的路径平滑效果。
🖼️ 关键图片


📊 实验亮点
实验结果表明,GRATE在各种模拟基准中都优于现有的方法。具体来说,GRATE在完成探索的距离上提升高达21.5%,在时间上提升高达21.3%。此外,该方法还在真实场景中进行了验证,证明了其在实际应用中的可行性。这些结果表明,GRATE是一种高效且实用的自主机器人探索方法。
🎯 应用场景
该研究成果可应用于各种需要自主探索的场景,例如:灾难救援、未知环境测绘、仓库巡检、自动驾驶等。通过提高机器人自主探索的效率,可以更快地获取环境信息,从而为后续的任务执行提供更好的支持。未来,该方法可以进一步扩展到多机器人协同探索,以提高探索效率和鲁棒性。
📄 摘要(原文)
Autonomous robot exploration (ARE) is the process of a robot autonomously navigating and mapping an unknown environment. Recent Reinforcement Learning (RL)-based approaches typically formulate ARE as a sequential decision-making problem defined on a collision-free informative graph. However, these methods often demonstrate limited reasoning ability over graph-structured data. Moreover, due to the insufficient consideration of robot motion, the resulting RL policies are generally optimized to minimize travel distance, while neglecting time efficiency. To overcome these limitations, we propose GRATE, a Deep Reinforcement Learning (DRL)-based approach that leverages a Graph Transformer to effectively capture both local structure patterns and global contextual dependencies of the informative graph, thereby enhancing the model's reasoning capability across the entire environment. In addition, we deploy a Kalman filter to smooth the waypoint outputs, ensuring that the resulting path is kinodynamically feasible for the robot to follow. Experimental results demonstrate that our method exhibits better exploration efficiency (up to 21.5% in distance and 21.3% in time to complete exploration) than state-of-the-art conventional and learning-based baselines in various simulation benchmarks. We also validate our planner in real-world scenarios.