Contrastive Representation Learning for Robust Sim-to-Real Transfer of Adaptive Humanoid Locomotion
作者: Yidan Lu, Rurui Yang, Qiran Kou, Mengting Chen, Tao Fan, Peter Cui, Yinzhao Dong, Peng Lu
分类: cs.RO
发布日期: 2025-09-16
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出对比学习框架,提升类人机器人适应性运动的Sim-to-Real迁移鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 类人机器人 强化学习 Sim-to-Real 对比学习 运动控制
📋 核心要点
- 现有类人机器人运动策略需要在鲁棒的反应式控制和脆弱的主动感知之间权衡,限制了实际部署。
- 论文提出对比学习框架,将模拟环境中的特权信息提炼到本体感受策略的潜在状态中,赋予其主动性。
- 实验证明,该方法实现了零样本Sim-to-Real迁移,在复杂地形上表现出高度鲁棒的运动能力。
📝 摘要(中文)
本文提出了一种新范式,旨在解决类人机器人运动中反应式本体感受控制的鲁棒性与复杂感知驱动系统的主动性之间的根本矛盾。该方法通过对比学习框架,使纯本体感受策略具备主动能力,在不增加部署时成本的前提下,获得类似感知的前瞻性。核心思想是利用对比学习,强制执行动作者的潜在状态来编码来自模拟环境的特权信息,即“提炼的感知”。这种感知能力赋予自适应步态时钟,使策略能够根据对地形的推断理解主动调整其节奏。实验结果表明,该方法实现了零样本Sim-to-Real迁移,在全尺寸类人机器人上实现了对复杂地形(包括30厘米高的台阶和26.5°的斜坡)的高度鲁棒的运动。
🔬 方法详解
问题定义:类人机器人运动控制面临着鲁棒性和主动性的两难选择。依赖本体感受的反应式控制虽然鲁棒,但缺乏对环境的预判能力;而依赖复杂感知的控制策略虽然主动,但容易受到感知噪声的干扰,在真实环境中表现脆弱。现有方法难以兼顾两者的优点。
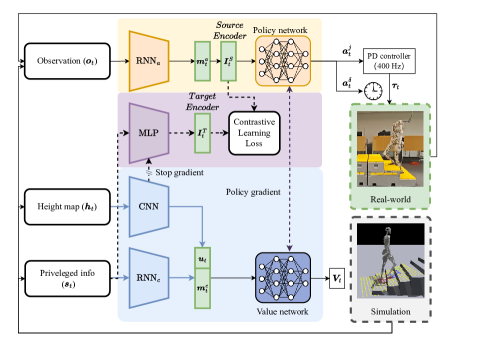
核心思路:论文的核心思路是通过对比学习,将模拟环境中的环境信息(例如地形高度)“提炼”到仅依赖本体感受的策略的潜在状态中。这样,策略就能在不依赖真实环境感知的情况下,获得对环境的“感知”,从而实现主动适应。
技术框架:整体框架包含一个在模拟环境中训练的强化学习策略。该策略仅使用本体感受信息作为输入,但同时可以访问环境的特权信息。通过对比学习,策略的潜在状态被训练成能够编码这些特权信息。具体来说,对于每个状态,策略的潜在状态需要能够区分不同的环境状态。训练完成后,该策略可以直接部署到真实机器人上,无需任何感知输入。
关键创新:最重要的创新点在于使用对比学习来桥接本体感受和环境感知之间的鸿沟。传统方法要么依赖直接的感知输入,要么完全忽略环境信息。而本文的方法通过对比学习,间接地将环境信息编码到策略的潜在状态中,从而实现了在没有显式感知的情况下进行主动控制。
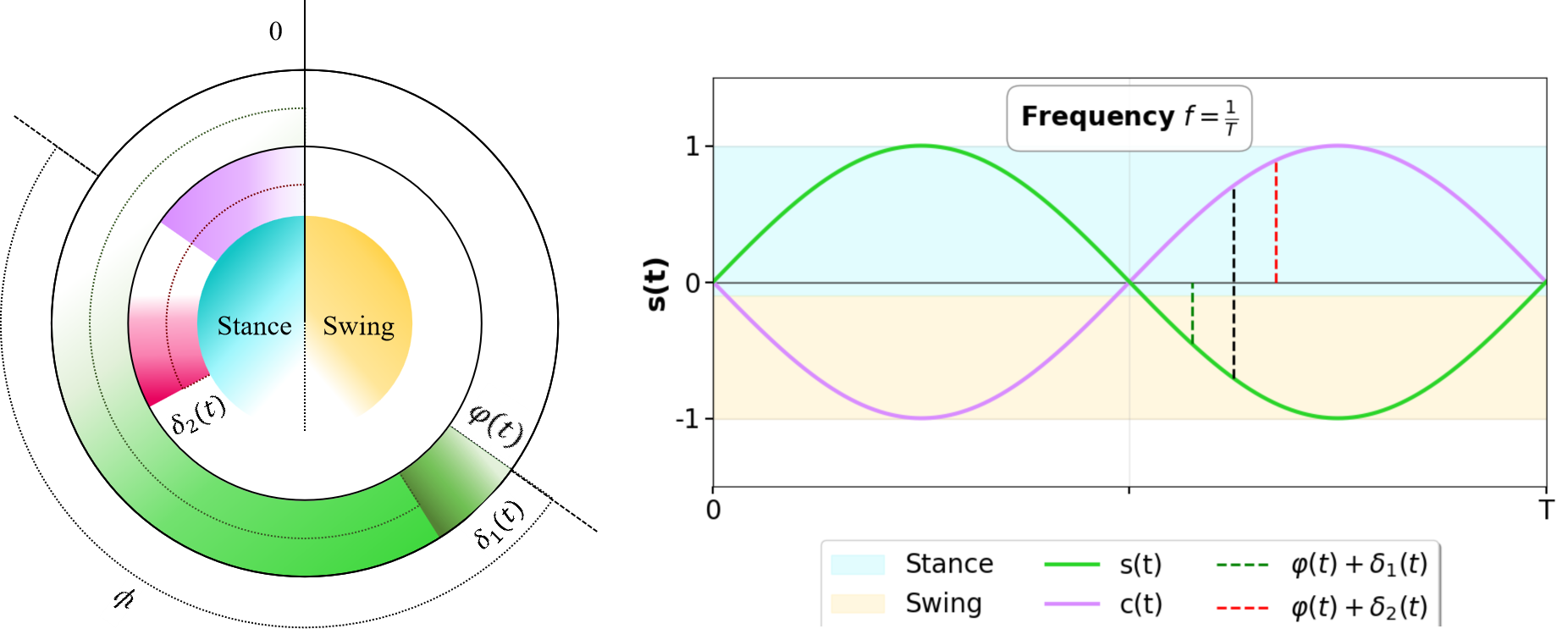
关键设计:关键设计包括:1) 使用对比损失函数来训练策略的潜在状态,使其能够区分不同的环境状态;2) 设计自适应步态时钟,根据策略对环境的“感知”来调整步态的节奏;3) 精心设计的奖励函数,鼓励策略学习鲁棒和高效的运动方式。具体的网络结构和参数设置在论文中有详细描述,但摘要中未明确给出。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法实现了零样本Sim-to-Real迁移,在全尺寸类人机器人上成功实现了对复杂地形(包括30厘米高的台阶和26.5°的斜坡)的高度鲁棒的运动。与传统的基于时钟的步态控制方法相比,该方法能够更好地适应不同的地形,并且不需要额外的感知输入。
🎯 应用场景
该研究成果可应用于各种需要在复杂或未知地形中进行运动的机器人,例如搜索救援机器人、建筑机器人和农业机器人。通过提高机器人的运动鲁棒性和适应性,可以使其在更广泛的实际场景中发挥作用,并降低部署和维护成本。未来,该方法可以扩展到其他类型的机器人和任务中,例如操作和导航。
📄 摘要(原文)
Reinforcement learning has produced remarkable advances in humanoid locomotion, yet a fundamental dilemma persists for real-world deployment: policies must choose between the robustness of reactive proprioceptive control or the proactivity of complex, fragile perception-driven systems. This paper resolves this dilemma by introducing a paradigm that imbues a purely proprioceptive policy with proactive capabilities, achieving the foresight of perception without its deployment-time costs. Our core contribution is a contrastive learning framework that compels the actor's latent state to encode privileged environmental information from simulation. Crucially, this ``distilled awareness" empowers an adaptive gait clock, allowing the policy to proactively adjust its rhythm based on an inferred understanding of the terrain. This synergy resolves the classic trade-off between rigid, clocked gaits and unstable clock-free policies. We validate our approach with zero-shot sim-to-real transfer to a full-sized humanoid, demonstrating highly robust locomotion over challenging terrains, including 30 cm high steps and 26.5° slopes, proving the effectiveness of our method. Website: https://lu-yidan.github.io/cra-loco.