ActiveVLN: Towards Active Exploration via Multi-Turn RL in Vision-and-Language Navigation
作者: Zekai Zhang, Weiye Zhu, Hewei Pan, Xiangchen Wang, Rongtao Xu, Xing Sun, Feng Zheng
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-09-16
💡 一句话要点
ActiveVLN:基于多轮强化学习的主动探索视觉语言导航
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 强化学习 主动探索 多轮交互 模仿学习
📋 核心要点
- 现有VLN方法依赖模仿学习和DAgger,成本高昂且缺乏与环境的动态交互,限制了智能体探索多样化路径的能力。
- ActiveVLN框架通过多轮强化学习实现主动探索,智能体迭代预测和执行动作,自动收集轨迹并优化,提升探索效率。
- 实验表明,ActiveVLN在IL基线上取得了显著的性能提升,并以更小的模型达到了与SOTA方法相当的水平。
📝 摘要(中文)
视觉语言导航(VLN)任务要求智能体根据自然语言指令在复杂环境中导航。现有的基于MLLM的VLN方法主要依赖于模仿学习(IL),并经常使用DAgger进行后训练以减轻协变量偏移。虽然有效,但这些方法会产生大量的数据收集和训练成本。强化学习(RL)提供了一种有希望的替代方案。然而,先前的VLN RL方法缺乏与环境的动态交互,并且依赖于专家轨迹进行奖励塑造,而不是进行开放式的主动探索。这限制了智能体发现多样化和合理的导航路线的能力。为了解决这些限制,我们提出了ActiveVLN,一个通过多轮RL显式地实现主动探索的VLN框架。在第一阶段,使用一小部分专家轨迹进行IL来引导智能体。在第二阶段,智能体迭代地预测和执行动作,自动收集多样化的轨迹,并通过GRPO目标优化多个rollout。为了进一步提高RL效率,我们引入了一种动态提前停止策略来修剪长尾或可能失败的轨迹,以及额外的工程优化。实验表明,与基于DAgger和先前的基于RL的后训练方法相比,ActiveVLN在IL基线上实现了最大的性能提升,同时在使用较小模型的情况下达到了与最先进方法相当的性能。代码和数据即将发布。
🔬 方法详解
问题定义:论文旨在解决视觉语言导航(VLN)中,现有方法依赖模仿学习(IL)和DAgger进行后训练,导致数据收集和训练成本高昂,且缺乏与环境的动态交互,限制了智能体探索多样化路径的问题。现有方法过度依赖专家轨迹,无法进行有效的自主探索。
核心思路:论文的核心思路是通过多轮强化学习(RL)实现主动探索。智能体不再仅仅模仿专家轨迹,而是通过与环境的交互,自主地发现和学习更有效的导航策略。通过迭代地预测和执行动作,收集多样化的轨迹,并利用强化学习算法进行优化,从而提高导航性能。
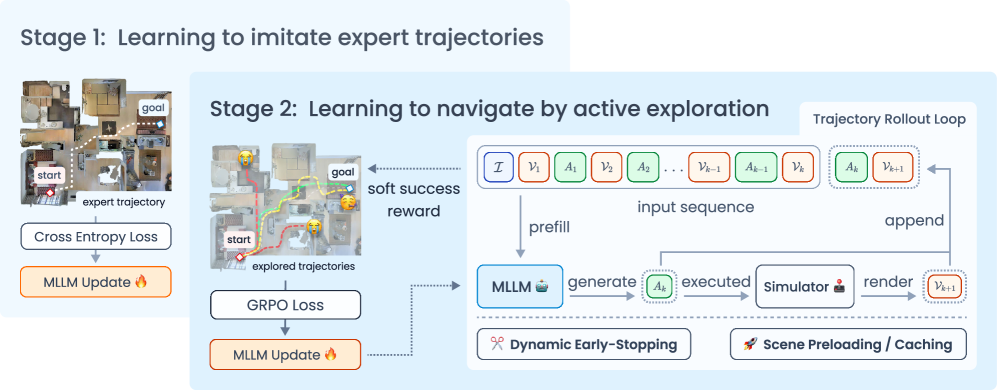
技术框架:ActiveVLN框架包含两个主要阶段:1) 模仿学习阶段:使用少量专家轨迹进行IL,用于初始化智能体,使其具备初步的导航能力。2) 强化学习阶段:智能体与环境进行多轮交互,迭代地预测和执行动作,收集轨迹。使用GRPO(Generalized Policy Optimization)目标函数优化多个rollout。同时,引入动态提前停止策略,剪枝可能失败的轨迹,提高RL效率。
关键创新:ActiveVLN的关键创新在于引入了主动探索机制,通过多轮强化学习使智能体能够自主地与环境交互,发现多样化的导航路径。与传统的依赖专家轨迹的VLN方法相比,ActiveVLN能够更好地适应复杂和未知的环境,并学习到更鲁棒的导航策略。动态提前停止策略也是一个重要的创新,它能够有效地提高RL的训练效率。
关键设计:在强化学习阶段,使用了GRPO目标函数来优化策略。动态提前停止策略根据轨迹的早期表现来预测其最终结果,并提前终止可能失败的轨迹。具体的提前停止阈值和策略需要根据实验进行调整。此外,论文还进行了额外的工程优化,以提高训练效率,但具体细节未在摘要中详细说明。
🖼️ 关键图片

📊 实验亮点
ActiveVLN在视觉语言导航任务中,相较于模仿学习基线,取得了显著的性能提升。与基于DAgger和先前的基于RL的后训练方法相比,ActiveVLN实现了更大的性能增益。更重要的是,ActiveVLN在使用较小模型的情况下,达到了与最先进方法相当的性能,表明其具有更高的效率和潜力。
🎯 应用场景
ActiveVLN的研究成果可应用于机器人导航、自动驾驶、虚拟现实等领域。例如,可以用于开发能够在复杂环境中自主导航的机器人,或者为视障人士提供导航辅助。该研究有助于提高智能体在未知环境中的适应性和导航能力,具有重要的实际应用价值和潜在的商业前景。
📄 摘要(原文)
The Vision-and-Language Navigation (VLN) task requires an agent to follow natural language instructions and navigate through complex environments. Existing MLLM-based VLN methods primarily rely on imitation learning (IL) and often use DAgger for post-training to mitigate covariate shift. While effective, these approaches incur substantial data collection and training costs. Reinforcement learning (RL) offers a promising alternative. However, prior VLN RL methods lack dynamic interaction with the environment and depend on expert trajectories for reward shaping, rather than engaging in open-ended active exploration. This restricts the agent's ability to discover diverse and plausible navigation routes. To address these limitations, we propose ActiveVLN, a VLN framework that explicitly enables active exploration through multi-turn RL. In the first stage, a small fraction of expert trajectories is used for IL to bootstrap the agent. In the second stage, the agent iteratively predicts and executes actions, automatically collects diverse trajectories, and optimizes multiple rollouts via the GRPO objective. To further improve RL efficiency, we introduce a dynamic early-stopping strategy to prune long-tail or likely failed trajectories, along with additional engineering optimizations. Experiments show that ActiveVLN achieves the largest performance gains over IL baselines compared to both DAgger-based and prior RL-based post-training methods, while reaching competitive performance with state-of-the-art approaches despite using a smaller model. Code and data will be released soon.