Robust Online Residual Refinement via Koopman-Guided Dynamics Modeling
作者: Zhefei Gong, Shangke Lyu, Pengxiang Ding, Wei Xiao, Donglin Wang
分类: cs.RO
发布日期: 2025-09-16
💡 一句话要点
提出KORR:利用Koopman引导的动态建模实现鲁棒的在线残差策略优化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 残差策略学习 Koopman算子 动态建模 机器人操作 长时程任务 鲁棒性 泛化能力
📋 核心要点
- 模仿学习在长时程任务中易受误差累积影响,现有残差策略学习方法缺乏全局状态理解,限制了鲁棒性。
- 论文提出KORR框架,利用Koopman算子学习线性动态模型,指导残差策略更新,实现全局感知的动作优化。
- 在机器人家具组装任务中,KORR相比基线方法,在性能、鲁棒性和泛化性上均有提升,验证了方法的有效性。
📝 摘要(中文)
模仿学习(IL)能够从演示中高效地学习技能,但由于误差累积,在长时程任务和高精度控制方面表现不佳。残差策略学习通过闭环校正来优化基础策略,提供了一种有前景且与模型无关的解决方案。然而,现有方法主要关注对基础策略的局部校正,缺乏对状态演化的全局理解,限制了鲁棒性和对未见场景的泛化能力。为了解决这个问题,我们提出结合全局动态建模来指导残差策略更新。具体来说,我们利用Koopman算子理论在学习到的潜在空间中施加线性时不变结构,从而实现可靠的状态转移,并改进长时程预测和对未见环境的外推能力。我们提出了KORR(Koopman引导的在线残差优化),这是一个简单而有效的框架,它根据Koopman预测的潜在状态来调节残差校正,从而实现全局知情和稳定的动作优化。我们在各种扰动下的长时程、精细机器人家具组装任务中评估了KORR。结果表明,与强大的基线相比,KORR在性能、鲁棒性和泛化能力方面均有持续提升。我们的发现进一步突出了基于Koopman的建模在连接现代学习方法与经典控制理论方面的潜力。
🔬 方法详解
问题定义:现有残差策略学习方法主要关注局部校正,缺乏对状态演化的全局理解,导致在长时程任务中误差累积,鲁棒性和泛化能力受限。尤其是在机器人操作等需要精细控制的任务中,这种问题更加突出。
核心思路:论文的核心思路是利用Koopman算子理论学习系统的全局动态模型,并在潜在空间中施加线性时不变结构。通过Koopman预测的潜在状态来调节残差校正,从而实现全局知情和稳定的动作优化。这种方法旨在弥补现有残差策略学习方法缺乏全局状态理解的缺陷。
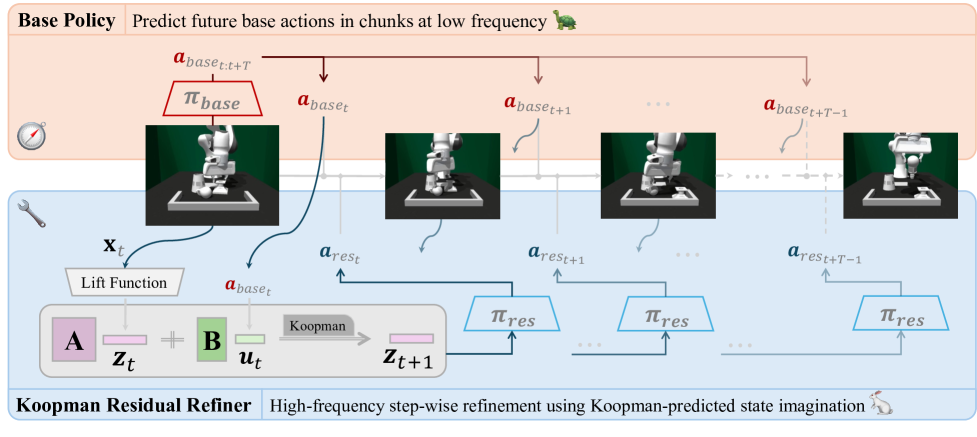
技术框架:KORR框架包含以下主要模块:1) 基础策略:提供初始的动作序列。2) Koopman动态模型:学习状态的潜在表示,并预测未来的状态。3) 残差策略:根据Koopman预测的潜在状态,对基础策略的动作进行校正。整体流程是,首先使用基础策略生成动作,然后将当前状态输入Koopman动态模型进行预测,最后使用残差策略根据预测的潜在状态对动作进行校正。
关键创新:最重要的技术创新点在于将Koopman算子理论引入残差策略学习中,利用Koopman算子学习全局动态模型,从而实现对状态演化的全局理解。与现有方法相比,KORR能够更好地处理长时程任务和未见场景,提高了鲁棒性和泛化能力。
关键设计:KORR的关键设计包括:1) 使用深度神经网络学习状态的潜在表示。2) 使用线性回归学习Koopman算子,从而实现对潜在状态的线性预测。3) 使用条件神经网络学习残差策略,该网络以Koopman预测的潜在状态作为输入。损失函数包括模仿学习损失、动态模型预测损失和正则化项,用于约束潜在空间的结构。
🖼️ 关键图片

📊 实验亮点
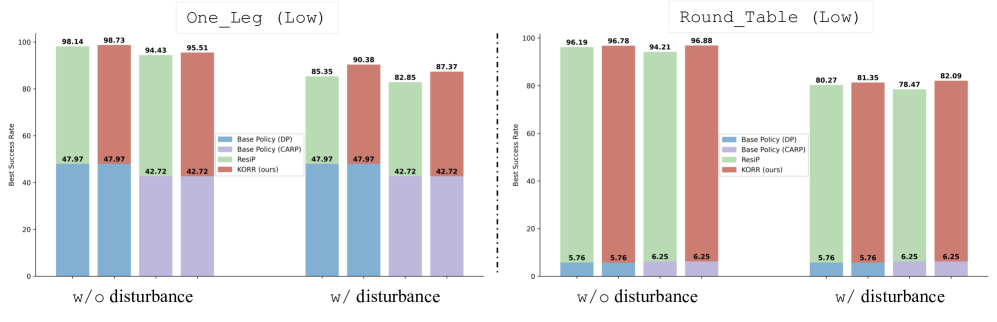
实验结果表明,在长时程机器人家具组装任务中,KORR相比于基线方法,在成功率、鲁棒性和泛化能力方面均有显著提升。例如,在受到外部扰动的情况下,KORR的成功率比基线方法提高了15%-20%。此外,KORR在未见过的家具模型上的泛化能力也优于基线方法。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、游戏AI等领域。通过学习全局动态模型,可以提高智能体在复杂环境中的鲁棒性和泛化能力,使其能够更好地完成长时程任务和适应未知的环境变化。例如,在机器人装配任务中,可以利用该方法提高机器人的装配精度和效率。
📄 摘要(原文)
Imitation learning (IL) enables efficient skill acquisition from demonstrations but often struggles with long-horizon tasks and high-precision control due to compounding errors. Residual policy learning offers a promising, model-agnostic solution by refining a base policy through closed-loop corrections. However, existing approaches primarily focus on local corrections to the base policy, lacking a global understanding of state evolution, which limits robustness and generalization to unseen scenarios. To address this, we propose incorporating global dynamics modeling to guide residual policy updates. Specifically, we leverage Koopman operator theory to impose linear time-invariant structure in a learned latent space, enabling reliable state transitions and improved extrapolation for long-horizon prediction and unseen environments. We introduce KORR (Koopman-guided Online Residual Refinement), a simple yet effective framework that conditions residual corrections on Koopman-predicted latent states, enabling globally informed and stable action refinement. We evaluate KORR on long-horizon, fine-grained robotic furniture assembly tasks under various perturbations. Results demonstrate consistent gains in performance, robustness, and generalization over strong baselines. Our findings further highlight the potential of Koopman-based modeling to bridge modern learning methods with classical control theory.