Embodied Navigation Foundation Model
作者: Jiazhao Zhang, Anqi Li, Yunpeng Qi, Minghan Li, Jiahang Liu, Shaoan Wang, Haoran Liu, Gengze Zhou, Yuze Wu, Xingxing Li, Yuxin Fan, Wenjun Li, Zhibo Chen, Fei Gao, Qi Wu, Zhizheng Zhang, He Wang
分类: cs.RO
发布日期: 2025-09-15 (更新: 2025-09-16)
备注: Project Page: https://pku-epic.github.io/NavFoM-Web/
💡 一句话要点
提出跨具身、跨任务的导航基础模型NavFoM,提升具身智能导航的泛化能力。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱七:动作重定向 (Motion Retargeting) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 导航基础模型 跨具身 跨任务 视觉语言导航
📋 核心要点
- 现有视觉语言模型在具身导航中的泛化能力受限,主要局限于特定任务和具身架构。
- NavFoM采用统一架构处理多模态输入,并使用标识符token嵌入相机视图和时间上下文信息。
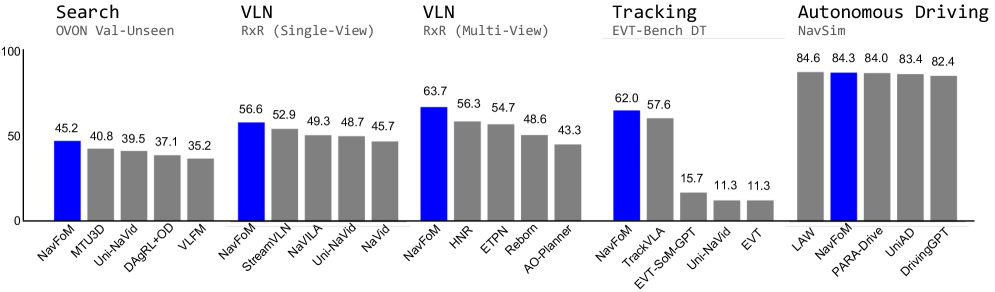
- 实验表明,NavFoM在多个导航任务和具身机器人上取得了领先性能,无需任务特定微调。
📝 摘要(中文)
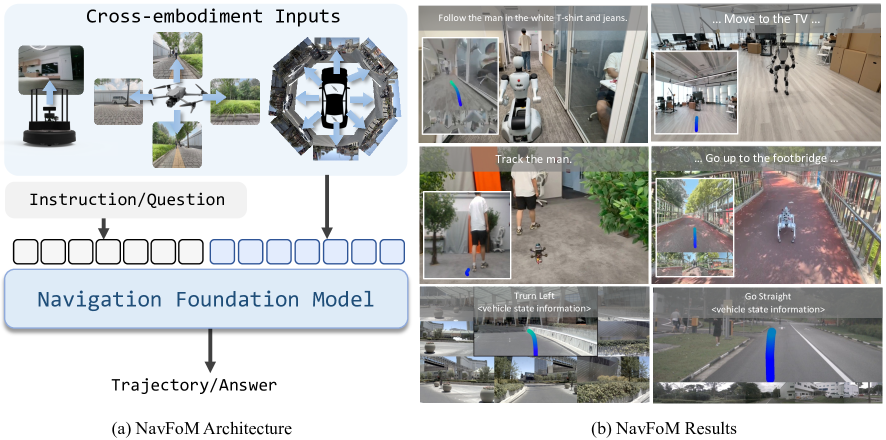
本文提出了一种跨具身和跨任务的导航基础模型(NavFoM),该模型在包含四足机器人、无人机、轮式机器人和车辆的八百万导航样本上进行训练,涵盖了视觉语言导航、目标搜索、目标跟踪和自动驾驶等多种任务。NavFoM采用统一的架构,处理来自不同相机配置和导航范围的多模态导航输入。为了适应不同的相机设置和时间范围,NavFoM结合了标识符token,嵌入了具身机器人的相机视图信息和任务的时间上下文。此外,为了满足实际部署的需求,NavFoM在有限的token长度预算下,使用动态调整的采样策略来控制所有观察token。在公共基准上的大量评估表明,我们的模型在多个导航任务和具身机器人上实现了最先进或极具竞争力的性能,而无需特定于任务的微调。额外的真实世界实验进一步证实了该方法的强大泛化能力和实际适用性。
🔬 方法详解
问题定义:现有具身导航方法泛化性不足,通常针对特定机器人形态和任务设计,难以迁移到新的环境和任务中。大型视觉语言模型(VLMs)在通用视觉语言任务上表现出色,但在具身导航领域的应用仍受限于其对特定任务和具身架构的依赖。因此,如何构建一个能够跨越不同机器人形态和任务的通用导航模型,是本文要解决的核心问题。
核心思路:本文的核心思路是训练一个通用的导航基础模型(NavFoM),使其能够处理来自不同机器人形态(如四足机器人、无人机、轮式机器人和车辆)和不同导航任务(如视觉语言导航、目标搜索、目标跟踪和自动驾驶)的数据。通过大规模的多样化数据训练,NavFoM能够学习到通用的导航策略和环境理解能力,从而实现跨具身和跨任务的泛化。
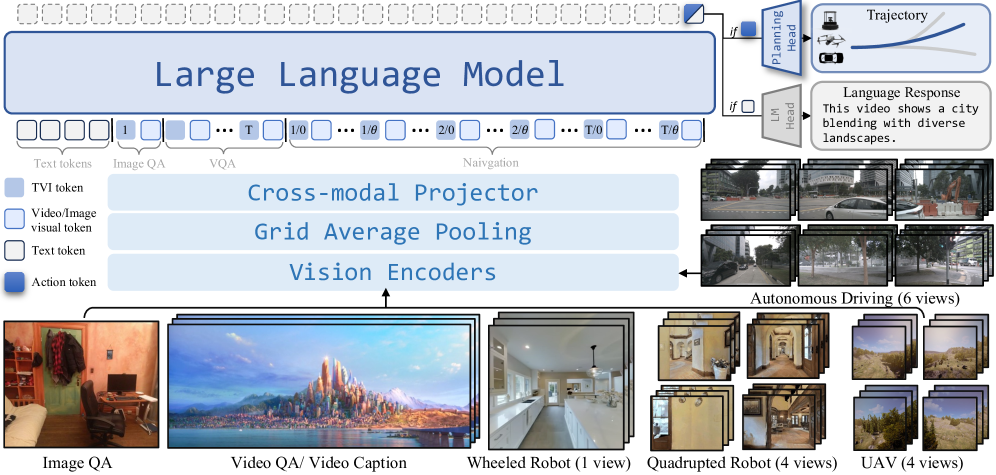
技术框架:NavFoM采用统一的架构,主要包括以下几个模块:1) 多模态输入处理模块:用于处理来自不同传感器(如摄像头、激光雷达)的输入数据,并将其转换为统一的特征表示。2) 标识符Token嵌入模块:用于嵌入机器人形态和任务的时间上下文信息,以便模型能够区分不同的具身和任务。3) Transformer编码器:用于学习输入特征之间的关系,并生成导航策略。4) 动态Token采样模块:在有限的token长度预算下,动态调整观察token的采样策略,以适应真实世界的部署需求。
关键创新:NavFoM的关键创新在于其跨具身和跨任务的泛化能力。通过在包含多种机器人形态和任务的大规模数据集上进行训练,NavFoM能够学习到通用的导航策略和环境理解能力,从而避免了针对特定机器人和任务进行模型定制的需求。此外,动态Token采样模块也是一个重要的创新,它使得NavFoM能够在有限的计算资源下处理复杂的导航场景。
关键设计:NavFoM的关键设计包括:1) 使用标识符Token来区分不同的机器人形态和任务,这使得模型能够学习到与具身和任务相关的特定知识。2) 采用Transformer编码器来学习输入特征之间的关系,这使得模型能够捕捉到复杂的环境信息。3) 设计动态Token采样模块,根据环境的复杂程度动态调整观察token的采样频率,以提高计算效率。
🖼️ 关键图片
📊 实验亮点
NavFoM在多个公共基准测试中取得了最先进或极具竞争力的性能,无需针对特定任务进行微调。例如,在视觉语言导航任务中,NavFoM的性能超过了现有的SOTA模型。此外,在真实世界的实验中,NavFoM也表现出了强大的泛化能力和鲁棒性,能够适应复杂的环境和任务。
🎯 应用场景
NavFoM具有广泛的应用前景,可应用于自动驾驶、物流配送、家庭服务机器人、安防巡逻等领域。通过将NavFoM部署到不同的机器人平台上,可以实现快速的任务部署和环境适应,降低开发成本,提高工作效率。此外,NavFoM还可以作为具身智能研究的基础平台,促进相关技术的发展。
📄 摘要(原文)
Navigation is a fundamental capability in embodied AI, representing the intelligence required to perceive and interact within physical environments following language instructions. Despite significant progress in large Vision-Language Models (VLMs), which exhibit remarkable zero-shot performance on general vision-language tasks, their generalization ability in embodied navigation remains largely confined to narrow task settings and embodiment-specific architectures. In this work, we introduce a cross-embodiment and cross-task Navigation Foundation Model (NavFoM), trained on eight million navigation samples that encompass quadrupeds, drones, wheeled robots, and vehicles, and spanning diverse tasks such as vision-and-language navigation, object searching, target tracking, and autonomous driving. NavFoM employs a unified architecture that processes multimodal navigation inputs from varying camera configurations and navigation horizons. To accommodate diverse camera setups and temporal horizons, NavFoM incorporates identifier tokens that embed camera view information of embodiments and the temporal context of tasks. Furthermore, to meet the demands of real-world deployment, NavFoM controls all observation tokens using a dynamically adjusted sampling strategy under a limited token length budget. Extensive evaluations on public benchmarks demonstrate that our model achieves state-of-the-art or highly competitive performance across multiple navigation tasks and embodiments without requiring task-specific fine-tuning. Additional real-world experiments further confirm the strong generalization capability and practical applicability of our approach.