ActivePose: Active 6D Object Pose Estimation and Tracking for Robotic Manipulation
作者: Sheng Liu, Zhe Li, Weiheng Wang, Han Sun, Heng Zhang, Hongpeng Chen, Yusen Qin, Arash Ajoudani, Yizhao Wang
分类: cs.RO
发布日期: 2025-09-14
备注: 6D Pose, Diffusion Policy
💡 一句话要点
提出ActivePose,结合VLM与机器人主动探索,解决机器人操作中6D位姿估计与跟踪难题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 6D位姿估计 机器人操作 主动视觉 视觉-语言模型 机器人想象
📋 核心要点
- 现有6D位姿估计方法在视角变化、物体移动或自遮挡情况下存在鲁棒性问题,限制了机器人操作的可靠性。
- ActivePose利用视觉-语言模型和机器人主动探索,通过动态调整相机视角来消除位姿估计中的歧义。
- 实验结果表明,ActivePose在模拟和真实环境中均优于传统方法,显著提升了位姿估计的准确性和鲁棒性。
📝 摘要(中文)
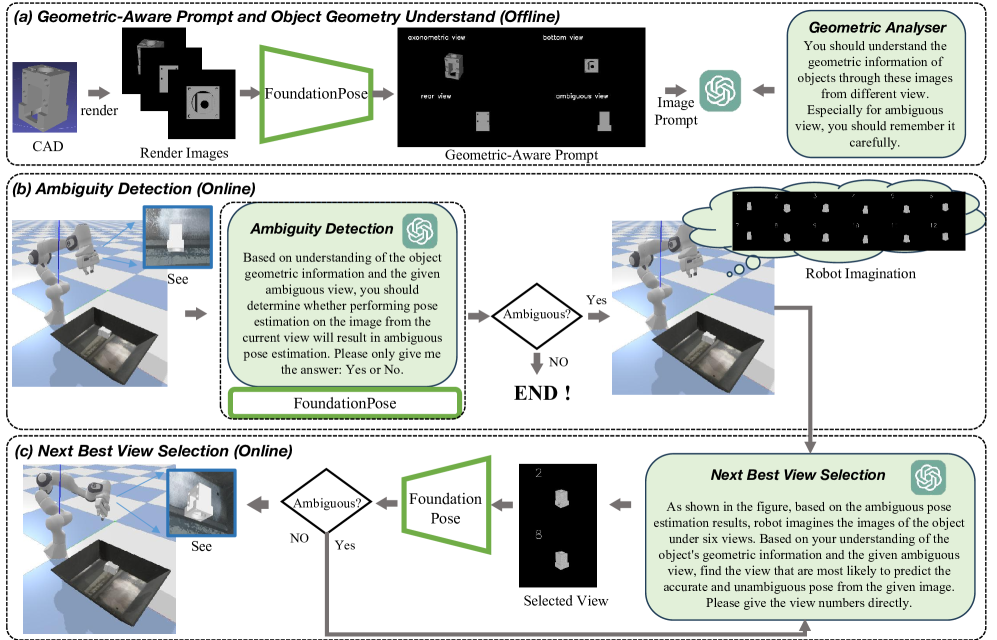
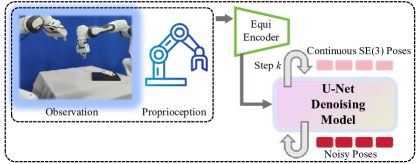
精确的6自由度物体位姿估计和跟踪对于可靠的机器人操作至关重要。然而,零样本方法在视角引起的歧义下常常失效,而固定相机设置在物体移动或发生自遮挡时表现不佳。为了解决这些挑战,我们提出了一种主动位姿估计流程,该流程结合了视觉-语言模型(VLM)与“机器人想象”,以动态地检测和实时解决歧义。在离线阶段,我们渲染CAD模型的密集视图集,计算每个视图的FoundationPose熵,并构建一个几何感知的提示,其中包括低熵(无歧义)和高熵(有歧义)的示例。在运行时,系统:(1)查询VLM以获得实时图像的歧义分数;(2)如果检测到歧义,则通过渲染虚拟视图来想象一组离散的候选相机姿势,基于VLM歧义概率和FoundationPose熵的加权组合对每个姿势进行评分,然后将相机移动到下一个最佳视图(NBV)以获得消除歧义的位姿估计。此外,由于移动的物体可能会离开相机的视野,我们引入了一个主动位姿跟踪模块:一个通过模仿学习训练的扩散策略,该策略生成保持物体可见性并最小化位姿歧义的相机轨迹。在模拟和真实世界的实验表明,我们的方法明显优于经典基线。
🔬 方法详解
问题定义:论文旨在解决机器人操作中,由于视角变化、物体移动或自遮挡导致的6D位姿估计不准确问题。现有方法,如零样本方法,在这些情况下表现不佳,严重影响了机器人操作的可靠性。
核心思路:论文的核心思路是利用“机器人想象”和视觉-语言模型(VLM)来主动消除位姿估计中的歧义。通过预测不同相机视角下的信息量,并主动移动相机到信息量最大的视角(Next-Best-View),从而获得更准确的位姿估计。
技术框架:ActivePose包含离线阶段和在线阶段。离线阶段,渲染CAD模型的大量视图,计算FoundationPose熵,并构建几何感知的提示。在线阶段,系统首先使用VLM评估当前图像的歧义性。如果检测到歧义,则“想象”一组候选相机姿势,并根据VLM歧义概率和FoundationPose熵的加权组合对每个姿势进行评分。然后,相机移动到下一个最佳视图(NBV)。此外,还包含一个主动位姿跟踪模块,使用扩散策略生成相机轨迹,以保持物体可见性并最小化位姿歧义。
关键创新:该方法最重要的创新点在于结合了视觉-语言模型和机器人主动探索,实现了动态的歧义检测和消除。与传统方法相比,ActivePose能够根据场景的复杂性主动调整相机视角,从而获得更准确的位姿估计。主动位姿跟踪模块也是一个创新点,它能够应对物体移动带来的挑战。
关键设计:离线阶段,FoundationPose熵用于衡量每个视角的歧义性。在线阶段,VLM用于评估当前图像的歧义性,并与FoundationPose熵结合,用于选择下一个最佳视图。主动位姿跟踪模块使用扩散策略,通过模仿学习训练,生成相机轨迹。具体损失函数和网络结构等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
论文通过模拟和真实环境实验验证了ActivePose的有效性。实验结果表明,ActivePose显著优于传统基线方法,能够更准确地估计和跟踪物体的6D位姿。具体的性能数据和提升幅度未在摘要中给出,属于未知信息。
🎯 应用场景
ActivePose技术可广泛应用于机器人操作、自动化装配、物流分拣等领域。通过提高机器人对物体位姿的感知精度,可以显著提升机器人操作的效率和可靠性,降低人工干预的需求,实现更智能化的自动化生产。
📄 摘要(原文)
Accurate 6-DoF object pose estimation and tracking are critical for reliable robotic manipulation. However, zero-shot methods often fail under viewpoint-induced ambiguities and fixed-camera setups struggle when objects move or become self-occluded. To address these challenges, we propose an active pose estimation pipeline that combines a Vision-Language Model (VLM) with "robotic imagination" to dynamically detect and resolve ambiguities in real time. In an offline stage, we render a dense set of views of the CAD model, compute the FoundationPose entropy for each view, and construct a geometric-aware prompt that includes low-entropy (unambiguous) and high-entropy (ambiguous) examples. At runtime, the system: (1) queries the VLM on the live image for an ambiguity score; (2) if ambiguity is detected, imagines a discrete set of candidate camera poses by rendering virtual views, scores each based on a weighted combination of VLM ambiguity probability and FoundationPose entropy, and then moves the camera to the Next-Best-View (NBV) to obtain a disambiguated pose estimation. Furthermore, since moving objects may leave the camera's field of view, we introduce an active pose tracking module: a diffusion-policy trained via imitation learning, which generates camera trajectories that preserve object visibility and minimize pose ambiguity. Experiments in simulation and real-world show that our approach significantly outperforms classical baselines.