Policy Learning for Social Robot-Led Physiotherapy
作者: Carl Bettosi, Lynne Ballie, Susan Shenkin, Marta Romeo
分类: cs.RO, cs.AI
发布日期: 2025-09-14
💡 一句话要点
提出基于强化学习的社交机器人引导康复策略,解决数据稀缺问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 社交机器人 物理治疗 强化学习 患者行为建模 人机交互
📋 核心要点
- 现有社交机器人引导康复训练面临患者行为数据稀缺的挑战,难以制定适应性策略。
- 论文利用专家作为患者代理,构建患者行为模型,生成运动表现和主观评分数据。
- 通过强化学习训练策略,使机器人能够根据患者状态调整运动指导,适用于不同阶段的患者。
📝 摘要(中文)
社交机器人为自主引导患者进行物理治疗提供了一种有前景的解决方案,但有效的部署需要先进的决策能力来适应患者的需求。一个关键的挑战是缺乏患者行为数据来开发稳健的策略。为了解决这个问题,我们招募了33位专业的医疗保健从业者作为患者代理,利用他们与我们机器人的互动来构建患者行为模型,该模型能够生成运动表现指标和关于感知劳累程度的主观评分。我们在模拟环境中训练了一个基于强化学习的策略,结果表明该策略可以根据个体的劳累耐受性和波动的表现来调整运动指导,同时适用于处于不同恢复阶段且具有不同运动计划的患者。
🔬 方法详解
问题定义:论文旨在解决社交机器人辅助物理治疗中,由于缺乏真实患者数据而难以训练有效策略的问题。现有方法难以根据患者的个体差异(如劳累程度、恢复阶段)动态调整运动指导,导致训练效果不佳。
核心思路:论文的核心思路是利用领域专家作为患者代理,模拟患者行为,生成训练数据。通过专家与机器人的互动,构建一个能够预测患者运动表现和主观感受的患者行为模型。然后,利用该模型在模拟环境中训练强化学习策略。
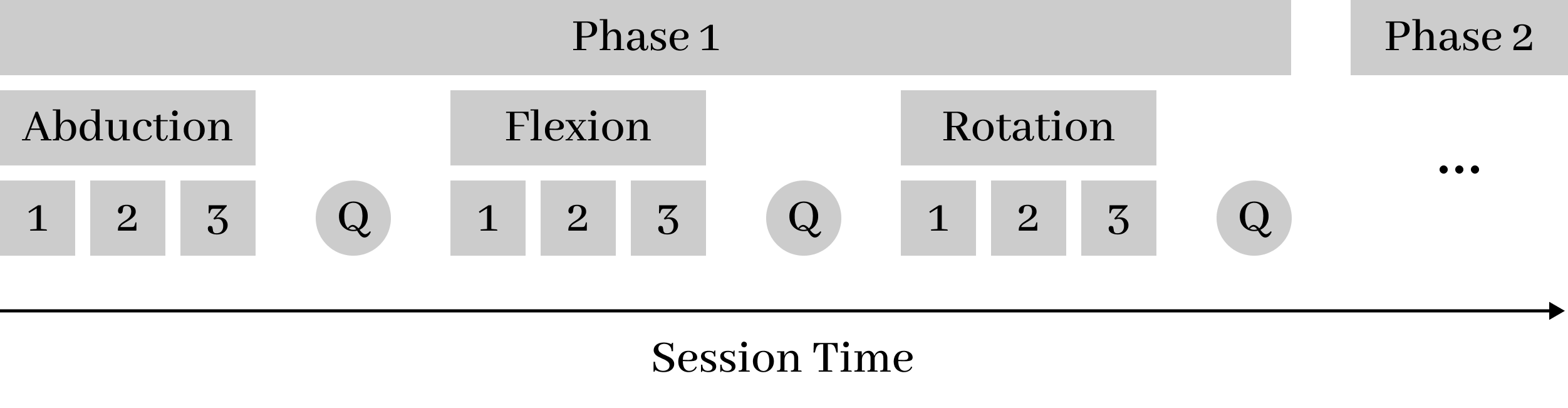
技术框架:整体框架包含三个主要模块:1) 患者行为模型构建:通过收集专家与机器人的交互数据,训练一个模型来预测患者的运动表现指标和主观劳累程度评分。2) 强化学习策略训练:在模拟环境中,使用患者行为模型作为环境,训练一个强化学习策略,该策略能够根据患者的运动表现和主观感受,动态调整运动指导。3) 策略评估:在模拟环境中评估训练好的策略,验证其在不同患者状态下的适应性和有效性。
关键创新:论文的关键创新在于利用专家知识构建患者行为模型,从而克服了真实患者数据稀缺的问题。这种方法允许在模拟环境中训练强化学习策略,而无需依赖大量的真实患者数据。此外,该策略能够同时考虑运动表现和主观感受,从而提供更加个性化的运动指导。
关键设计:患者行为模型可能采用回归模型或神经网络,输入包括机器人的运动指令、患者的运动表现等,输出为运动表现指标(如动作完成度、准确性)和主观劳累程度评分。强化学习算法可能采用Q-learning或Policy Gradient方法,奖励函数的设计需要考虑运动表现的提升和患者的舒适度。具体的参数设置和网络结构在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片


📊 实验亮点
论文通过模拟实验验证了所提出的强化学习策略的有效性。实验结果表明,该策略能够根据患者的劳累耐受性和波动的表现来调整运动指导,并且适用于处于不同恢复阶段且具有不同运动计划的患者。具体的性能数据和对比基线在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于智能康复机器人系统,为患者提供个性化的物理治疗指导。通过社交机器人与患者互动,实时调整运动计划,提高康复效果和患者依从性。该技术还可扩展到其他需要人机协作的领域,如老年护理、特殊教育等。
📄 摘要(原文)
Social robots offer a promising solution for autonomously guiding patients through physiotherapy exercise sessions, but effective deployment requires advanced decision-making to adapt to patient needs. A key challenge is the scarcity of patient behavior data for developing robust policies. To address this, we engaged 33 expert healthcare practitioners as patient proxies, using their interactions with our robot to inform a patient behavior model capable of generating exercise performance metrics and subjective scores on perceived exertion. We trained a reinforcement learning-based policy in simulation, demonstrating that it can adapt exercise instructions to individual exertion tolerances and fluctuating performance, while also being applicable to patients at different recovery stages with varying exercise plans.