Dexplore: Scalable Neural Control for Dexterous Manipulation from Reference-Scoped Exploration
作者: Sirui Xu, Yu-Wei Chao, Liuyu Bian, Arsalan Mousavian, Yu-Xiong Wang, Liang-Yan Gui, Wei Yang
分类: cs.RO, cs.CV
发布日期: 2025-09-11
备注: CoRL 2025
💡 一句话要点
Dexplore:基于参考范围探索的可扩展神经控制,用于灵巧操作
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 灵巧操作 机器人控制 运动捕捉 强化学习 策略蒸馏
📋 核心要点
- 现有灵巧操作方法依赖多阶段流程,易累积误差且未充分利用演示数据。
- Dexplore提出统一的单循环优化,联合重定向和跟踪,直接从MoCap数据学习策略。
- Dexplore通过自适应空间范围和强化学习,提升策略鲁棒性,并泛化到真实场景。
📝 摘要(中文)
手部-物体运动捕捉(MoCap)库提供了大规模、富含接触的演示数据,为扩展灵巧机器人操作提供了可能。然而,演示数据的不准确性以及人类和机器人手之间的差异限制了这些数据的直接使用。现有方法通常采用三阶段工作流程,包括重定向、跟踪和残差校正,这往往导致演示数据未被充分利用,并在各个阶段累积误差。我们提出了Dexplore,一种统一的单循环优化方法,它联合执行重定向和跟踪,从而直接从大规模MoCap数据中学习机器人控制策略。我们不将演示视为真值,而是将其用作软指导。从原始轨迹中,我们推导出自适应空间范围,并使用强化学习进行训练,以使策略保持在范围内,同时最小化控制工作量并完成任务。这种统一的公式保留了演示意图,使机器人特定的策略得以涌现,提高了对噪声的鲁棒性,并可扩展到大型演示语料库。我们将缩放后的跟踪策略提炼成一个基于视觉、技能条件生成控制器,该控制器在丰富的潜在表示中编码了各种操作技能,支持跨对象的泛化和真实世界的部署。总而言之,这些贡献使Dexplore成为一座原则性的桥梁,将不完美的演示转化为灵巧操作的有效训练信号。
🔬 方法详解
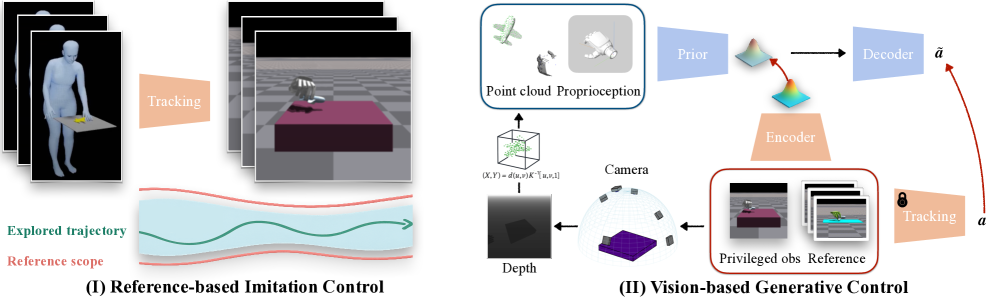
问题定义:现有灵巧操作方法通常采用三阶段流程:首先将人类的运动捕捉数据重定向到机器人手,然后进行跟踪,最后进行残差校正。这种方法存在几个痛点:一是演示数据本身可能存在不准确性;二是人类手和机器人手之间存在结构差异,导致重定向过程引入误差;三是多阶段流程容易累积误差,并且未充分利用原始演示数据中蕴含的信息。
核心思路:Dexplore的核心思路是将重定向和跟踪两个步骤统一到一个单循环优化框架中,从而避免了多阶段流程中的误差累积。同时,Dexplore不将演示数据视为绝对真值,而是将其作为一种软指导,允许机器人学习自身特定的策略,以更好地适应其自身的结构和环境。这种方法能够更好地利用大规模的运动捕捉数据,并提高策略的鲁棒性和泛化能力。
技术框架:Dexplore的整体框架包含以下几个主要模块:1) 数据预处理:从原始运动捕捉数据中提取轨迹信息,并构建自适应空间范围,用于约束策略的学习。2) 策略学习:使用强化学习算法训练机器人控制策略,目标是使策略在空间范围内执行任务,同时最小化控制成本。3) 策略蒸馏:将学习到的策略蒸馏成一个基于视觉的、技能条件生成控制器,该控制器能够编码各种操作技能,并支持跨对象的泛化。
关键创新:Dexplore最重要的技术创新在于其统一的单循环优化框架,它将重定向和跟踪两个步骤整合在一起,避免了多阶段流程中的误差累积。此外,Dexplore还引入了自适应空间范围的概念,用于约束策略的学习,并允许机器人学习自身特定的策略。与现有方法相比,Dexplore能够更好地利用大规模的运动捕捉数据,并提高策略的鲁棒性和泛化能力。
关键设计:Dexplore的关键设计包括:1) 自适应空间范围:根据原始轨迹动态调整空间范围的大小和形状,以适应不同的任务和环境。2) 强化学习算法:使用合适的强化学习算法(具体算法未知)训练机器人控制策略,目标是最大化奖励函数,该奖励函数包括任务完成度、控制成本和空间范围约束等。3) 技能条件生成控制器:使用神经网络构建技能条件生成控制器,该控制器能够根据输入的技能编码生成相应的控制指令。
🖼️ 关键图片

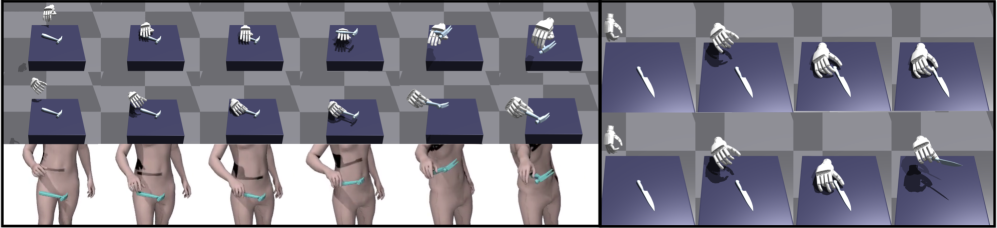
📊 实验亮点
论文提出的Dexplore方法在灵巧操作任务上取得了显著的成果。通过与现有方法进行对比,Dexplore在鲁棒性、泛化能力和任务完成度等方面均有明显提升。具体的性能数据和提升幅度在论文中进行了详细的展示(具体数值未知),证明了Dexplore的有效性和优越性。
🎯 应用场景
Dexplore具有广泛的应用前景,可用于各种灵巧操作任务,例如装配、抓取、操作工具等。该研究成果可以应用于工业自动化、医疗机器人、家庭服务机器人等领域,提高机器人的智能化水平和操作能力。通过将不完美的演示数据转化为有效的训练信号,Dexplore为机器人学习复杂操作技能提供了一种新的途径。
📄 摘要(原文)
Hand-object motion-capture (MoCap) repositories offer large-scale, contact-rich demonstrations and hold promise for scaling dexterous robotic manipulation. Yet demonstration inaccuracies and embodiment gaps between human and robot hands limit the straightforward use of these data. Existing methods adopt a three-stage workflow, including retargeting, tracking, and residual correction, which often leaves demonstrations underused and compound errors across stages. We introduce Dexplore, a unified single-loop optimization that jointly performs retargeting and tracking to learn robot control policies directly from MoCap at scale. Rather than treating demonstrations as ground truth, we use them as soft guidance. From raw trajectories, we derive adaptive spatial scopes, and train with reinforcement learning to keep the policy in-scope while minimizing control effort and accomplishing the task. This unified formulation preserves demonstration intent, enables robot-specific strategies to emerge, improves robustness to noise, and scales to large demonstration corpora. We distill the scaled tracking policy into a vision-based, skill-conditioned generative controller that encodes diverse manipulation skills in a rich latent representation, supporting generalization across objects and real-world deployment. Taken together, these contributions position Dexplore as a principled bridge that transforms imperfect demonstrations into effective training signals for dexterous manipulation.