VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
作者: Yihao Wang, Pengxiang Ding, Lingxiao Li, Can Cui, Zirui Ge, Xinyang Tong, Wenxuan Song, Han Zhao, Wei Zhao, Pengxu Hou, Siteng Huang, Yifan Tang, Wenhui Wang, Ru Zhang, Jianyi Liu, Donglin Wang
分类: cs.RO
发布日期: 2025-09-11 (更新: 2025-09-22)
备注: 28 pages; Project page: https://vla-adapter.github.io/; Github: https://github.com/OpenHelix-Team/VLA-Adapter; HuggingFace: https://huggingface.co/VLA-Adapter
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
VLA-Adapter:一种高效的微型视觉-语言-动作模型范式
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人学习 桥接注意力 轻量级模型 迁移学习
📋 核心要点
- 现有VLA模型依赖大规模VLM预训练,导致训练成本高昂,限制了其应用。
- VLA-Adapter通过桥接注意力机制,将视觉-语言信息高效注入动作空间,无需大规模预训练。
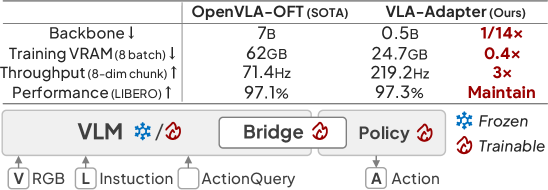
- 实验表明,VLA-Adapter在性能上达到SOTA,推理速度快,且能在消费级GPU上快速训练。
📝 摘要(中文)
视觉-语言-动作(VLA)模型通常通过在机器人数据上预训练大规模视觉-语言模型(VLM)来弥合感知和动作空间之间的差距。虽然这种方法极大地提高了性能,但也带来了巨大的训练成本。本文研究了如何有效地将视觉-语言(VL)表示桥接到动作(A)。我们引入了VLA-Adapter,这是一种旨在减少VLA模型对大型VLM和广泛预训练的依赖的新范式。为此,我们首先系统地分析了各种VL条件的有效性,并提出了关于哪些条件对于桥接感知和动作空间至关重要的关键发现。基于这些见解,我们提出了一个带有桥接注意力的轻量级策略模块,该模块自主地将最佳条件注入到动作空间中。通过这种方式,我们的方法仅使用0.5B参数的骨干网络即可实现高性能,而无需任何机器人数据预训练。在模拟和真实机器人基准上的大量实验表明,VLA-Adapter不仅实现了最先进的性能水平,而且还提供了迄今为止最快的推理速度。此外,由于所提出的先进桥接范式,VLA-Adapter能够在单个消费级GPU上仅用8小时训练一个强大的VLA模型,大大降低了部署VLA模型的门槛。
🔬 方法详解
问题定义:VLA模型需要大量的计算资源和数据进行预训练,这使得它们难以部署和应用。现有的方法通常依赖于大型视觉-语言模型(VLM)作为骨干网络,并在机器人数据上进行微调。这种方法虽然有效,但成本高昂,并且需要大量的机器人数据。因此,如何降低VLA模型的训练成本,使其能够在资源有限的环境中运行,是一个重要的研究问题。
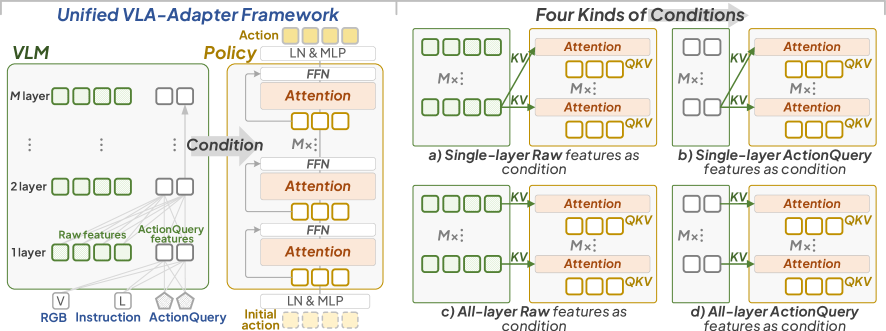
核心思路:VLA-Adapter的核心思路是通过一个轻量级的适配器模块,将视觉-语言信息有效地桥接到动作空间。该适配器模块包含一个桥接注意力机制,可以自主地选择和注入最相关的视觉-语言条件到动作空间中。这种方法避免了对大型VLM的依赖,并且可以在没有机器人数据预训练的情况下实现高性能。
技术框架:VLA-Adapter的整体框架包括一个视觉编码器、一个语言编码器、一个策略模块和一个动作解码器。视觉编码器和语言编码器用于提取视觉和语言特征。策略模块包含桥接注意力机制,用于选择和注入最相关的视觉-语言条件到动作空间中。动作解码器根据注入的视觉-语言条件生成动作。整个框架是端到端可训练的。
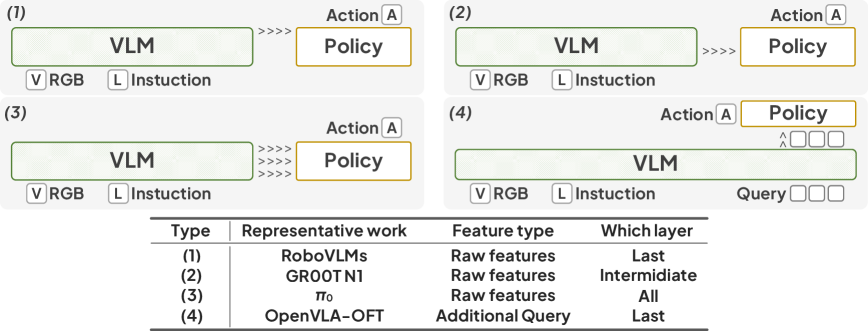
关键创新:VLA-Adapter的关键创新在于桥接注意力机制。该机制可以自主地学习哪些视觉-语言条件对于生成动作是最重要的,并将这些条件注入到动作空间中。与现有方法相比,VLA-Adapter不需要手动设计视觉-语言条件的注入方式,并且可以更好地适应不同的任务和环境。
关键设计:桥接注意力机制使用一个注意力网络来计算每个视觉-语言条件的权重。该注意力网络的输入是视觉特征、语言特征和动作特征。注意力网络的输出是每个视觉-语言条件的权重。然后,使用这些权重对视觉-语言条件进行加权求和,并将结果注入到动作空间中。损失函数包括动作预测损失和注意力正则化损失。动作预测损失用于训练动作解码器。注意力正则化损失用于鼓励注意力网络选择最相关的视觉-语言条件。
🖼️ 关键图片
📊 实验亮点
VLA-Adapter在模拟和真实机器人基准测试中均取得了最先进的性能。在无需任何机器人数据预训练的情况下,仅使用0.5B参数的骨干网络,就能够达到SOTA水平。此外,VLA-Adapter的推理速度非常快,并且可以在单个消费级GPU上仅用8小时完成训练,大大降低了VLA模型的部署门槛。
🎯 应用场景
VLA-Adapter具有广泛的应用前景,例如机器人导航、物体操作、人机协作等。由于其训练成本低、推理速度快,可以部署在资源有限的机器人平台上,实现智能化的自主控制。该研究有助于推动机器人技术的发展,使其能够更好地服务于人类生活。
📄 摘要(原文)
Vision-Language-Action (VLA) models typically bridge the gap between perceptual and action spaces by pre-training a large-scale Vision-Language Model (VLM) on robotic data. While this approach greatly enhances performance, it also incurs significant training costs. In this paper, we investigate how to effectively bridge vision-language (VL) representations to action (A). We introduce VLA-Adapter, a novel paradigm designed to reduce the reliance of VLA models on large-scale VLMs and extensive pre-training. To this end, we first systematically analyze the effectiveness of various VL conditions and present key findings on which conditions are essential for bridging perception and action spaces. Based on these insights, we propose a lightweight Policy module with Bridge Attention, which autonomously injects the optimal condition into the action space. In this way, our method achieves high performance using only a 0.5B-parameter backbone, without any robotic data pre-training. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that VLA-Adapter not only achieves state-of-the-art level performance, but also offers the fast inference speed reported to date. Furthermore, thanks to the proposed advanced bridging paradigm, VLA-Adapter enables the training of a powerful VLA model in just 8 hours on a single consumer-grade GPU, greatly lowering the barrier to deploying the VLA model. Project page: https://vla-adapter.github.io/.