LIPM-Guided Reinforcement Learning for Stable and Perceptive Locomotion in Bipedal Robots
作者: Haokai Su, Haoxiang Luo, Shunpeng Yang, Kaiwen Jiang, Wei Zhang, Hua Chen
分类: cs.RO
发布日期: 2025-09-11 (更新: 2025-10-19)
💡 一句话要点
提出基于LIPM引导的强化学习方法,实现双足机器人在复杂地形中的稳定感知运动。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 双足机器人 强化学习 线性倒立摆模型 动态平衡 地形适应性
📋 核心要点
- 双足机器人在非结构化户外环境中实现稳定和鲁棒的感知运动仍然是一个关键挑战,因为地形复杂且易受外部干扰。
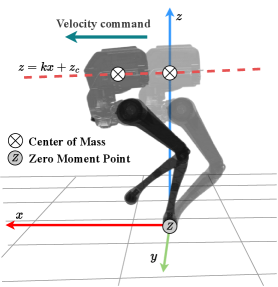
- 论文核心思想是利用线性倒立摆模型(LIPM)指导奖励函数设计,从而实现平衡和动态稳定性,并鼓励精确的质心轨迹跟踪。
- 通过仿真和真实环境实验验证,该方法在地形适应性、抗干扰能力和各种速度下的性能表现出优越性。
📝 摘要(中文)
本文提出了一种受线性倒立摆模型(LIPM)启发的奖励函数设计,旨在使双足机器人在非结构化户外环境中实现具有感知能力和稳定性的运动。LIPM通过调节质心(CoM)高度和躯干方向,为动态平衡提供理论指导。这些是地形感知运动的关键因素,因为它们有助于确保机器人相机获得稳定的视点。基于此,我们设计了一个奖励函数,该函数在鼓励精确的CoM轨迹跟踪的同时,促进平衡和动态稳定性。为了自适应地权衡速度跟踪和稳定性,我们利用奖励融合模块(RFM)方法,在需要时优先考虑稳定性。采用双评论家架构分别评估稳定性和运动目标,从而提高训练效率和鲁棒性。通过在仿真和真实户外环境中对双足机器人进行的大量实验验证了该方法的有效性。结果表明,该方法具有卓越的地形适应性、抗干扰能力,以及在各种速度和感知条件下的一致性能。
🔬 方法详解
问题定义:双足机器人在复杂户外环境中难以保持稳定和鲁棒的运动,尤其是在面对不规则地形和外部扰动时。现有的方法通常难以兼顾运动速度、稳定性和感知能力,容易出现摔倒或运动轨迹偏差。
核心思路:利用线性倒立摆模型(LIPM)作为理论指导,通过调节质心(CoM)高度和躯干方向来维持动态平衡。LIPM能够简化机器人运动学模型,从而更容易设计奖励函数,引导强化学习算法学习到稳定的运动策略。同时,保持稳定的躯干姿态有利于机器人视觉系统的感知。
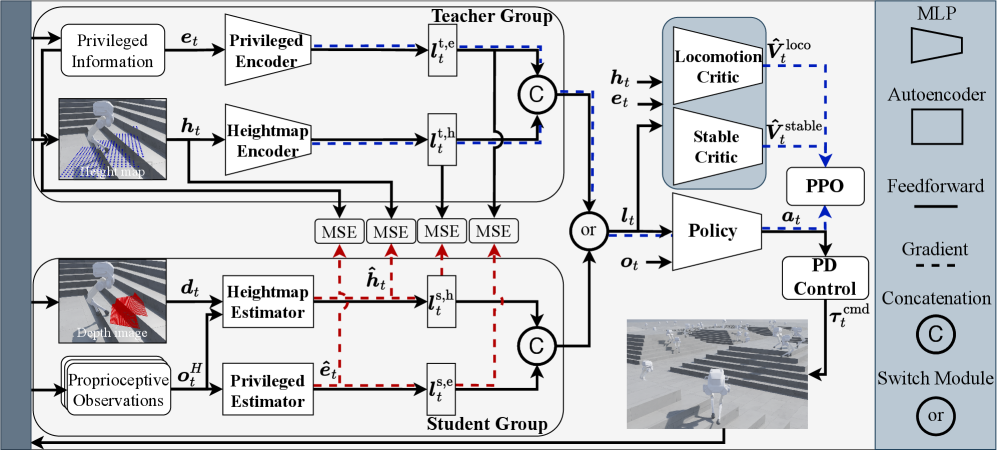
技术框架:整体框架包括环境感知模块、强化学习控制模块和机器人运动执行模块。环境感知模块负责获取地形信息,强化学习控制模块基于LIPM设计的奖励函数生成控制指令,机器人运动执行模块将控制指令转化为关节运动。采用双评论家(Double-Critic)架构,分别评估稳定性和运动目标,提高训练效率。
关键创新:关键创新在于将LIPM模型融入到强化学习的奖励函数设计中,从而为机器人提供明确的平衡和稳定性目标。此外,使用奖励融合模块(RFM)自适应地权衡速度跟踪和稳定性,在需要时优先保证稳定性。双评论家架构也提高了训练效率和鲁棒性。
关键设计:奖励函数的设计是关键,包括CoM轨迹跟踪奖励、躯干姿态稳定奖励和平衡奖励。CoM轨迹跟踪奖励鼓励机器人按照期望的速度运动,躯干姿态稳定奖励保证躯干的水平,平衡奖励则基于LIPM模型计算,惩罚CoM偏离稳定区域的行为。RFM模块根据当前状态动态调整速度跟踪奖励和稳定性奖励的权重。双评论家网络分别评估稳定性和运动目标,采用独立的网络结构和损失函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在仿真和真实环境中均表现出良好的性能。在真实环境中,机器人能够成功穿越草地、碎石路等复杂地形,并能有效抵抗外部推力干扰。与传统的强化学习方法相比,该方法在稳定性和地形适应性方面有显著提升,能够实现更鲁棒的户外运动。
🎯 应用场景
该研究成果可应用于搜救机器人、巡检机器人、物流机器人等需要在复杂地形中稳定行走的场景。通过提高机器人的地形适应性和抗干扰能力,可以使其在更广泛的户外环境中执行任务,例如灾后救援、野外勘探和农业生产等。未来,该技术有望进一步推广到其他类型的机器人,例如四足机器人和人形机器人。
📄 摘要(原文)
Achieving stable and robust perceptive locomotion for bipedal robots in unstructured outdoor environments remains a critical challenge due to complex terrain geometry and susceptibility to external disturbances. In this work, we propose a novel reward design inspired by the Linear Inverted Pendulum Model (LIPM) to enable perceptive and stable locomotion in the wild. The LIPM provides theoretical guidance for dynamic balance by regulating the center of mass (CoM) height and the torso orientation. These are key factors for terrain-aware locomotion, as they help ensure a stable viewpoint for the robot's camera. Building on this insight, we design a reward function that promotes balance and dynamic stability while encouraging accurate CoM trajectory tracking. To adaptively trade off between velocity tracking and stability, we leverage the Reward Fusion Module (RFM) approach that prioritizes stability when needed. A double-critic architecture is adopted to separately evaluate stability and locomotion objectives, improving training efficiency and robustness. We validate our approach through extensive experiments on a bipedal robot in both simulation and real-world outdoor environments. The results demonstrate superior terrain adaptability, disturbance rejection, and consistent performance across a wide range of speeds and perceptual conditions.