SocialNav-SUB: Benchmarking VLMs for Scene Understanding in Social Robot Navigation
作者: Michael J. Munje, Chen Tang, Shuijing Liu, Zichao Hu, Yifeng Zhu, Jiaxun Cui, Garrett Warnell, Joydeep Biswas, Peter Stone
分类: cs.RO, cs.CV
发布日期: 2025-09-10
备注: Conference on Robot Learning (CoRL) 2025 Project site: https://larg.github.io/socialnav-sub
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出SocialNav-SUB基准,评估VLM在社交机器人导航场景中的场景理解能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社交机器人导航 视觉语言模型 场景理解 视觉问答 基准数据集
📋 核心要点
- 社交机器人导航需要对动态环境进行鲁棒的场景理解,现有VLM在复杂社交场景理解方面存在不足。
- 提出SocialNav-SUB基准,通过VQA任务评估VLM在空间、时空和社会推理方面的能力。
- 实验表明,现有VLM在社交场景理解方面与人类和基于规则的方法相比仍有差距,有待提升。
📝 摘要(中文)
本文提出了社交导航场景理解基准(SocialNav-SUB),这是一个视觉问答(VQA)数据集和基准,旨在评估视觉语言模型(VLM)在真实社交机器人导航场景中的场景理解能力。SocialNav-SUB提供了一个统一的框架,用于评估VLM在需要空间、时空和社会推理的VQA任务中,与人类和基于规则的基线进行比较。通过对最先进的VLM进行实验,发现虽然性能最佳的VLM在与人类答案达成一致方面取得了令人鼓舞的概率,但仍然不如简单的基于规则的方法和人类共识基线,这表明当前VLM在社交场景理解方面存在关键差距。该基准为进一步研究社交机器人导航的基础模型奠定了基础,提供了一个探索如何定制VLM以满足真实社交机器人导航需求的框架。
🔬 方法详解
问题定义:社交机器人需要在动态、以人为中心的环境中进行导航,这要求机器人能够理解复杂的社交场景,例如推断智能体之间的时空关系和人类意图。现有的视觉语言模型(VLM)在社交机器人导航中的应用潜力尚未得到充分评估,尤其是在理解复杂社交场景方面。现有的方法缺乏系统性的评估,无法确定VLM是否能满足安全和符合社会规范的机器人导航的必要条件。
核心思路:本文的核心思路是构建一个专门用于评估VLM在社交机器人导航场景中场景理解能力的基准数据集和评估框架。通过设计包含空间、时空和社会推理的视觉问答(VQA)任务,系统地评估VLM对复杂社交场景的理解程度。这样可以识别VLM在社交场景理解方面的优势和不足,为后续研究提供指导。
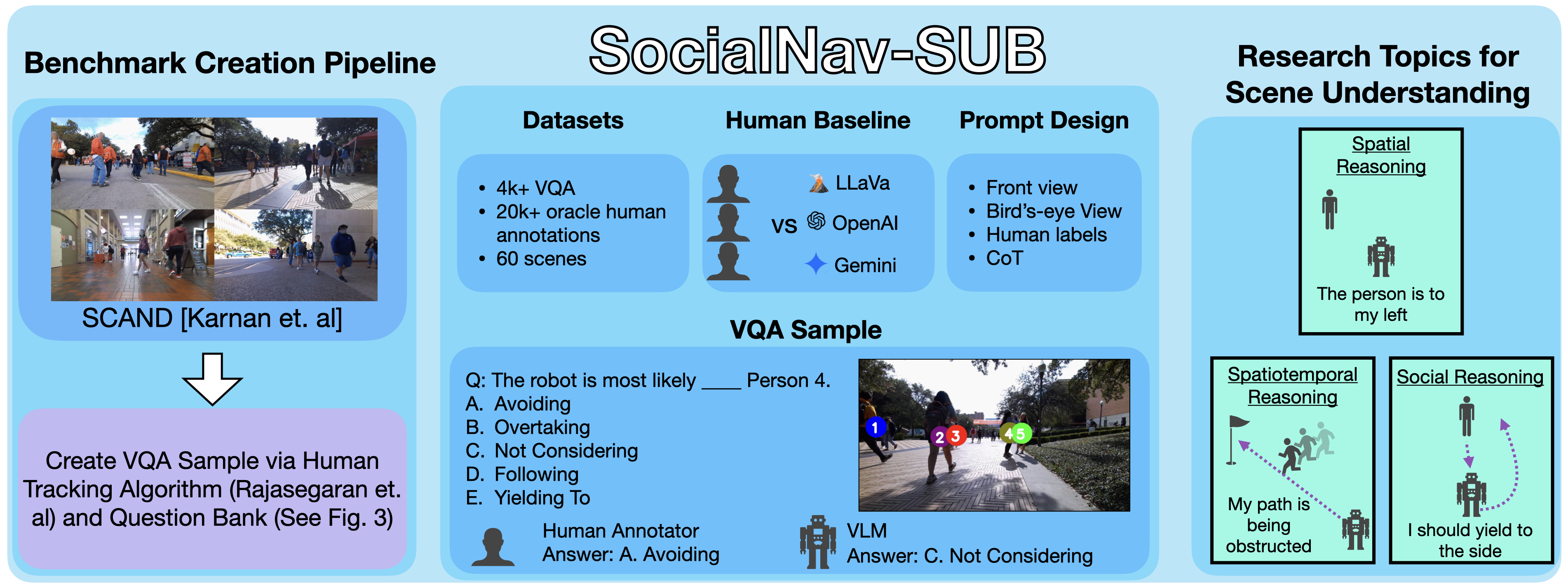
技术框架:SocialNav-SUB基准包含一个VQA数据集和一个评估框架。该数据集包含真实社交机器人导航场景的图像或视频,以及针对这些场景提出的问题。问题涵盖空间推理(例如,物体的位置关系)、时空推理(例如,智能体的运动轨迹)和社会推理(例如,人类的意图)。评估框架提供了一套指标,用于衡量VLM回答问题的准确性和一致性。基准还包括人类和基于规则的基线,用于比较VLM的性能。
关键创新:SocialNav-SUB的关键创新在于其专注于评估VLM在社交机器人导航场景中的场景理解能力。与现有的VQA数据集不同,SocialNav-SUB专门设计用于测试VLM在空间、时空和社会推理方面的能力,这些能力对于社交机器人导航至关重要。此外,SocialNav-SUB提供了一个统一的框架,用于评估VLM与人类和基于规则的基线进行比较,从而可以更全面地了解VLM的性能。
关键设计:SocialNav-SUB数据集中的问题设计需要仔细考虑,以确保它们能够有效地测试VLM在空间、时空和社会推理方面的能力。问题类型包括:定位特定对象或代理,预测代理的未来位置,推断代理的意图,以及理解场景中的社交规范。数据集的规模和多样性也很重要,以确保评估结果的可靠性和泛化能力。评估指标的选择需要能够准确地反映VLM的场景理解能力,例如准确率、召回率和F1分数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,虽然最先进的VLM在与人类答案达成一致方面取得了令人鼓舞的概率,但仍然不如简单的基于规则的方法和人类共识基线。这表明当前VLM在社交场景理解方面存在关键差距,例如在理解人类意图和预测智能体行为方面。该基准为进一步研究社交机器人导航的基础模型奠定了基础。
🎯 应用场景
该研究成果可应用于社交机器人、自动驾驶、智能监控等领域。通过提升VLM对复杂社交场景的理解能力,可以使机器人在与人类交互时更加自然、安全和高效。未来,该基准可以促进VLM在社交机器人导航领域的应用,并推动相关技术的发展。
📄 摘要(原文)
Robot navigation in dynamic, human-centered environments requires socially-compliant decisions grounded in robust scene understanding. Recent Vision-Language Models (VLMs) exhibit promising capabilities such as object recognition, common-sense reasoning, and contextual understanding-capabilities that align with the nuanced requirements of social robot navigation. However, it remains unclear whether VLMs can accurately understand complex social navigation scenes (e.g., inferring the spatial-temporal relations among agents and human intentions), which is essential for safe and socially compliant robot navigation. While some recent works have explored the use of VLMs in social robot navigation, no existing work systematically evaluates their ability to meet these necessary conditions. In this paper, we introduce the Social Navigation Scene Understanding Benchmark (SocialNav-SUB), a Visual Question Answering (VQA) dataset and benchmark designed to evaluate VLMs for scene understanding in real-world social robot navigation scenarios. SocialNav-SUB provides a unified framework for evaluating VLMs against human and rule-based baselines across VQA tasks requiring spatial, spatiotemporal, and social reasoning in social robot navigation. Through experiments with state-of-the-art VLMs, we find that while the best-performing VLM achieves an encouraging probability of agreeing with human answers, it still underperforms simpler rule-based approach and human consensus baselines, indicating critical gaps in social scene understanding of current VLMs. Our benchmark sets the stage for further research on foundation models for social robot navigation, offering a framework to explore how VLMs can be tailored to meet real-world social robot navigation needs. An overview of this paper along with the code and data can be found at https://larg.github.io/socialnav-sub .