PegasusFlow: Parallel Rolling-Denoising Score Sampling for Robot Diffusion Planner Flow Matching
作者: Lei Ye, Haibo Gao, Peng Xu, Zhelin Zhang, Junqi Shan, Ao Zhang, Wei Zhang, Ruyi Zhou, Zongquan Deng, Liang Ding
分类: cs.RO
发布日期: 2025-09-10
备注: 8 pages, 7 figures, conference paper
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
PegasusFlow:基于并行滚动降噪分数采样的机器人扩散规划器流匹配
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人轨迹规划 扩散模型 分数匹配 强化学习 并行仿真 滚动降噪 加权基函数优化 环境交互
📋 核心要点
- 传统机器人轨迹规划依赖专家数据进行模仿学习,数据获取困难且训练流程效率低下。
- PegasusFlow通过分层滚动降噪框架,直接从环境交互中并行采样轨迹分数梯度,无需专家数据。
- 提出的加权基函数优化(WBFO)算法,结合并行仿真架构,在复杂任务中显著优于现有方法。
📝 摘要(中文)
扩散模型在机器人轨迹规划中展现了强大的生成能力,但其在机器人上的实际部署受到严重瓶颈的限制:依赖于专家演示的模仿学习。这种范式对于数据稀缺的专用机器人来说通常是不切实际的,并且创建了一个低效、理论上非最优的训练流程。为了克服这个问题,我们引入了PegasusFlow,一个分层滚动降噪框架,它能够直接且并行地从环境交互中采样轨迹分数梯度,完全绕过了对专家数据的需求。我们的核心创新是一种新的采样算法,加权基函数优化(WBFO),它利用样条基表示来实现优于传统方法(如MPPI)的采样效率和更快的收敛速度。该框架嵌入在一个可扩展的异步并行仿真架构中,该架构支持大规模并行rollout以实现高效的数据收集。在轨迹优化和机器人导航任务上的大量实验表明,我们的方法,特别是结合了强化学习warm-start的Action-Value WBFO(AVWBFO),明显优于基线。在一个具有挑战性的跨越障碍物任务中,我们的方法实现了100%的成功率,并且比次优方法快18%,验证了其在复杂地形运动规划中的有效性。
🔬 方法详解
问题定义:现有机器人轨迹规划方法严重依赖专家数据进行模仿学习,这在数据稀缺的场景下(例如,特定类型的机器人或复杂环境)变得不可行。此外,模仿学习的训练流程通常效率低下,且理论上并非最优,因为它试图模仿专家行为,而不是直接优化任务目标。因此,需要一种能够直接从环境交互中学习,而无需专家数据的轨迹规划方法。
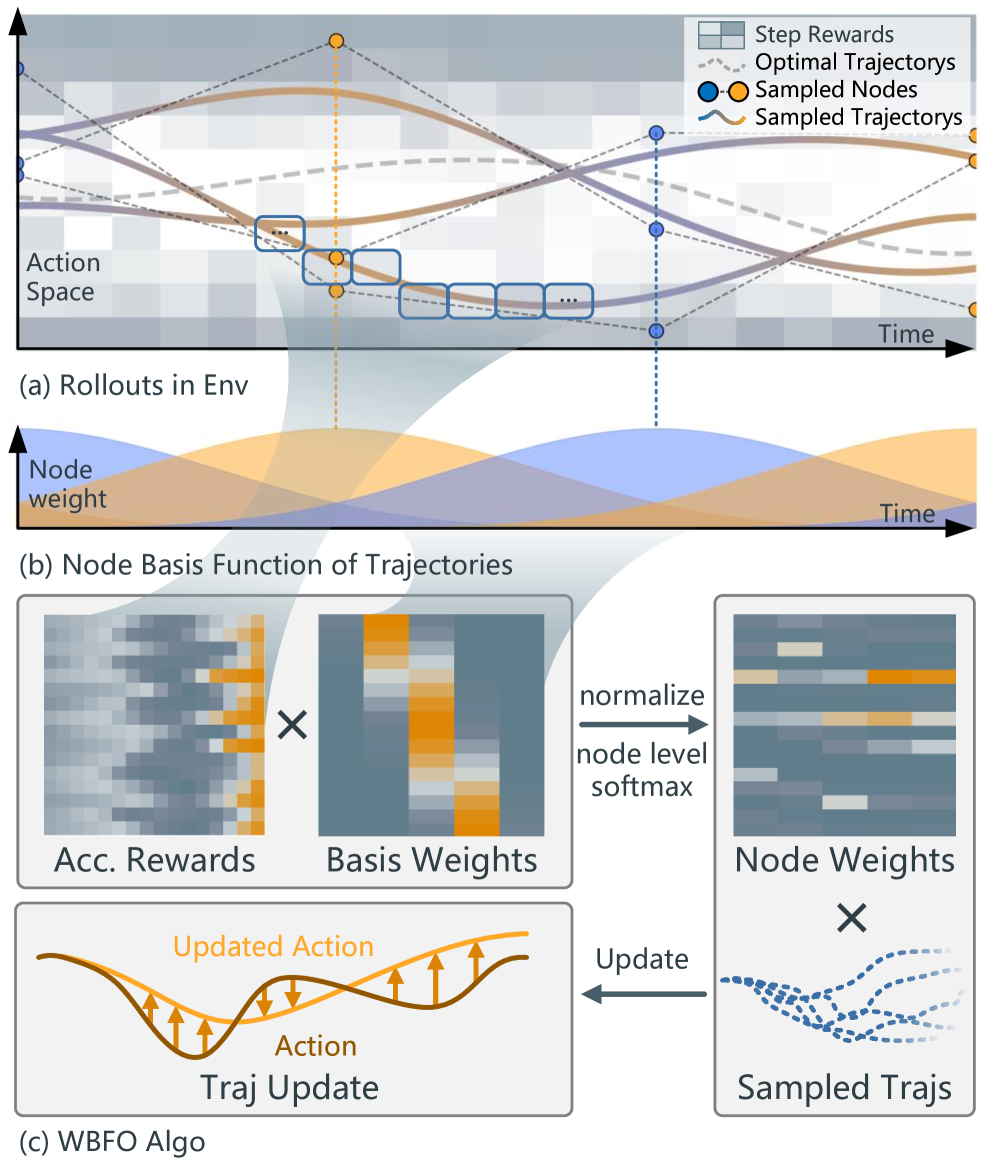
核心思路:PegasusFlow的核心思路是通过扩散模型生成轨迹,并利用分数匹配(Score Matching)来学习轨迹的梯度场。关键在于如何高效地从环境中采样轨迹梯度,并利用这些梯度来改进轨迹。为了解决采样效率问题,论文提出了加权基函数优化(WBFO)算法,该算法利用样条基函数来表示轨迹,从而减少了需要优化的参数数量,提高了采样效率。
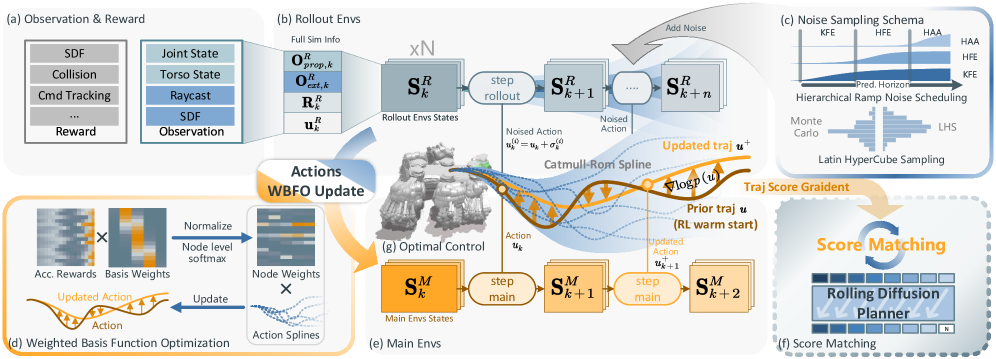
技术框架:PegasusFlow的整体框架是一个分层滚动降噪框架。首先,使用扩散模型生成初始轨迹。然后,通过滚动降噪过程,逐步优化轨迹。在每次滚动中,使用WBFO算法从环境中采样轨迹梯度,并利用这些梯度来更新轨迹。为了提高数据收集效率,该框架采用异步并行仿真架构,支持大规模并行rollout。该框架包含以下主要模块:扩散模型、分数匹配模块、WBFO采样模块和并行仿真模块。
关键创新:PegasusFlow的关键创新在于以下几个方面:1) 提出了分层滚动降噪框架,能够直接从环境交互中学习轨迹梯度,无需专家数据。2) 提出了加权基函数优化(WBFO)算法,利用样条基函数表示轨迹,提高了采样效率和收敛速度。3) 采用了异步并行仿真架构,支持大规模并行rollout,进一步提高了数据收集效率。与现有方法的本质区别在于,PegasusFlow是一种基于环境交互的直接学习方法,而现有方法大多是基于专家数据的模仿学习方法。
关键设计:WBFO算法的关键设计包括:1) 使用样条基函数来表示轨迹,减少了需要优化的参数数量。2) 使用加权策略来平衡不同基函数的重要性。3) 结合了Action-Value函数,进一步提高了采样效率。并行仿真架构的关键设计包括:1) 采用异步通信机制,避免了同步等待造成的性能瓶颈。2) 使用高效的仿真引擎,提高了仿真速度。损失函数主要包括分数匹配损失和强化学习损失(如果使用强化学习warm-start)。
🖼️ 关键图片
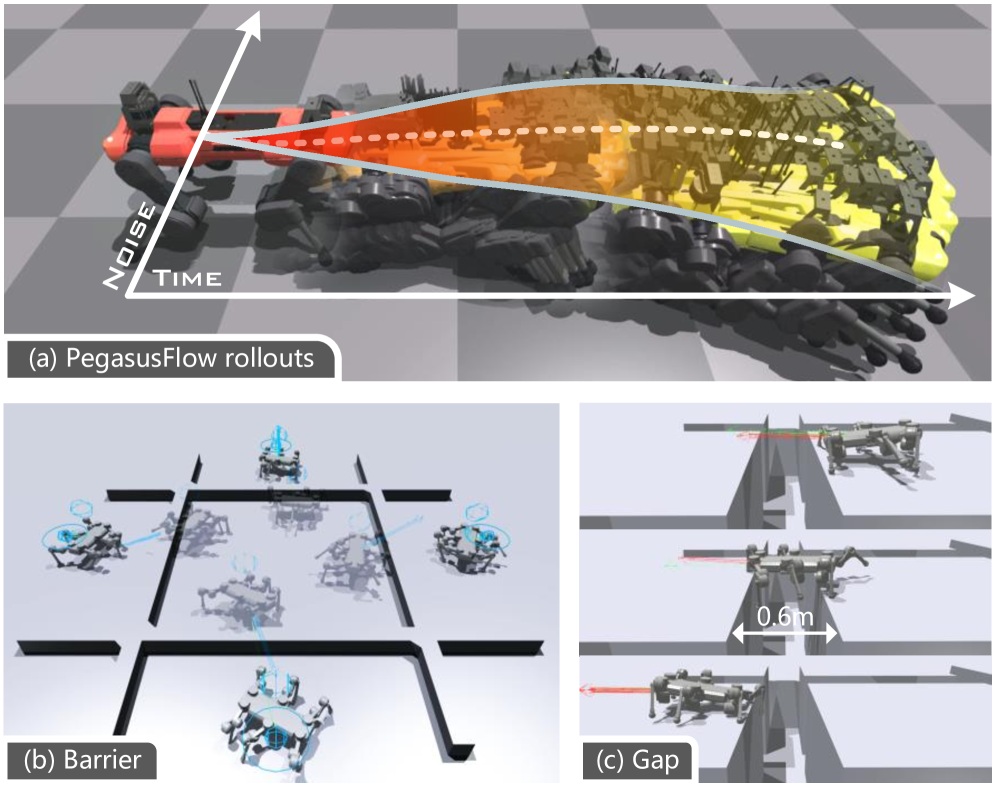
📊 实验亮点
实验结果表明,PegasusFlow在轨迹优化和机器人导航任务中显著优于基线方法。在具有挑战性的跨越障碍物任务中,PegasusFlow实现了100%的成功率,并且比次优方法快18%。Action-Value WBFO(AVWBFO)结合强化学习warm-start,进一步提升了性能。这些结果验证了PegasusFlow在复杂环境下的有效性和优越性。
🎯 应用场景
PegasusFlow具有广泛的应用前景,可应用于各种机器人轨迹规划任务,例如:复杂地形导航、物体抓取、装配等。该研究的实际价值在于降低了机器人轨迹规划对专家数据的依赖,使得机器人能够更好地适应未知环境。未来,该方法有望应用于自动驾驶、智能制造等领域,推动机器人技术的进一步发展。
📄 摘要(原文)
Diffusion models offer powerful generative capabilities for robot trajectory planning, yet their practical deployment on robots is hindered by a critical bottleneck: a reliance on imitation learning from expert demonstrations. This paradigm is often impractical for specialized robots where data is scarce and creates an inefficient, theoretically suboptimal training pipeline. To overcome this, we introduce PegasusFlow, a hierarchical rolling-denoising framework that enables direct and parallel sampling of trajectory score gradients from environmental interaction, completely bypassing the need for expert data. Our core innovation is a novel sampling algorithm, Weighted Basis Function Optimization (WBFO), which leverages spline basis representations to achieve superior sample efficiency and faster convergence compared to traditional methods like MPPI. The framework is embedded within a scalable, asynchronous parallel simulation architecture that supports massively parallel rollouts for efficient data collection. Extensive experiments on trajectory optimization and robotic navigation tasks demonstrate that our approach, particularly Action-Value WBFO (AVWBFO) combined with a reinforcement learning warm-start, significantly outperforms baselines. In a challenging barrier-crossing task, our method achieved a 100% success rate and was 18% faster than the next-best method, validating its effectiveness for complex terrain locomotion planning. https://masteryip.github.io/pegasusflow.github.io/