TA-VLA: Elucidating the Design Space of Torque-aware Vision-Language-Action Models
作者: Zongzheng Zhang, Haobo Xu, Zhuo Yang, Chenghao Yue, Zehao Lin, Huan-ang Gao, Ziwei Wang, Hao Zhao
分类: cs.RO
发布日期: 2025-09-09
备注: Accepted to CoRL 2025, project page: \url{https://zzongzheng0918.github.io/Torque-Aware-VLA.github.io/}
💡 一句话要点
提出扭矩感知视觉-语言-动作模型(TA-VLA),提升机器人操作中力觉反馈利用率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作模型 扭矩感知 力觉反馈 辅助任务学习
📋 核心要点
- 现有VLA模型难以有效利用力/扭矩等物理反馈信号,限制了其在复杂操作任务中的应用。
- 通过系统研究扭矩信号在VLA架构中的集成方式,探索了多种策略,并提出了扭矩预测辅助任务。
- 实验表明,在解码器中引入扭矩适配器效果更佳,且扭矩预测辅助任务能显著提升模型性能。
📝 摘要(中文)
许多机器人操作任务需要感知和响应力信号,例如扭矩,以评估任务是否成功完成并实现闭环控制。然而,当前的视觉-语言-动作(VLA)模型缺乏整合这种细微物理反馈的能力。本文探索了扭矩感知VLA模型,旨在通过系统地研究将扭矩信号整合到现有VLA架构中的设计空间来弥合这一差距。我们识别并评估了几种策略,得出了三个关键发现。首先,将扭矩适配器引入解码器始终优于将其插入编码器。其次,受自动驾驶中联合预测和规划范式的启发,我们提出预测扭矩作为辅助输出,这进一步提高了性能。这种策略鼓励模型构建一个物理上扎实的交互动力学内部表示。在接触丰富的操作基准上的大量定量和定性实验验证了我们的发现。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在处理需要精细力觉反馈的机器人操作任务时表现不足。这些任务通常依赖于扭矩等力信号来判断操作是否成功或进行闭环控制。然而,现有模型无法有效地整合这些物理反馈信号,导致操作精度和鲁棒性受限。因此,该论文旨在解决VLA模型缺乏力觉感知能力的问题。
核心思路:该论文的核心思路是通过系统地研究如何将扭矩信号有效地融入现有的VLA架构中,从而提升模型对物理交互的理解和预测能力。作者没有直接设计全新的模型,而是探索了多种集成策略,并分析了它们对模型性能的影响。此外,作者还借鉴了自动驾驶领域的联合预测和规划思想,将扭矩预测作为一个辅助任务,以增强模型对交互动力学的建模能力。
技术框架:该论文主要研究了在VLA模型的编码器和解码器中集成扭矩信息的不同方式。具体来说,作者探索了将扭矩适配器插入到编码器或解码器的不同层级,并比较了它们的效果。此外,作者还引入了一个辅助的扭矩预测任务,该任务要求模型根据视觉和语言输入预测未来的扭矩信号。整个框架可以分为三个主要部分:视觉和语言编码器、扭矩适配器(可选)、动作解码器和扭矩预测模块(可选)。
关键创新:该论文的关键创新在于对扭矩感知VLA模型的设计空间进行了系统性的探索。通过对比不同的扭矩集成策略,作者发现将扭矩适配器插入到解码器中效果更好。此外,将扭矩预测作为辅助任务是另一个重要的创新点,它可以有效地提升模型对交互动力学的理解,从而提高操作性能。这种方法鼓励模型学习一个物理上更合理的内部表示。
关键设计:论文的关键设计包括:1) 扭矩适配器的具体结构(未知,论文中可能未详细描述);2) 扭矩预测任务的损失函数设计(例如,可以使用均方误差或交叉熵损失);3) 扭矩适配器在解码器中的插入位置(需要实验确定最佳位置);4) 辅助扭矩预测任务的权重设置(需要通过实验调整)。
🖼️ 关键图片
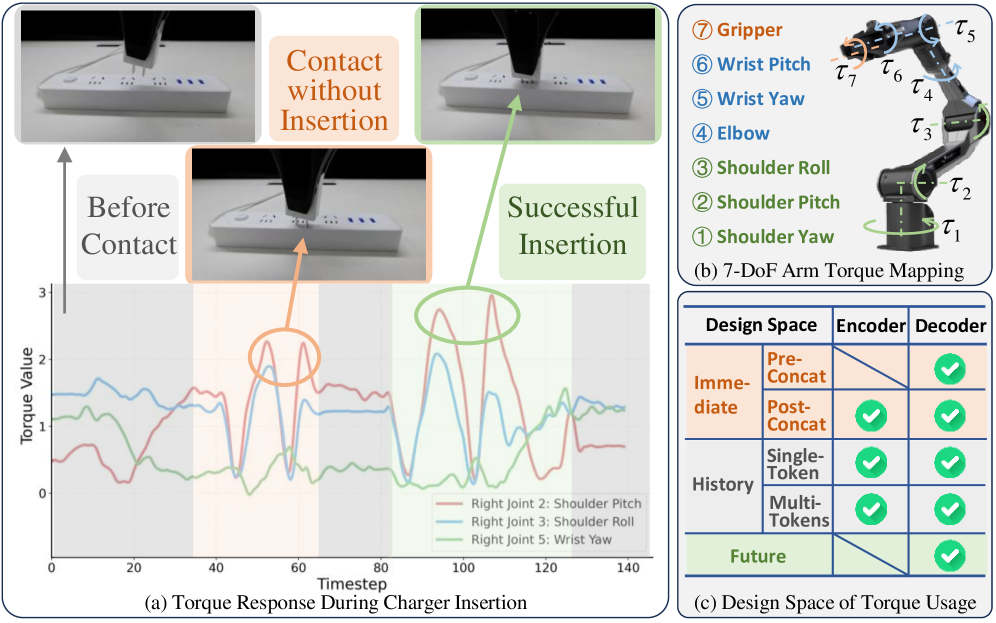
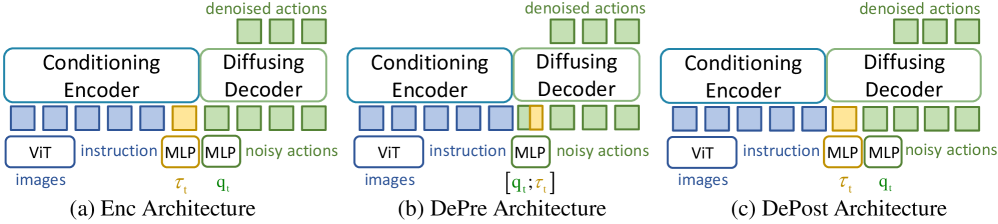
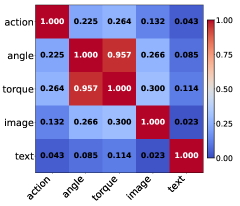
📊 实验亮点
实验结果表明,将扭矩适配器插入解码器优于插入编码器。引入扭矩预测作为辅助任务能进一步提升性能,验证了模型构建物理交互内部表示的有效性。具体性能提升数据和对比基线信息在摘要中未提供,需查阅论文全文。
🎯 应用场景
该研究成果可应用于各种需要精细操作和力觉反馈的机器人任务,例如装配、抓取、医疗手术等。通过提升机器人对物理交互的理解能力,可以提高操作的精度、鲁棒性和安全性。未来,该技术有望应用于更复杂的机器人系统中,例如人机协作机器人和自主操作机器人。
📄 摘要(原文)
Many robotic manipulation tasks require sensing and responding to force signals such as torque to assess whether the task has been successfully completed and to enable closed-loop control. However, current Vision-Language-Action (VLA) models lack the ability to integrate such subtle physical feedback. In this work, we explore Torque-aware VLA models, aiming to bridge this gap by systematically studying the design space for incorporating torque signals into existing VLA architectures. We identify and evaluate several strategies, leading to three key findings. First, introducing torque adapters into the decoder consistently outperforms inserting them into the encoder.Third, inspired by joint prediction and planning paradigms in autonomous driving, we propose predicting torque as an auxiliary output, which further improves performance. This strategy encourages the model to build a physically grounded internal representation of interaction dynamics. Extensive quantitative and qualitative experiments across contact-rich manipulation benchmarks validate our findings.