Graph-Fused Vision-Language-Action for Policy Reasoning in Multi-Arm Robotic Manipulation
作者: Shunlei Li, Longsen Gao, Jiuwen Cao, Yingbai Hu
分类: cs.RO
发布日期: 2025-09-09
备注: This paper is submitted to IEEE IROS 2025 Workshop AIR4S
💡 一句话要点
提出Graph-Fused VLA框架,解决双臂机器人从人类演示视频中进行策略推理的问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 双臂机器人 策略推理 视觉语言动作 场景图 机器人学习
📋 核心要点
- 传统方法依赖于低级轨迹复制,难以应对不同物体、空间布局和机械臂配置的变化,限制了机器人技能的泛化能力。
- GF-VLA框架通过信息论方法提取关键交互线索,构建时序场景图,并结合语言条件Transformer生成分层行为树和运动原语。
- 实验表明,GF-VLA在双臂任务中实现了高图准确率和子任务分割准确率,并成功部署于真实机器人,表现出良好的泛化性和鲁棒性。
📝 摘要(中文)
本文提出了一种名为Graph-Fused Vision-Language-Action (GF-VLA) 的统一框架,旨在使双臂机器人系统能够直接从RGB-D人类演示中执行任务级推理和执行。GF-VLA采用信息论方法提取任务相关线索,选择性地突出关键的手-物和物-物交互。这些线索被构建成时间排序的场景图,然后与语言条件Transformer集成,以生成分层行为树和可解释的笛卡尔运动原语。为了提高双手动执行的效率,本文提出了一种跨臂分配策略,该策略可自动确定夹具分配,而无需显式的几何建模。在涉及符号结构构建和空间泛化的四个双臂块组装基准上验证了GF-VLA。实验结果表明,所提出的表示实现了超过95%的图准确率和93%的子任务分割准确率,使语言-动作规划器能够生成鲁棒、可解释的任务策略。在双臂机器人上部署时,这些策略在堆叠、字母形成和几何重构任务中实现了94%的抓取可靠性、89%的放置准确性和90%的总体任务成功率,证明了在各种空间和语义变化下的强大泛化性和鲁棒性。
🔬 方法详解
问题定义:现有机器人技能学习方法,特别是从人类演示视频中学习,通常依赖于低级轨迹复制。这种方法难以泛化到新的物体、场景布局和机器人配置,限制了机器人在复杂环境中的应用。因此,需要一种能够进行任务级推理和执行的方法,使机器人能够理解并适应不同的任务需求。
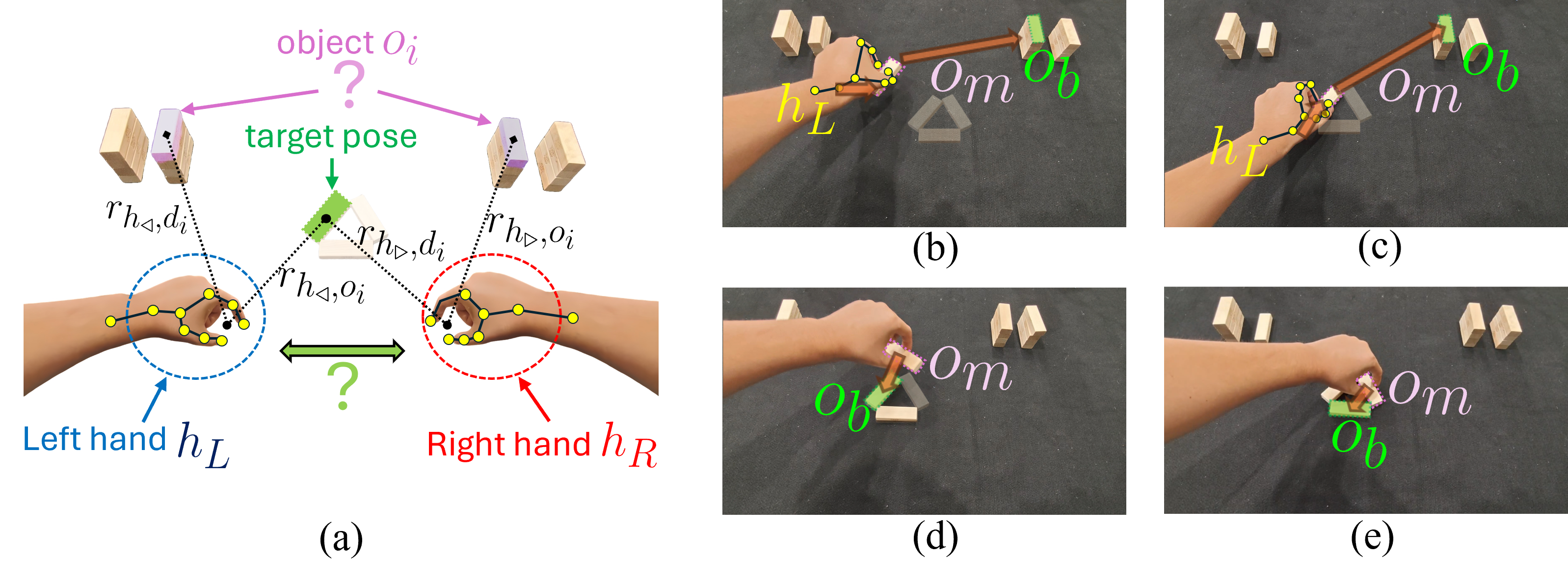
核心思路:GF-VLA的核心思路是将视觉信息、语言信息和动作信息融合到一个统一的框架中,利用图结构来表示场景中的对象及其交互关系,并通过语言条件Transformer来生成可解释的任务策略。这种方法能够提取任务相关的关键线索,并将其转化为机器人可以理解和执行的动作序列。
技术框架:GF-VLA框架主要包含以下几个模块:1) 视觉信息提取模块,用于从RGB-D视频中提取场景中的对象及其属性;2) 场景图构建模块,用于将提取的对象和交互关系构建成时间排序的场景图;3) 语言条件Transformer模块,用于将场景图和语言指令作为输入,生成分层行为树和笛卡尔运动原语;4) 跨臂分配策略模块,用于自动确定双臂机器人的夹具分配。
关键创新:GF-VLA的关键创新在于:1) 使用信息论方法提取任务相关的关键交互线索,提高了场景图的表示效率;2) 将场景图与语言条件Transformer相结合,实现了任务级推理和执行;3) 提出了一种跨臂分配策略,提高了双手动执行的效率。与现有方法相比,GF-VLA能够更好地理解任务需求,并生成更鲁棒、可解释的任务策略。
关键设计:在场景图构建模块中,使用了信息增益来选择关键的交互关系。语言条件Transformer采用了标准的Transformer结构,并使用交叉注意力机制来融合场景图和语言指令的信息。跨臂分配策略基于启发式规则,并考虑了夹具的可达性和稳定性。
🖼️ 关键图片


📊 实验亮点
GF-VLA在四个双臂块组装基准上进行了验证,实现了超过95%的图准确率和93%的子任务分割准确率。在真实机器人上的实验表明,该方法在堆叠、字母形成和几何重构任务中实现了94%的抓取可靠性、89%的放置准确性和90%的总体任务成功率,证明了其在不同空间和语义变化下的强大泛化性和鲁棒性。
🎯 应用场景
该研究成果可应用于各种需要双臂协作的机器人任务,例如:自动化装配、医疗手术、家庭服务等。通过从人类演示中学习,机器人可以快速掌握新的技能,并适应不同的工作环境,从而提高生产效率和服务质量。未来,该技术有望进一步扩展到更复杂的任务和更广泛的应用领域。
📄 摘要(原文)
Acquiring dexterous robotic skills from human video demonstrations remains a significant challenge, largely due to conventional reliance on low-level trajectory replication, which often fails to generalize across varying objects, spatial layouts, and manipulator configurations. To address this limitation, we introduce Graph-Fused Vision-Language-Action (GF-VLA), a unified framework that enables dual-arm robotic systems to perform task-level reasoning and execution directly from RGB-D human demonstrations. GF-VLA employs an information-theoretic approach to extract task-relevant cues, selectively highlighting critical hand-object and object-object interactions. These cues are structured into temporally ordered scene graphs, which are subsequently integrated with a language-conditioned transformer to produce hierarchical behavior trees and interpretable Cartesian motion primitives. To enhance efficiency in bimanual execution, we propose a cross-arm allocation strategy that autonomously determines gripper assignment without requiring explicit geometric modeling. We validate GF-VLA on four dual-arm block assembly benchmarks involving symbolic structure construction and spatial generalization. Empirical results demonstrate that the proposed representation achieves over 95% graph accuracy and 93% subtask segmentation, enabling the language-action planner to generate robust, interpretable task policies. When deployed on a dual-arm robot, these policies attain 94% grasp reliability, 89% placement accuracy, and 90% overall task success across stacking, letter-formation, and geometric reconfiguration tasks, evidencing strong generalization and robustness under diverse spatial and semantic variations.