RaC: Robot Learning for Long-Horizon Tasks by Scaling Recovery and Correction
作者: Zheyuan Hu, Robyn Wu, Naveen Enock, Jasmine Li, Riya Kadakia, Zackory Erickson, Aviral Kumar
分类: cs.RO, cs.LG
发布日期: 2025-09-09
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
RaC:通过扩展恢复与纠正能力实现机器人长时程任务学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人学习 模仿学习 人机协作 长时程任务 恢复与纠正
📋 核心要点
- 现有机器人模仿学习方法在长时程任务中,即使有大量专家数据,也难以达到理想性能,主要瓶颈在于专家数据收集效率低。
- RaC方法通过引入人机协作训练阶段,利用人类干预轨迹中的恢复和纠正行为,扩展机器人技能库,使其具备重试和适应能力。
- 实验表明,RaC在真实世界的操作任务中,仅用十分之一的数据量,性能就超越了现有技术,并且策略性能随恢复操作次数线性提升。
📝 摘要(中文)
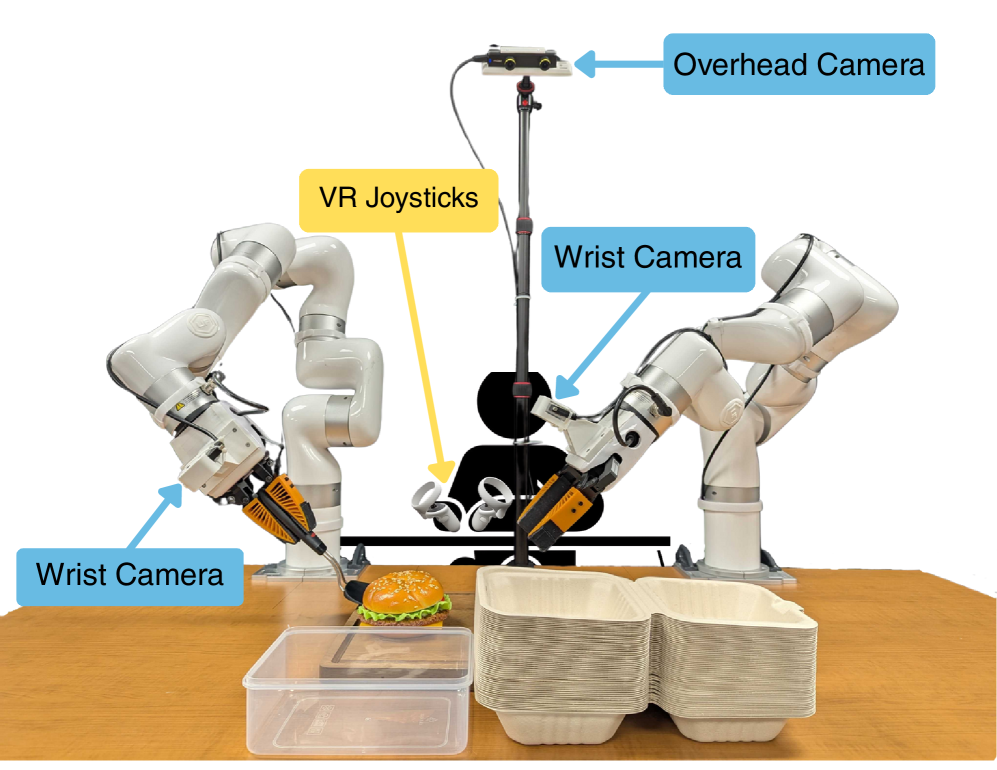
现有的机器人模仿学习方法在大量人类演示数据上训练具有表达能力的策略架构。然而,即使使用数千个专家演示,在富接触、可变形对象和长时程任务上的性能也远低于完美执行。这是由于现有基于人类遥操作的“专家”数据收集程序效率低下。为了解决这个问题,我们引入了RaC,这是一种在模仿学习预训练后,在人机协作的rollout上进行训练的新阶段。在RaC中,我们在人类干预轨迹上微调机器人策略,这些轨迹展示了恢复和纠正行为。具体来说,在策略rollout期间,当失败似乎迫在眉睫时,人类操作员会进行干预,首先将机器人倒回到熟悉的、分布内的状态,然后提供一个完成当前子任务的纠正片段。训练这种数据组合扩展了机器人的技能库,使其包括重试和适应行为,我们表明这对于提高长时程任务的效率和鲁棒性至关重要。在三个真实世界的双手控制任务中:衬衫悬挂、气密容器盖密封、外卖盒包装和一个模拟组装任务,RaC优于先前的最先进水平,使用的数据收集时间和样本减少了10倍。我们还表明,RaC支持测试时扩展:训练后的RaC策略的性能与其表现出的恢复操作次数呈线性关系。学习策略的视频可在https://rac-scaling-robot.github.io/上找到。
🔬 方法详解
问题定义:论文旨在解决机器人模仿学习在长时程、富接触任务中,由于专家数据收集效率低下导致的性能瓶颈问题。现有方法依赖大量人工演示数据,但即使如此,机器人仍然难以从错误中恢复,并适应环境变化,导致任务完成率低。现有方法的痛点在于缺乏有效的机制来学习从失败中恢复和纠正的能力。
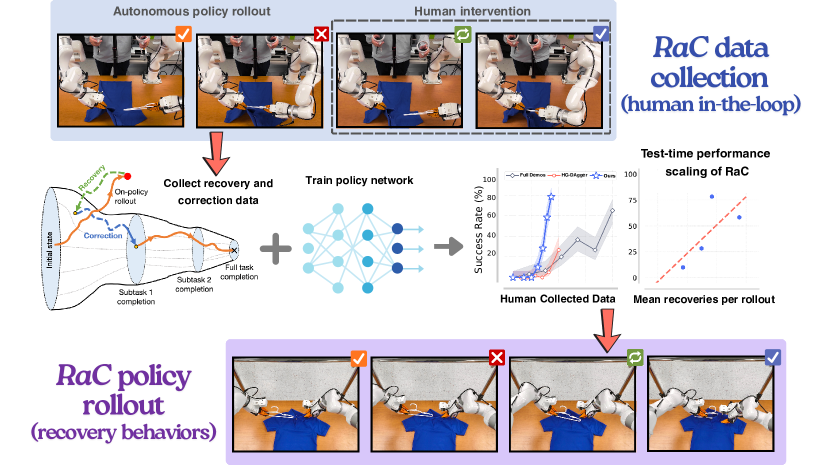
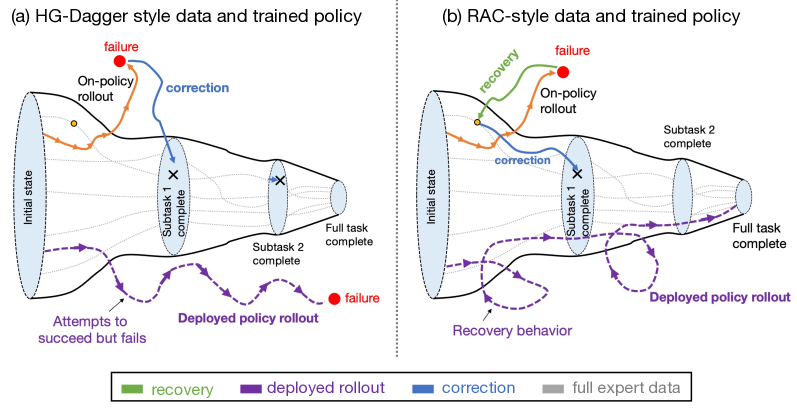
核心思路:论文的核心思路是利用人机协作,在机器人策略执行过程中,当机器人即将失败时,由人类操作员进行干预,将机器人回退到安全状态,并提供纠正动作,从而让机器人学习恢复和纠正行为。这种方法能够有效地扩展机器人的技能库,使其具备重试和适应能力,从而提高长时程任务的成功率。
技术框架:RaC方法包含两个主要阶段:1) 模仿学习预训练阶段:使用人类演示数据训练一个初始机器人策略。2) 人机协作训练阶段:机器人执行任务,当预测到即将失败时,人类操作员介入,将机器人回退到安全状态,并提供纠正动作。这些干预轨迹被用于微调机器人策略。整个流程可以看作是一个迭代的过程,机器人不断尝试,人类不断纠正,最终使机器人学会完成任务。
关键创新:RaC方法的关键创新在于引入了人机协作的训练范式,利用人类的先验知识和纠错能力,有效地解决了机器人从失败中学习的问题。与传统的模仿学习方法相比,RaC方法能够更有效地利用数据,并且能够学习到更鲁棒的策略。此外,RaC方法还支持测试时扩展,即策略的性能随着恢复操作次数的增加而线性提升。
关键设计:RaC方法的关键设计包括:1) 人类干预策略:需要设计合理的干预策略,例如何时进行干预,如何将机器人回退到安全状态,以及如何提供纠正动作。2) 数据增强方法:需要设计有效的数据增强方法,以提高策略的泛化能力。3) 损失函数设计:需要设计合适的损失函数,以鼓励机器人学习恢复和纠正行为。论文中具体使用的损失函数和网络结构等细节未明确给出,属于未知信息。
🖼️ 关键图片
📊 实验亮点
RaC方法在三个真实世界的双手控制任务(衬衫悬挂、气密容器盖密封、外卖盒包装)和一个模拟组装任务中,均优于先前的最先进水平,并且使用的数据收集时间和样本减少了10倍。此外,实验还表明,训练后的RaC策略的性能与其表现出的恢复操作次数呈线性关系,验证了该方法的可扩展性。
🎯 应用场景
RaC方法具有广泛的应用前景,可以应用于各种需要机器人进行长时程操作的场景,例如:工业自动化、家庭服务、医疗手术等。该方法能够提高机器人的鲁棒性和适应性,使其能够更好地应对复杂和不确定的环境,从而提高工作效率和安全性。未来,RaC方法有望成为机器人学习领域的重要技术手段。
📄 摘要(原文)
Modern paradigms for robot imitation train expressive policy architectures on large amounts of human demonstration data. Yet performance on contact-rich, deformable-object, and long-horizon tasks plateau far below perfect execution, even with thousands of expert demonstrations. This is due to the inefficiency of existing ``expert'' data collection procedures based on human teleoperation. To address this issue, we introduce RaC, a new phase of training on human-in-the-loop rollouts after imitation learning pre-training. In RaC, we fine-tune a robotic policy on human intervention trajectories that illustrate recovery and correction behaviors. Specifically, during a policy rollout, human operators intervene when failure appears imminent, first rewinding the robot back to a familiar, in-distribution state and then providing a corrective segment that completes the current sub-task. Training on this data composition expands the robotic skill repertoire to include retry and adaptation behaviors, which we show are crucial for boosting both efficiency and robustness on long-horizon tasks. Across three real-world bimanual control tasks: shirt hanging, airtight container lid sealing, takeout box packing, and a simulated assembly task, RaC outperforms the prior state-of-the-art using 10$\times$ less data collection time and samples. We also show that RaC enables test-time scaling: the performance of the trained RaC policy scales linearly in the number of recovery maneuvers it exhibits. Videos of the learned policy are available at https://rac-scaling-robot.github.io/.