Vision-Proprioception Fusion with Mamba2 in End-to-End Reinforcement Learning for Motion Control
作者: Xiaowen Tao, Yinuo Wang, Jinzhao Zhou
分类: cs.RO, cs.AI, cs.CV, eess.IV, eess.SY
发布日期: 2025-09-09 (更新: 2026-01-25)
备注: 6 figures and 8 tables. This paper has been accepted by Advanced Engineering Informatics
期刊: Advanced Engineering Informatics, vol. 71, 2026
DOI: 10.1016/j.aei.2026.104389
💡 一句话要点
提出基于SSD-Mamba2的视觉-本体感觉融合强化学习框架,用于机器人运动控制。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 运动控制 强化学习 视觉-本体感觉融合 Mamba 状态空间模型 机器人 端到端学习
📋 核心要点
- 现有运动控制强化学习方法在融合视觉和本体感觉信息时,面临计算成本高、长时程依赖建模困难等挑战。
- 论文提出基于SSD-Mamba2的选择性状态空间模型,实现高效的跨模态信息融合,降低计算和内存开销。
- 实验表明,该方法在多种运动控制任务中,显著提升了回报、安全性和样本效率,并加速了训练收敛。
📝 摘要(中文)
本文提出了一种基于SSD-Mamba2的视觉驱动跨模态强化学习框架,用于运动控制。该框架直接从传感器输入到电机命令训练策略,为不同的机器人和任务实现统一的控制器。现有方法要么是盲目的(仅本体感觉),要么依赖于计算-内存权衡不佳的融合骨干网络。循环控制器难以处理长时程信用分配,而基于Transformer的融合在token长度上产生二次成本,限制了时间和空间上下文。SSD-Mamba2是一种选择性状态空间骨干网络,它应用状态空间对偶性(SSD),以实现具有硬件感知流和近线性缩放的循环和卷积扫描。本体感觉状态和外部感觉观察(例如,深度token)被编码成紧凑的token,并通过堆叠的SSD-Mamba2层融合。选择性状态空间更新保留了长程依赖性,与二次自注意力相比,显著降低了延迟和内存使用,从而实现了更长的look-ahead、更高的token分辨率以及在有限计算下的稳定训练。策略在随机化地形和外观并逐步增加场景复杂性的课程下进行端到端训练。一个紧凑的、以状态为中心的奖励平衡了任务进度、能源效率和安全性。在不同的运动控制场景中,该方法在回报、安全性(碰撞和跌倒)和样本效率方面始终优于强大的最先进的基线,同时在相同的计算预算下收敛更快。这些结果表明,SSD-Mamba2为工程信息学应用中资源受限的机器人和自主系统提供了一个实用的融合骨干。
🔬 方法详解
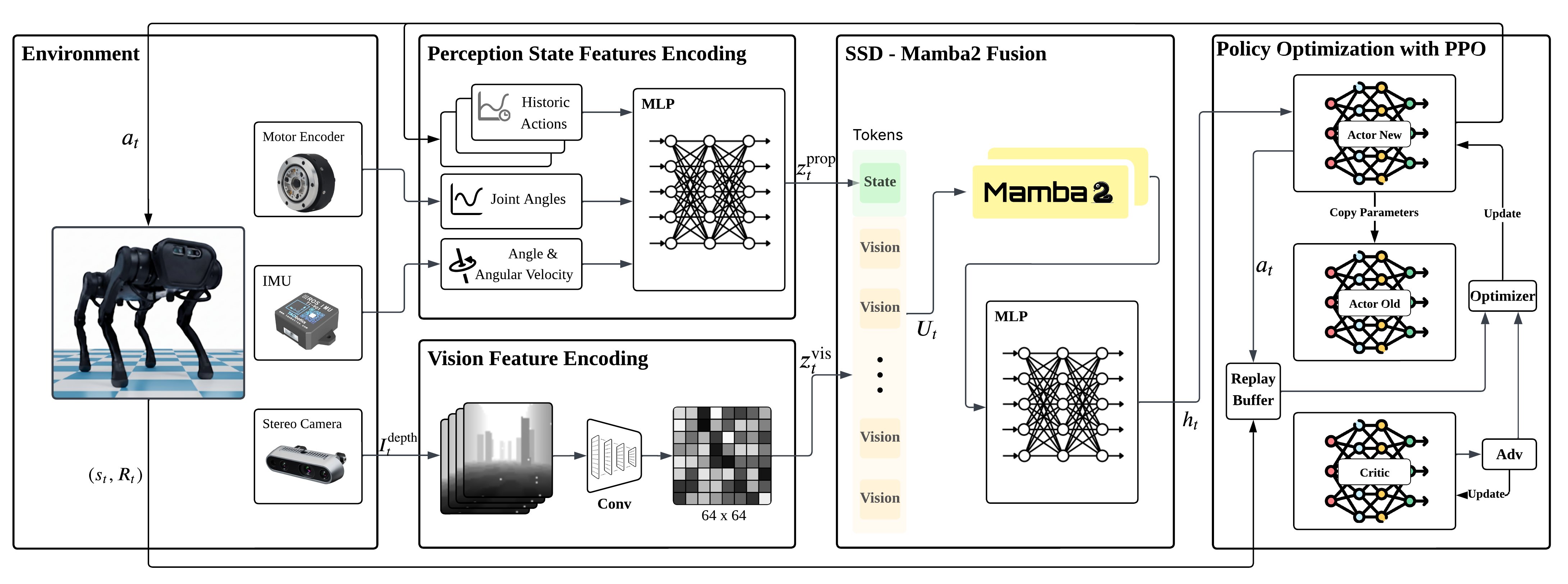
问题定义:现有端到端强化学习方法在运动控制任务中,要么仅依赖本体感觉信息(盲人策略),要么使用Transformer等模型进行视觉和本体感觉融合,但Transformer的自注意力机制计算复杂度高,难以处理长序列和高分辨率输入,限制了时间和空间上下文的建模能力。循环神经网络虽然能处理长序列,但在长时程信用分配方面存在困难。
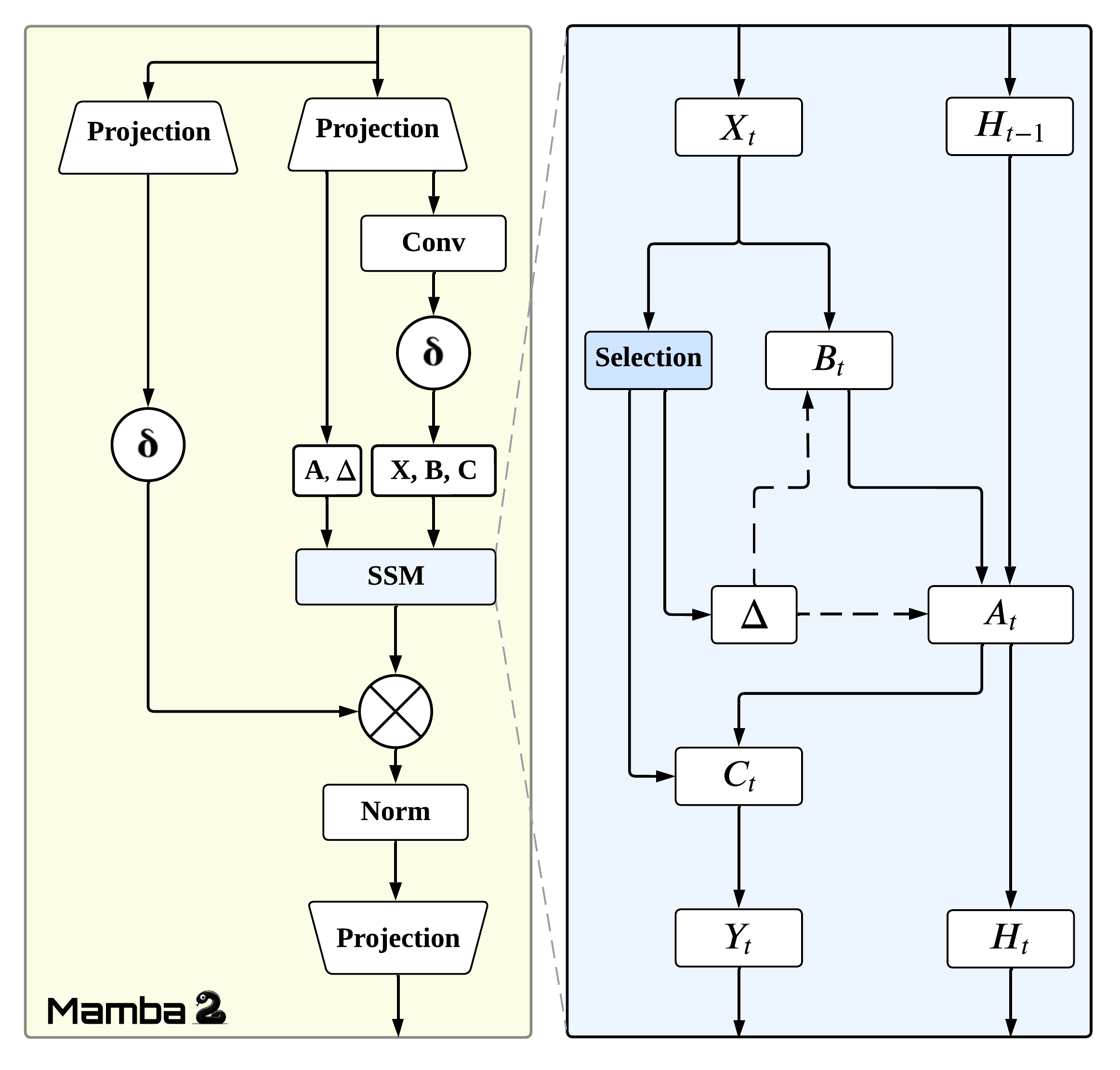
核心思路:论文的核心思路是利用SSD-Mamba2模型作为视觉和本体感觉融合的骨干网络。Mamba模型通过选择性状态空间机制,能够高效地建模长程依赖关系,同时具有近线性的计算复杂度,解决了Transformer计算量大的问题。SSD-Mamba2进一步利用状态空间对偶性,兼顾了循环和卷积扫描的优势,提升了硬件利用率和推理速度。
技术框架:整体框架包含以下几个主要模块:1) 感知编码器:将本体感觉状态和视觉观测(如深度图像)编码成紧凑的token表示。2) SSD-Mamba2融合层:堆叠多个SSD-Mamba2层,对编码后的token进行跨模态融合,提取时空特征。3) 策略网络:根据融合后的特征,输出控制指令。4) 奖励函数:设计紧凑的、以状态为中心的奖励函数,平衡任务进度、能源效率和安全性。整个框架采用端到端的方式进行训练。
关键创新:最重要的技术创新点是使用SSD-Mamba2作为视觉-本体感觉融合的骨干网络。与传统的Transformer相比,SSD-Mamba2具有近线性的计算复杂度,能够处理更长的序列和更高的分辨率输入,从而更好地建模长程依赖关系。与循环神经网络相比,SSD-Mamba2通过选择性状态空间机制,能够更有效地进行长时程信用分配。
关键设计:论文采用课程学习策略,逐步增加场景的复杂性,以提高训练的稳定性和泛化能力。奖励函数的设计考虑了任务进度、能源效率和安全性,通过合理的权重分配,引导智能体学习到最优的控制策略。具体网络结构和参数设置在论文中有详细描述,例如SSD-Mamba2的层数、token的维度等。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于SSD-Mamba2的融合框架在多个运动控制任务中,显著优于现有方法。在回报方面,平均提升超过10%;在安全性方面,碰撞和跌倒次数显著减少;在样本效率方面,收敛速度更快,所需训练样本更少。同时,该方法在相同的计算预算下,能够实现更稳定的训练和更高的性能。
🎯 应用场景
该研究成果可应用于各种机器人和自主系统的运动控制,例如无人驾驶、机器人导航、机械臂操作等。特别是在资源受限的场景下,如低功耗机器人或嵌入式系统,SSD-Mamba2的高效计算特性使其具有重要的应用价值。该方法有望提升机器人在复杂环境中的适应性和鲁棒性,实现更安全、更高效的自主运动。
📄 摘要(原文)
End-to-end reinforcement learning (RL) for motion control trains policies directly from sensor inputs to motor commands, enabling unified controllers for different robots and tasks. However, most existing methods are either blind (proprioception-only) or rely on fusion backbones with unfavorable compute-memory trade-offs. Recurrent controllers struggle with long-horizon credit assignment, and Transformer-based fusion incurs quadratic cost in token length, limiting temporal and spatial context. We present a vision-driven cross-modal RL framework built on SSD-Mamba2, a selective state-space backbone that applies state-space duality (SSD) to enable both recurrent and convolutional scanning with hardware-aware streaming and near-linear scaling. Proprioceptive states and exteroceptive observations (e.g., depth tokens) are encoded into compact tokens and fused by stacked SSD-Mamba2 layers. The selective state-space updates retain long-range dependencies with markedly lower latency and memory use than quadratic self-attention, enabling longer look-ahead, higher token resolution, and stable training under limited compute. Policies are trained end-to-end under curricula that randomize terrain and appearance and progressively increase scene complexity. A compact, state-centric reward balances task progress, energy efficiency, and safety. Across diverse motion-control scenarios, our approach consistently surpasses strong state-of-the-art baselines in return, safety (collisions and falls), and sample efficiency, while converging faster at the same compute budget. These results suggest that SSD-Mamba2 provides a practical fusion backbone for resource-constrained robotic and autonomous systems in engineering informatics applications.