TransMPC: Transformer-based Explicit MPC with Variable Prediction Horizon
作者: Sichao Wu, Jiang Wu, Xingyu Cao, Fawang Zhang, Guangyuan Yu, Junjie Zhao, Yue Qu, Fei Ma, Jingliang Duan
分类: cs.RO
发布日期: 2025-09-09
💡 一句话要点
TransMPC:基于Transformer的可变预测步长显式模型预测控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 模型预测控制 显式MPC Transformer 策略优化 自动驾驶
📋 核心要点
- 传统在线MPC计算复杂度高,限制了其应用,而现有显式MPC精度不足。
- TransMPC利用Transformer的自注意力机制,实现单次前向推理整个控制序列,适应可变预测步长。
- TransMPC采用直接策略优化,通过自动微分优化真实成本,并使用随机步长采样增强泛化能力。
📝 摘要(中文)
传统的在线模型预测控制(MPC)方法常常面临计算复杂度过高的问题,限制了其在实际中的部署。显式MPC通过离线预计算控制策略来减轻在线计算负担;然而,现有的显式MPC方法通常依赖于简化的系统动力学和成本函数,限制了其在复杂系统中的精度。本文提出了一种新的基于Transformer的显式MPC算法TransMPC,该算法能够为复杂动态系统实时生成高精度的控制序列。具体来说,我们将MPC策略建模为一个仅包含编码器的Transformer,利用双向自注意力机制,能够在一次前向传递中同时推断整个控制序列。这种设计天然地适应可变的预测步长,同时确保低推理延迟。此外,我们引入了一个直接策略优化框架,该框架在采样和学习阶段之间交替进行。与依赖于预计算最优轨迹的基于模仿的方法不同,TransMPC通过自动微分直接优化真实的有限时域成本。随机步长采样与回放缓冲区相结合,提供了独立同分布(i.i.d.)的训练样本,确保了在不同状态和步长长度下的鲁棒泛化能力。大量的仿真和真实车辆控制实验验证了TransMPC在解决方案精度、适应不同步长和计算效率方面的有效性。
🔬 方法详解
问题定义:论文旨在解决传统在线MPC计算量大,以及现有显式MPC方法精度不足的问题。在线MPC需要实时求解优化问题,计算复杂度随预测步长增加而显著上升,难以应用于实时性要求高的复杂系统。现有显式MPC虽然通过离线计算降低了在线计算量,但通常依赖于简化模型和成本函数,导致控制精度下降。
核心思路:论文的核心思路是将MPC策略建模为一个Transformer网络,利用Transformer强大的序列建模能力,直接学习从状态到控制序列的映射。通过Transformer的自注意力机制,可以同时考虑整个预测范围内的状态信息,从而生成更优的控制序列。此外,采用直接策略优化方法,避免了对预计算最优轨迹的依赖,直接优化真实成本函数。
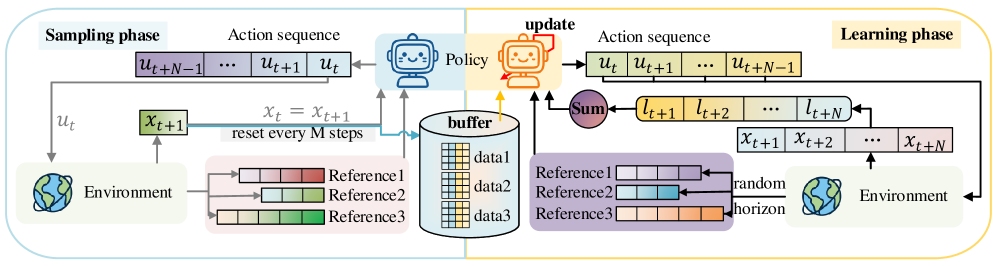
技术框架:TransMPC的整体框架包括离线训练和在线推理两个阶段。在离线训练阶段,首先随机采样状态和预测步长,然后使用Transformer网络预测控制序列,并计算有限时域成本。通过自动微分优化Transformer网络的参数。为了提高泛化能力,使用回放缓冲区存储训练样本。在线推理阶段,给定当前状态,Transformer网络直接输出控制序列,无需在线优化。
关键创新:TransMPC的关键创新在于以下几点:1) 使用Transformer网络作为显式MPC的策略表示,能够高效地学习复杂系统的控制策略。2) 采用直接策略优化方法,避免了对预计算最优轨迹的依赖,能够更好地优化真实成本函数。3) 引入随机步长采样,提高了模型的泛化能力,使其能够适应不同的预测步长。与现有方法的本质区别在于,TransMPC不再依赖于简化的系统模型和成本函数,而是直接学习从状态到控制序列的映射。
关键设计:TransMPC使用一个仅包含编码器的Transformer网络,输入为当前状态和预测步长,输出为控制序列。Transformer的层数、注意力头数等参数需要根据具体问题进行调整。损失函数为有限时域成本,包括状态成本和控制成本。为了提高训练效率和稳定性,使用了Adam优化器和梯度裁剪等技术。随机步长采样的范围需要根据具体问题进行设置。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TransMPC在仿真和真实车辆控制实验中均取得了显著的性能提升。在仿真实验中,TransMPC的控制精度优于传统的显式MPC方法,并且能够适应不同的预测步长。在真实车辆控制实验中,TransMPC能够实现平稳的车辆控制,并且具有良好的鲁棒性。具体性能数据未知。
🎯 应用场景
TransMPC具有广泛的应用前景,例如自动驾驶、机器人控制、飞行器控制等领域。在自动驾驶中,TransMPC可以用于车辆的路径规划和轨迹跟踪,提高车辆的行驶安全性。在机器人控制中,TransMPC可以用于机器人的运动规划和控制,提高机器人的灵活性和适应性。该研究有望推动模型预测控制在复杂动态系统中的实际应用。
📄 摘要(原文)
Traditional online Model Predictive Control (MPC) methods often suffer from excessive computational complexity, limiting their practical deployment. Explicit MPC mitigates online computational load by pre-computing control policies offline; however, existing explicit MPC methods typically rely on simplified system dynamics and cost functions, restricting their accuracy for complex systems. This paper proposes TransMPC, a novel Transformer-based explicit MPC algorithm capable of generating highly accurate control sequences in real-time for complex dynamic systems. Specifically, we formulate the MPC policy as an encoder-only Transformer leveraging bidirectional self-attention, enabling simultaneous inference of entire control sequences in a single forward pass. This design inherently accommodates variable prediction horizons while ensuring low inference latency. Furthermore, we introduce a direct policy optimization framework that alternates between sampling and learning phases. Unlike imitation-based approaches dependent on precomputed optimal trajectories, TransMPC directly optimizes the true finite-horizon cost via automatic differentiation. Random horizon sampling combined with a replay buffer provides independent and identically distributed (i.i.d.) training samples, ensuring robust generalization across varying states and horizon lengths. Extensive simulations and real-world vehicle control experiments validate the effectiveness of TransMPC in terms of solution accuracy, adaptability to varying horizons, and computational efficiency.