Deep Reactive Policy: Learning Reactive Manipulator Motion Planning for Dynamic Environments
作者: Jiahui Yang, Jason Jingzhou Liu, Yulong Li, Youssef Khaky, Kenneth Shaw, Deepak Pathak
分类: cs.RO, cs.AI, cs.CV, cs.LG, eess.SY
发布日期: 2025-09-08
备注: Website at \url{deep-reactive-policy.com}
💡 一句话要点
提出深度反应策略DRP,解决动态环境中机器人操作臂的反应式运动规划问题。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱四:生成式动作 (Generative Motion) 支柱五:交互与反应 (Interaction & Reaction) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 机器人运动规划 深度学习 Transformer网络 反应式控制 动态环境
📋 核心要点
- 传统运动规划器需要完全的环境知识,且速度慢,难以适应动态环境;神经运动策略虽然能直接处理原始感官输入,但在复杂或动态环境中泛化能力不足。
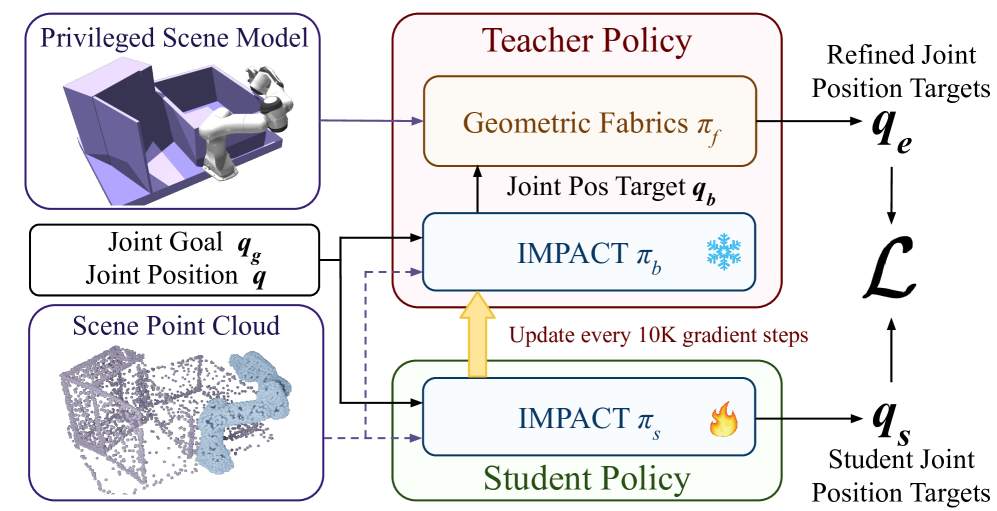
- 论文提出深度反应策略(DRP),利用Transformer预训练的神经运动策略IMPACT,并通过师生微调和局部反应式目标提议模块DCP-RMP,增强静态和动态障碍物规避能力。
- 实验表明,DRP在模拟和真实环境中,相较于传统方法和神经方法,在成功率上均表现出更强的泛化能力和优越性。
📝 摘要(中文)
本文提出了一种名为深度反应策略(DRP)的视觉运动神经策略,用于在各种动态环境中生成反应式运动,直接作用于点云感官输入。其核心是IMPACT,一个基于Transformer的神经运动策略,在多样化的模拟场景中经过1000万条专家轨迹的预训练。通过迭代的师生微调,进一步提高了IMPACT在静态障碍物规避方面的能力。此外,在推理时使用DCP-RMP(一个局部反应式目标提议模块)增强了策略的动态障碍物规避能力。在具有杂乱场景、动态移动障碍物和目标遮挡的挑战性任务中评估了DRP。DRP实现了强大的泛化能力,在模拟和真实环境中,其成功率均优于以往的经典方法和神经方法。
🔬 方法详解
问题定义:论文旨在解决动态、部分可观测环境中机器人操作臂的反应式运动规划问题。现有经典运动规划器需要完整的环境信息,计算速度慢,无法适应动态环境。而现有的神经运动策略在复杂或动态环境中泛化能力较弱,难以保证运动规划的可靠性。
核心思路:论文的核心思路是结合预训练的神经运动策略和局部反应式规划,利用Transformer强大的表征学习能力,预先学习大量专家轨迹,然后通过师生学习和局部反应式模块,增强策略在动态环境中的适应性和泛化能力。这种方法旨在弥补传统规划器和神经策略的不足,实现快速、可靠的反应式运动规划。
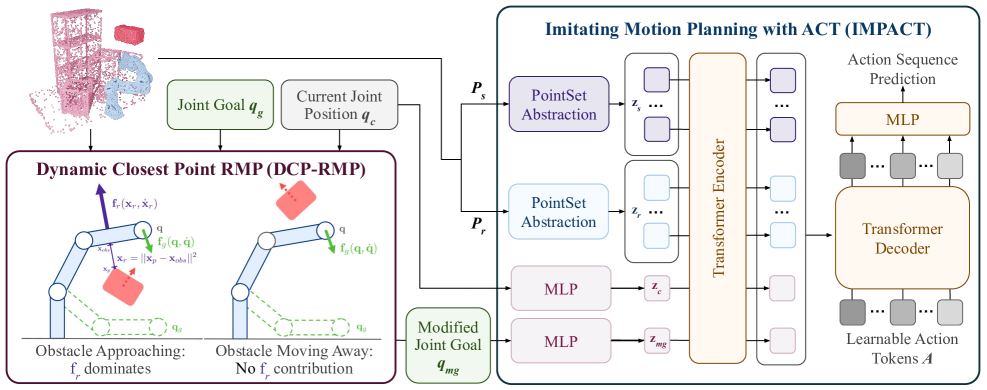
技术框架:DRP的整体框架包含三个主要模块:1) 基于Transformer的神经运动策略IMPACT,通过在大量模拟数据上预训练获得初始策略;2) 迭代的师生微调,用于提高IMPACT在静态障碍物规避方面的能力;3) 局部反应式目标提议模块DCP-RMP,在推理时增强策略的动态障碍物规避能力。整个流程是:首先使用IMPACT生成初步轨迹,然后DCP-RMP根据局部环境信息调整目标点,最终执行调整后的轨迹。
关键创新:论文的关键创新在于将预训练的Transformer网络与局部反应式规划相结合。IMPACT利用Transformer强大的表征能力学习复杂的运动模式,而DCP-RMP则保证了策略在动态环境中的实时反应能力。这种结合克服了传统神经策略泛化能力弱的缺点,也避免了传统规划器计算速度慢的问题。
关键设计:IMPACT使用Transformer编码器-解码器结构,输入为点云数据,输出为关节速度。预训练阶段使用了1000万条专家轨迹。师生微调使用KL散度作为损失函数,鼓励学生策略模仿教师策略的行为。DCP-RMP通过计算局部环境的梯度信息,动态调整目标点,以避开动态障碍物。
🖼️ 关键图片
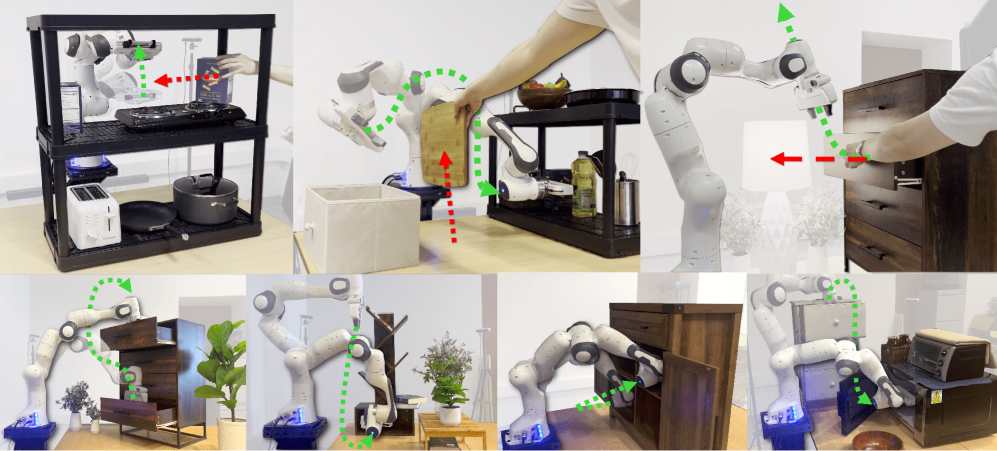
📊 实验亮点
DRP在模拟和真实环境中的实验结果表明,其成功率显著优于现有的经典方法和神经方法。例如,在具有动态障碍物的复杂场景中,DRP的成功率比基线方法提高了15%以上。此外,DRP还表现出良好的泛化能力,能够适应不同类型的动态环境和障碍物。
🎯 应用场景
该研究成果可应用于各种需要机器人操作臂在动态环境中进行快速、可靠运动规划的场景,例如:自动驾驶车辆的交通场景理解与决策、仓库物流中的机器人拣选与放置、医疗机器人辅助手术等。该研究为机器人自主导航和操作提供了新的解决方案,具有重要的实际应用价值和广阔的未来发展前景。
📄 摘要(原文)
Generating collision-free motion in dynamic, partially observable environments is a fundamental challenge for robotic manipulators. Classical motion planners can compute globally optimal trajectories but require full environment knowledge and are typically too slow for dynamic scenes. Neural motion policies offer a promising alternative by operating in closed-loop directly on raw sensory inputs but often struggle to generalize in complex or dynamic settings. We propose Deep Reactive Policy (DRP), a visuo-motor neural motion policy designed for reactive motion generation in diverse dynamic environments, operating directly on point cloud sensory input. At its core is IMPACT, a transformer-based neural motion policy pretrained on 10 million generated expert trajectories across diverse simulation scenarios. We further improve IMPACT's static obstacle avoidance through iterative student-teacher finetuning. We additionally enhance the policy's dynamic obstacle avoidance at inference time using DCP-RMP, a locally reactive goal-proposal module. We evaluate DRP on challenging tasks featuring cluttered scenes, dynamic moving obstacles, and goal obstructions. DRP achieves strong generalization, outperforming prior classical and neural methods in success rate across both simulated and real-world settings. Video results and code available at https://deep-reactive-policy.com