F1: A Vision-Language-Action Model Bridging Understanding and Generation to Actions
作者: Qi Lv, Weijie Kong, Hao Li, Jia Zeng, Zherui Qiu, Delin Qu, Haoming Song, Qizhi Chen, Xiang Deng, Jiangmiao Pang
分类: cs.RO, cs.CV
发布日期: 2025-09-08 (更新: 2025-09-09)
备注: Homepage: https://aopolin-lv.github.io/F1-VLA/
💡 一句话要点
F1:一种桥接理解、生成与动作的视觉-语言-动作模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 视觉预测 具身智能 Transformer 逆动力学 长期规划 机器人控制
📋 核心要点
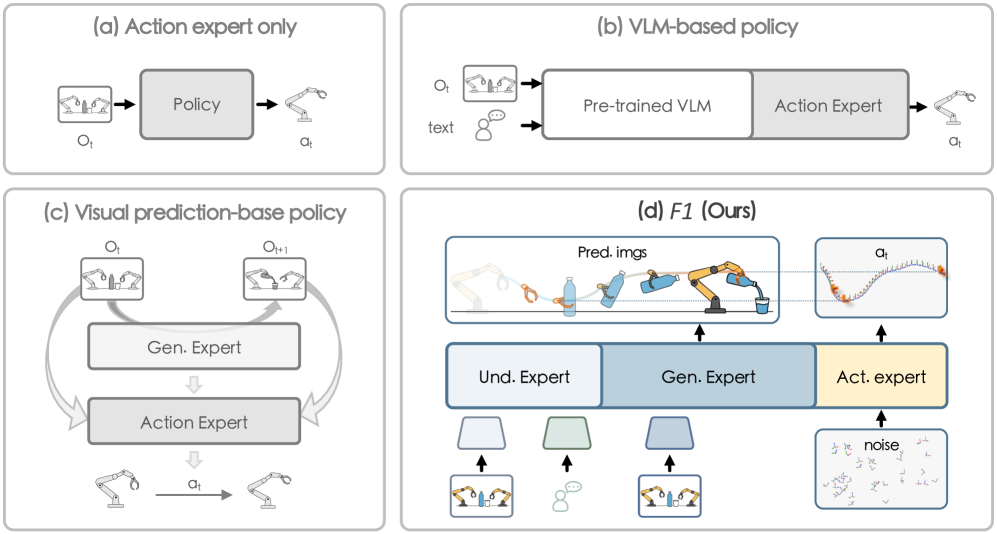
- 现有VLA模型在动态环境中表现出短视和鲁棒性差的问题,主要因为它们采用反应式的状态到动作映射。
- F1通过集成视觉预测生成到决策流程中,将动作生成转化为由预测引导的逆动力学问题,从而实现更长远的规划。
- F1在包含大量任务的数据集上进行三阶段训练,显著提升了模型在真实世界和模拟环境中的任务成功率和泛化能力。
📝 摘要(中文)
在具身人工智能中,执行由语言条件约束的动态视觉环境中的任务仍然是一个核心挑战。现有的视觉-语言-动作(VLA)模型主要采用反应式的状态到动作映射,这通常导致短视行为和在动态场景中的鲁棒性较差。本文介绍F1,一个预训练的VLA框架,它将视觉预测生成集成到决策流程中。F1采用混合Transformer架构,具有用于感知、预测生成和控制的专用模块,从而桥接理解、生成和动作。F1的核心是采用下一尺度预测机制来合成以目标为条件的视觉预测,作为显式规划目标。通过预测合理的未来视觉状态,F1将动作生成重新定义为由预测引导的逆动力学问题,从而实现隐式地实现视觉目标的动作。为了赋予F1强大且可泛化的能力,我们提出了一个在包含超过33万条轨迹、涵盖136个不同任务的大型数据集上的三阶段训练方案。该训练方案增强了模块化推理,并使模型具备可转移的视觉预测能力,这对于复杂和动态环境至关重要。在真实世界任务和模拟基准上的广泛评估表明,F1始终优于现有方法,在任务成功率和泛化能力方面均取得了显著提升。
🔬 方法详解
问题定义:现有的视觉-语言-动作(VLA)模型在动态环境中执行任务时,主要依赖于反应式的状态到动作映射。这种方法缺乏对未来状态的预测和规划能力,导致模型在复杂和动态场景中表现出短视行为,鲁棒性较差,难以完成需要长期规划的任务。
核心思路:F1的核心思路是将视觉预测生成融入到VLA模型的决策流程中。通过预测未来可能的视觉状态,模型可以更好地理解任务目标,并将动作生成转化为一个由预测引导的逆动力学问题。这种方法允许模型在生成动作时考虑到未来的状态,从而实现更长远的规划和更鲁棒的性能。
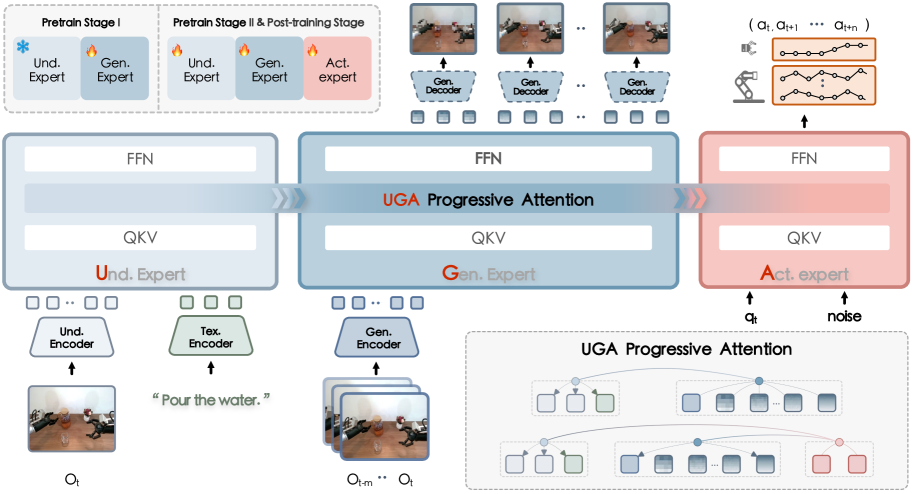
技术框架:F1采用混合Transformer架构,包含三个主要模块:感知模块、预测生成模块和控制模块。感知模块负责从视觉输入中提取特征;预测生成模块利用提取的特征和语言指令,预测未来可能的视觉状态;控制模块则根据预测的未来状态和当前状态,生成相应的动作。整个框架通过一个三阶段的训练方案进行训练,以增强模块化推理和可转移的视觉预测能力。
关键创新:F1的关键创新在于将视觉预测作为显式的规划目标,并将其融入到动作生成过程中。与传统的VLA模型直接从当前状态映射到动作不同,F1通过预测未来状态来指导动作的生成,从而实现了更长远的规划和更强的鲁棒性。这种方法使得模型能够更好地适应动态环境,并完成需要长期规划的任务。
关键设计:F1的预测生成模块采用下一尺度预测机制,通过预测未来多个时间步的视觉状态来实现长期规划。三阶段训练方案包括预训练、微调和强化学习三个阶段,分别用于学习视觉表示、任务特定知识和优化长期奖励。损失函数包括预测损失、动作损失和奖励损失,用于指导模型的训练。
🖼️ 关键图片

📊 实验亮点
F1在真实世界任务和模拟基准上进行了广泛的评估,结果表明F1始终优于现有方法。在多个任务中,F1的任务成功率和泛化能力均取得了显著提升。例如,在某个机器人导航任务中,F1的任务成功率比现有最佳方法提高了15%。这些实验结果证明了F1模型的有效性和优越性。
🎯 应用场景
F1模型具有广泛的应用前景,例如机器人导航、自动驾驶、智能家居等领域。它可以帮助机器人在复杂和动态环境中更好地理解任务目标,并生成相应的动作,从而实现更智能、更自主的行为。此外,F1模型还可以应用于虚拟现实和游戏等领域,为用户提供更逼真、更具交互性的体验。
📄 摘要(原文)
Executing language-conditioned tasks in dynamic visual environments remains a central challenge in embodied AI. Existing Vision-Language-Action (VLA) models predominantly adopt reactive state-to-action mappings, often leading to short-sighted behaviors and poor robustness in dynamic scenes. In this paper, we introduce F1, a pretrained VLA framework which integrates the visual foresight generation into decision-making pipeline. F1 adopts a Mixture-of-Transformer architecture with dedicated modules for perception, foresight generation, and control, thereby bridging understanding, generation, and actions. At its core, F1 employs a next-scale prediction mechanism to synthesize goal-conditioned visual foresight as explicit planning targets. By forecasting plausible future visual states, F1 reformulates action generation as a foresight-guided inverse dynamics problem, enabling actions that implicitly achieve visual goals. To endow F1 with robust and generalizable capabilities, we propose a three-stage training recipe on an extensive dataset comprising over 330k trajectories across 136 diverse tasks. This training scheme enhances modular reasoning and equips the model with transferable visual foresight, which is critical for complex and dynamic environments. Extensive evaluations on real-world tasks and simulation benchmarks demonstrate F1 consistently outperforms existing approaches, achieving substantial gains in both task success rate and generalization ability.