Towards bridging the gap: Systematic sim-to-real transfer for diverse legged robots
作者: Filip Bjelonic, Fabian Tischhauser, Marco Hutter
分类: cs.RO
发布日期: 2025-09-08
备注: Submitted to The International Journal of Robotics Research (IJRR), 25 Figures, 7 Tables, Open Source Data available at ETH Research Collection. Open Source software available soon
💡 一句话要点
提出一种系统性的Sim-to-Real迁移框架,用于提升多样化足式机器人的能量效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 足式机器人 Sim-to-Real 强化学习 能量效率 永磁同步电机 动态参数识别 机器人控制
📋 核心要点
- 现有足式机器人控制器在仿真到现实的迁移中存在鲁棒性问题,且忽略了执行器能量损耗,依赖手动调整的奖励函数。
- 该论文提出了一种结合sim-to-real强化学习和基于物理的电机能量模型的框架,使用少量参数捕捉仿真与现实的差异。
- 实验表明,该框架在多个机器人平台上实现了可靠的策略迁移,且显著提升了能量效率,ANYmal的运输成本降低了32%。
📝 摘要(中文)
为了使足式机器人在真实环境中实用,必须实现稳健的运动和能量效率。然而,在仿真中训练的控制器通常无法可靠地迁移,并且大多数现有方法忽略了特定于执行器的能量损失或依赖于复杂的手动调整的奖励函数。本文提出了一种框架,该框架将sim-to-real强化学习与永磁同步电机的基于物理的能量模型相结合。该框架需要一个最小的参数集来捕获仿真到现实的差距,并采用紧凑的四项奖励,其中包含基于第一性原理的能量损失公式,以平衡电气和机械损耗。通过自下而上的动态参数识别研究,涵盖执行器、完整的机器人空中轨迹和地面运动,对该方法进行了评估和验证。该框架在三个主要平台上进行了测试,并在十个额外的机器人上进行了部署,证明了可靠的策略迁移,而无需动态参数的随机化。该方法提高了能量效率,与最先进的方法相比,ANYmal的完整运输成本降低了32%(值为1.27)。所有代码、模型和数据集都将发布。
🔬 方法详解
问题定义:足式机器人需要在真实环境中实现鲁棒的运动和能量效率,但现有方法在仿真到现实的迁移过程中存在问题。具体来说,现有方法要么忽略了执行器特定的能量损失,要么依赖于复杂且需要手动调整的奖励函数,导致在真实机器人上的性能不佳。因此,需要一种能够有效弥合仿真与现实差距,并优化能量效率的控制方法。
核心思路:该论文的核心思路是将sim-to-real强化学习与基于物理的能量模型相结合。通过建立精确的电机能量模型,可以在训练过程中考虑执行器的能量损耗,从而优化控制策略的能量效率。同时,利用强化学习的自适应能力,可以自动学习到适应真实环境的控制策略,从而实现鲁棒的sim-to-real迁移。
技术框架:该框架主要包含以下几个模块:1) 机器人动力学仿真环境;2) 基于物理的永磁同步电机能量模型;3) 强化学习算法(例如PPO);4) 奖励函数设计,包含运动目标跟踪和能量消耗惩罚项;5) 动态参数识别模块,用于缩小仿真与现实的差距。整体流程是:首先在仿真环境中训练强化学习策略,然后通过动态参数识别来校准仿真环境,最后将训练好的策略迁移到真实机器人上。
关键创新:该论文最重要的技术创新点在于将基于物理的能量模型与sim-to-real强化学习相结合。这种方法能够更精确地模拟真实机器人的能量损耗,从而优化控制策略的能量效率。此外,该框架只需要一个最小的参数集来捕捉仿真到现实的差距,降低了人工调整的复杂度。
关键设计:奖励函数由四项组成:运动目标跟踪奖励、能量消耗惩罚项、平滑性奖励和存活奖励。能量消耗惩罚项基于第一性原理的能量损失公式,平衡了电气和机械损耗。动态参数识别采用自下而上的方法,首先识别执行器的参数,然后识别整个机器人的参数。强化学习算法采用PPO,网络结构为多层感知机。
🖼️ 关键图片


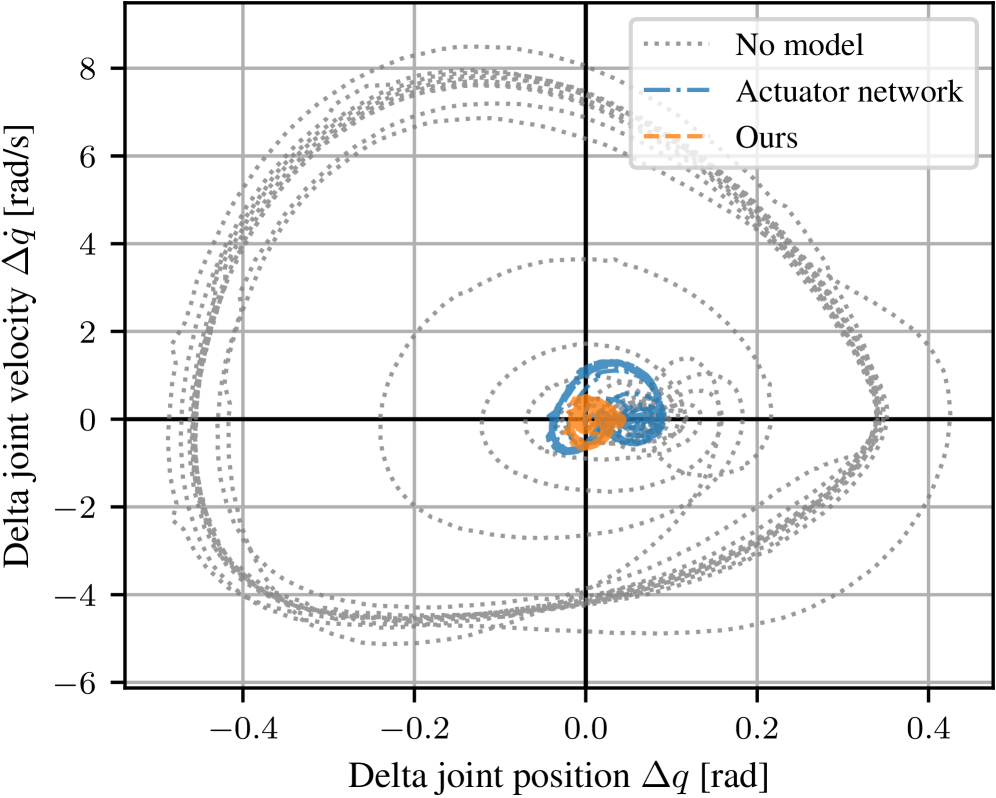
📊 实验亮点
该框架在三个主要平台和十个额外的机器人上进行了测试,无需动态参数随机化即可实现可靠的策略迁移。与最先进的方法相比,ANYmal的完整运输成本降低了32%(值为1.27),证明了该方法在提高能量效率方面的显著优势。此外,该论文还提供了详细的动态参数识别研究,验证了该方法的有效性。
🎯 应用场景
该研究成果可广泛应用于各种足式机器人,例如搜索救援机器人、物流机器人、巡检机器人等。通过提高能量效率,可以延长机器人的续航时间,使其能够在更复杂的环境中执行任务。此外,该方法还可以应用于其他类型的机器人,例如无人机和水下机器人,以提高其能量效率和鲁棒性。
📄 摘要(原文)
Legged robots must achieve both robust locomotion and energy efficiency to be practical in real-world environments. Yet controllers trained in simulation often fail to transfer reliably, and most existing approaches neglect actuator-specific energy losses or depend on complex, hand-tuned reward formulations. We propose a framework that integrates sim-to-real reinforcement learning with a physics-grounded energy model for permanent magnet synchronous motors. The framework requires a minimal parameter set to capture the simulation-to-reality gap and employs a compact four-term reward with a first-principle-based energetic loss formulation that balances electrical and mechanical dissipation. We evaluate and validate the approach through a bottom-up dynamic parameter identification study, spanning actuators, full-robot in-air trajectories and on-ground locomotion. The framework is tested on three primary platforms and deployed on ten additional robots, demonstrating reliable policy transfer without randomization of dynamic parameters. Our method improves energetic efficiency over state-of-the-art methods, achieving a 32 percent reduction in the full Cost of Transport of ANYmal (value 1.27). All code, models, and datasets will be released.