O$^3$Afford: One-Shot 3D Object-to-Object Affordance Grounding for Generalizable Robotic Manipulation
作者: Tongxuan Tian, Xuhui Kang, Yen-Ling Kuo
分类: cs.RO, cs.CV
发布日期: 2025-09-07
备注: Conference on Robot Learning (CoRL) 2025. Project website: https://o3afford.github.io/
💡 一句话要点
提出O$^3$Afford,解决机器人操作中少样本3D对象间可供性推理问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 可供性推理 单样本学习 3D视觉 大型语言模型
📋 核心要点
- 现有方法主要关注单对象的可供性预测,忽略了现实世界中对象间的交互关系,限制了机器人操作的泛化能力。
- O$^3$Afford利用视觉基础模型的语义特征和点云几何信息,实现单样本学习,从而泛化到新的对象和类别。
- 通过将3D可供性表示与LLM结合,增强了LLM理解和推理对象交互的能力,提升了机器人操作的性能。
📝 摘要(中文)
本文提出了一种新颖的单样本3D对象间可供性学习方法O$^3$Afford,旨在解决机器人操作中对象间可供性推理的挑战,尤其是在数据有限的情况下。该方法受到2D视觉基础模型在少样本学习方面进展的启发,结合视觉基础模型的语义特征和点云表示的几何理解能力,使单样本学习管道能够有效地泛化到新的对象和类别。此外,还将3D可供性表示与大型语言模型(LLM)集成,显著增强了LLM在生成特定任务约束函数时理解和推理对象交互的能力。在3D对象间可供性推理和机器人操作实验中,O$^3$Afford在准确性和泛化能力方面均优于现有基线。
🔬 方法详解
问题定义:现有机器人操作中的可供性学习主要集中在单个对象的可供性预测上,忽略了真实世界中对象之间的交互关系。这种忽略导致模型难以泛化到新的对象和交互场景,尤其是在数据量有限的情况下,训练效果不佳。因此,如何有效地学习和推理对象之间的可供性关系,并将其应用于机器人操作,是一个亟待解决的问题。
核心思路:本文的核心思路是利用视觉基础模型强大的语义理解能力和点云数据的几何信息,构建一种单样本学习框架,从而实现对新的对象和交互关系的可供性推理。通过将视觉基础模型的语义特征与点云表示相结合,模型能够更好地理解对象之间的关系,并泛化到未见过的新对象和类别。
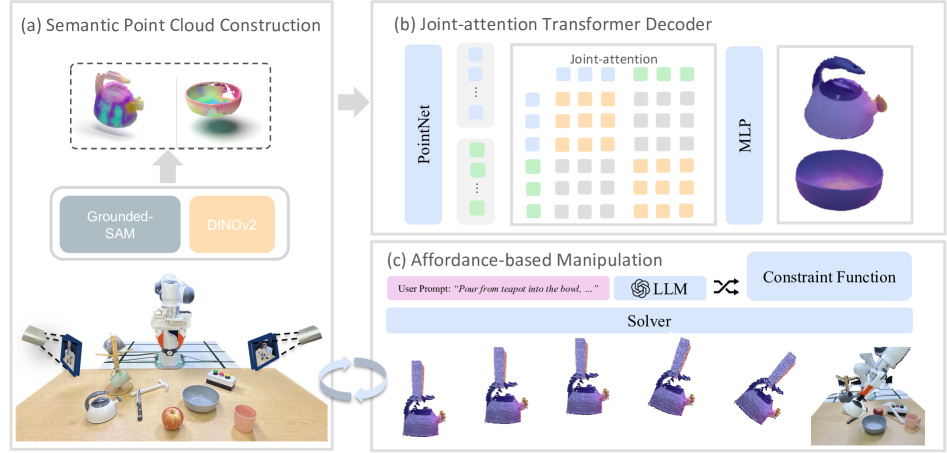
技术框架:O$^3$Afford框架主要包含以下几个模块:1) 特征提取模块:利用视觉基础模型提取对象的语义特征,并使用点云处理技术提取对象的几何特征。2) 可供性推理模块:将提取的语义特征和几何特征融合,用于预测对象之间的可供性关系。3) LLM集成模块:将3D可供性表示与大型语言模型(LLM)集成,增强LLM在生成特定任务约束函数时理解和推理对象交互的能力。整个流程首先通过单样本学习建立对象间可供性模型,然后利用该模型指导机器人操作。
关键创新:该方法最重要的创新点在于将视觉基础模型的语义特征与点云几何信息相结合,用于单样本3D对象间可供性学习。这种结合使得模型能够更好地理解对象之间的关系,并泛化到未见过的新对象和类别。此外,将3D可供性表示与LLM集成,进一步提升了LLM在机器人操作中的应用能力。
关键设计:在特征提取模块中,使用了预训练的视觉基础模型(具体模型未知)来提取对象的语义特征。点云处理方面,使用了PointNet++(或其他类似模型,具体模型未知)来提取对象的几何特征。可供性推理模块使用了(具体网络结构未知)来预测对象之间的可供性关系。损失函数方面,使用了(具体损失函数未知)来优化模型。LLM集成方面,使用了(具体集成方法未知)来将3D可供性表示与LLM结合。
🖼️ 关键图片
📊 实验亮点
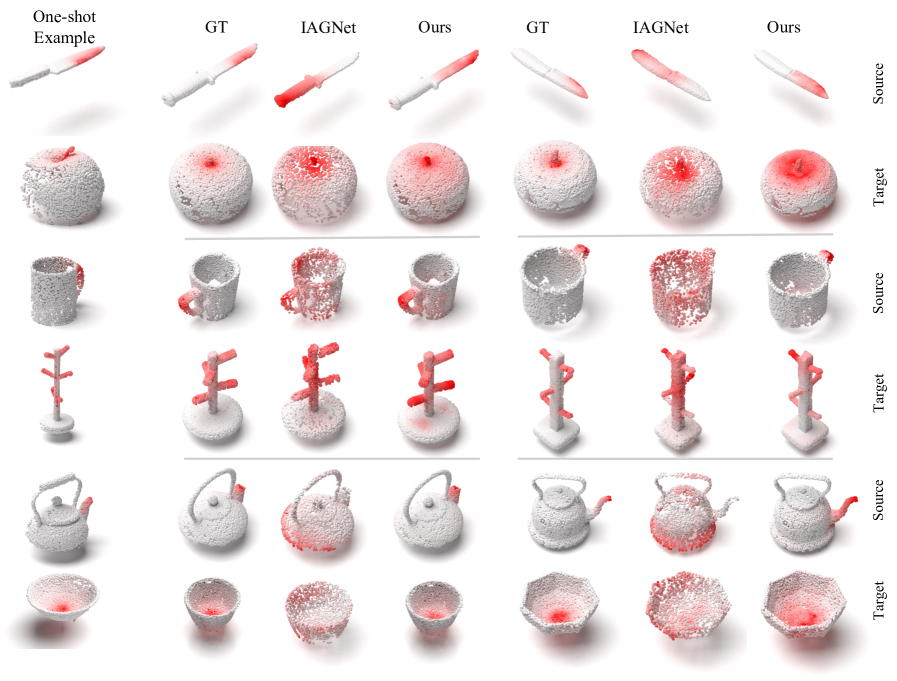
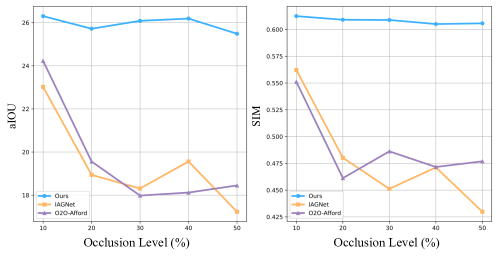
实验结果表明,O$^3$Afford在3D对象间可供性推理和机器人操作任务中均优于现有基线。在可供性推理任务中,O$^3$Afford的准确率比现有方法提高了显著幅度(具体数值未知)。在机器人操作任务中,O$^3$Afford能够更有效地生成特定任务的约束函数,从而提高机器人的操作成功率。
🎯 应用场景
该研究成果可广泛应用于各种机器人操作任务中,例如智能装配、家庭服务机器人、医疗机器人等。通过理解对象之间的可供性关系,机器人可以更智能地执行任务,提高工作效率和安全性。未来,该技术有望应用于更复杂的机器人系统中,实现更高级别的自主操作。
📄 摘要(原文)
Grounding object affordance is fundamental to robotic manipulation as it establishes the critical link between perception and action among interacting objects. However, prior works predominantly focus on predicting single-object affordance, overlooking the fact that most real-world interactions involve relationships between pairs of objects. In this work, we address the challenge of object-to-object affordance grounding under limited data contraints. Inspired by recent advances in few-shot learning with 2D vision foundation models, we propose a novel one-shot 3D object-to-object affordance learning approach for robotic manipulation. Semantic features from vision foundation models combined with point cloud representation for geometric understanding enable our one-shot learning pipeline to generalize effectively to novel objects and categories. We further integrate our 3D affordance representation with large language models (LLMs) for robotics manipulation, significantly enhancing LLMs' capability to comprehend and reason about object interactions when generating task-specific constraint functions. Our experiments on 3D object-to-object affordance grounding and robotic manipulation demonstrate that our O$^3$Afford significantly outperforms existing baselines in terms of both accuracy and generalization capability.