Grasp-MPC: Closed-Loop Visual Grasping via Value-Guided Model Predictive Control
作者: Jun Yamada, Adithyavairavan Murali, Ajay Mandlekar, Clemens Eppner, Ingmar Posner, Balakumar Sundaralingam
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-09-07
备注: 14 pages, 17 figures
💡 一句话要点
Grasp-MPC:基于价值引导模型预测控制的闭环视觉抓取
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 机器人抓取 模型预测控制 视觉伺服 深度学习 闭环控制
📋 核心要点
- 开放循环抓取方法在复杂环境中表现不佳,主要原因是抓取预测误差和抓取过程中物体姿态的变化。
- Grasp-MPC通过学习价值函数并将其融入模型预测控制框架,实现了对杂乱环境中新物体的鲁棒抓取。
- 实验结果表明,Grasp-MPC在模拟和真实环境中均显著提高了抓取成功率,优于多种基线方法。
📝 摘要(中文)
本文提出Grasp-MPC,一种闭环的6自由度视觉抓取策略,旨在实现对杂乱环境中新物体的鲁棒和反应式抓取。Grasp-MPC融合了一个价值函数,该函数通过大规模合成数据集(包含200万条抓取轨迹,包括成功和失败的尝试)中的视觉观测进行训练。该学习到的价值函数被部署在MPC框架中,并结合其他成本项,以鼓励避碰和流畅执行。在FetchBench和真实环境中,Grasp-MPC在各种环境中进行了评估,结果表明,在模拟环境中,抓取成功率提高了32.6%,在真实世界的噪声条件下,抓取成功率提高了33.3%,优于开放循环、扩散策略、Transformer策略和IQL方法。
🔬 方法详解
问题定义:论文旨在解决在非结构化环境中抓取多样化物体的问题。现有的开放循环方法在控制良好的环境中有效,但在杂乱环境中表现不佳,容易受到抓取预测误差和物体姿态变化的影响。现有的闭环方法虽然在简化环境中有效,但泛化能力有限。
核心思路:论文的核心思路是利用学习到的价值函数来指导模型预测控制(MPC),从而实现鲁棒和反应式的抓取。价值函数能够评估抓取轨迹的优劣,MPC则能够根据价值函数和其他成本项(如避碰)来规划最优的抓取轨迹。
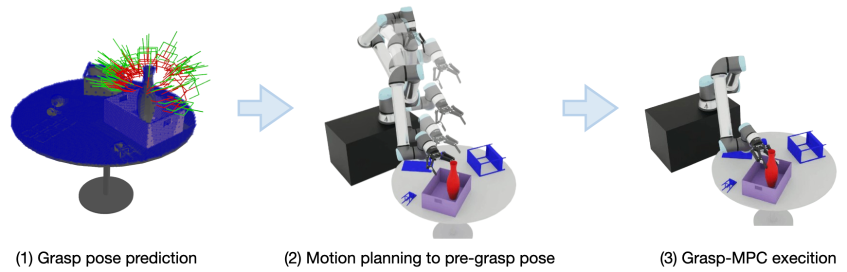
技术框架:Grasp-MPC的整体框架包括以下几个主要模块:1) 视觉感知模块,用于获取环境的视觉信息;2) 价值函数模块,用于评估抓取轨迹的价值;3) 模型预测控制模块,用于根据价值函数和其他成本项规划最优的抓取轨迹;4) 运动控制模块,用于执行抓取轨迹。该框架采用闭环控制,能够根据环境的变化实时调整抓取策略。
关键创新:最重要的技术创新点是将学习到的价值函数融入模型预测控制框架。传统的MPC方法通常依赖于手工设计的成本函数,难以适应复杂环境。通过学习价值函数,Grasp-MPC能够自动学习到抓取任务的内在规律,从而实现更鲁棒的抓取。与现有方法的本质区别在于,Grasp-MPC能够利用视觉信息进行闭环控制,并能够泛化到新的物体和环境。
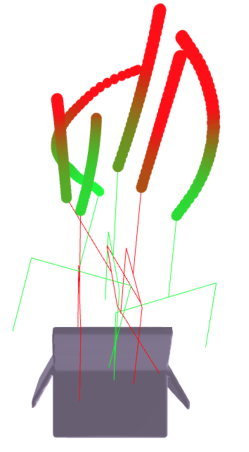
关键设计:价值函数通过大规模合成数据集进行训练,数据集包含200万条抓取轨迹,包括成功和失败的尝试。价值函数采用深度神经网络结构,输入为视觉观测,输出为抓取轨迹的价值。MPC框架采用滚动优化策略,每一步都根据当前状态重新规划抓取轨迹。成本函数包括价值函数、避碰成本和运动平滑成本。具体参数设置和网络结构等细节未在摘要中详细说明,需要参考论文全文。
🖼️ 关键图片
📊 实验亮点
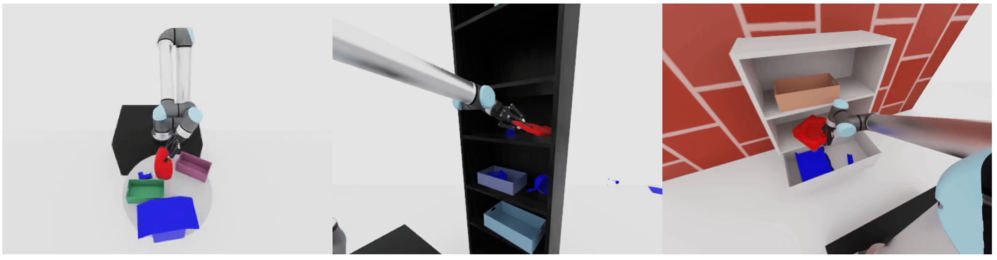
Grasp-MPC在FetchBench和真实环境中进行了评估,结果表明,在模拟环境中,抓取成功率提高了32.6%,在真实世界的噪声条件下,抓取成功率提高了33.3%,显著优于开放循环、扩散策略、Transformer策略和IQL等基线方法。这些结果表明,Grasp-MPC具有很强的鲁棒性和泛化能力。
🎯 应用场景
Grasp-MPC具有广泛的应用前景,例如在物流、仓储、家庭服务机器人等领域。它可以用于自动化地抓取和操作各种物体,提高工作效率和降低成本。此外,该研究还可以促进机器人视觉和控制领域的发展,为更智能的机器人系统的设计提供参考。
📄 摘要(原文)
Grasping of diverse objects in unstructured environments remains a significant challenge. Open-loop grasping methods, effective in controlled settings, struggle in cluttered environments. Grasp prediction errors and object pose changes during grasping are the main causes of failure. In contrast, closed-loop methods address these challenges in simplified settings (e.g., single object on a table) on a limited set of objects, with no path to generalization. We propose Grasp-MPC, a closed-loop 6-DoF vision-based grasping policy designed for robust and reactive grasping of novel objects in cluttered environments. Grasp-MPC incorporates a value function, trained on visual observations from a large-scale synthetic dataset of 2 million grasp trajectories that include successful and failed attempts. We deploy this learned value function in an MPC framework in combination with other cost terms that encourage collision avoidance and smooth execution. We evaluate Grasp-MPC on FetchBench and real-world settings across diverse environments. Grasp-MPC improves grasp success rates by up to 32.6% in simulation and 33.3% in real-world noisy conditions, outperforming open-loop, diffusion policy, transformer policy, and IQL approaches. Videos and more at http://grasp-mpc.github.io.