Long-Horizon Visual Imitation Learning via Plan and Code Reflection
作者: Quan Chen, Chenrui Shi, Qi Chen, Yuwei Wu, Zhi Gao, Xintong Zhang, Rui Gao, Kun Wu, Yunde Jia
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-09-04 (更新: 2025-12-18)
备注: 9 pages, 4 figures
💡 一句话要点
提出基于Plan和Code反射的长时程视觉模仿学习框架,解决复杂动作序列的时序和空间关系建模难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 视觉模仿学习 长时程任务 计划反射 代码反射 动作序列 时空关系 机器人操作
📋 核心要点
- 长时程视觉模仿学习面临动作时序关系和对象空间关系建模的挑战,现有方法难以有效处理。
- 提出Plan和Code反射机制,分别验证和修正动作序列的时序连贯性和代码的正确性,提升模仿学习效果。
- 构建LongVILBench基准测试,实验表明该框架显著优于现有方法,为长时程视觉模仿学习提供新基线。
📝 摘要(中文)
本文针对视觉模仿学习中长时程演示和复杂动作序列带来的挑战,尤其是在理解动作的时序关系和对象间的空间关系方面,提出了一种新的智能体框架。该框架包含两个专门的反射模块,分别用于增强计划生成和代码生成。计划生成模块产生初始动作序列,并通过计划反射模块验证其时序连贯性和与演示视频的空间对齐。代码生成模块将计划转化为可执行代码,并通过代码反射模块验证和细化生成的代码,确保其正确性和与生成计划的一致性。这两个反射模块共同使智能体能够检测和纠正计划生成和代码生成中的错误,从而提高在具有复杂时序和空间依赖性的任务中的性能。为了支持系统评估,我们引入了LongVILBench,一个包含300个人工演示的基准,动作序列最多可达18步。LongVILBench强调跨多种任务类型的时序和空间复杂性。实验结果表明,现有方法在这个基准上表现不佳,而我们的新框架为长时程视觉模仿学习建立了一个强大的基线。
🔬 方法详解
问题定义:长时程视觉模仿学习旨在让智能体从人类演示视频中学习执行复杂任务,尤其是在动作序列较长且包含复杂的时序和空间依赖关系时。现有方法难以有效捕捉这些依赖关系,导致模仿效果不佳。痛点在于如何保证生成动作序列的时序连贯性,以及如何确保智能体理解并执行与演示视频中对象空间关系一致的动作。
核心思路:论文的核心思路是通过引入“反射”机制来提升计划生成和代码生成的质量。具体来说,就是让智能体在生成动作序列(计划)和将计划转化为可执行代码后,分别进行验证和修正,从而减少错误并提高模仿的准确性。这种“反思”的过程模拟了人类在学习复杂任务时的自我检查和纠错行为。
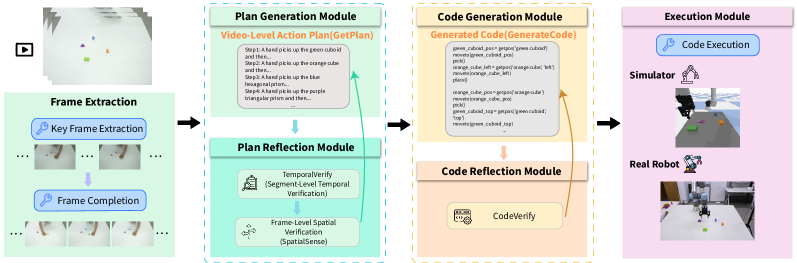
技术框架:整体框架包含四个主要模块:计划生成模块、计划反射模块、代码生成模块和代码反射模块。首先,计划生成模块根据输入视频生成初始的动作序列计划。然后,计划反射模块对该计划进行验证,检查其时序连贯性和空间对齐性,并进行修正。接着,代码生成模块将修正后的计划转化为可执行的代码。最后,代码反射模块验证生成的代码是否正确,并与计划保持一致,进行必要的调整。整个流程通过两个反射模块的迭代优化,提升模仿学习的性能。
关键创新:最重要的技术创新点在于引入了计划反射和代码反射这两个模块。与现有方法直接生成动作序列或代码不同,该方法通过反射机制对生成的计划和代码进行验证和修正,从而显著提高了模仿的准确性和鲁棒性。这种“反思”机制是与现有方法的本质区别。
关键设计:计划反射模块使用时序模型(例如Transformer)来评估动作序列的时序连贯性,并使用空间关系推理模块来检查动作与对象之间的空间对齐性。代码反射模块则使用静态分析和动态测试等技术来验证代码的正确性和一致性。具体的损失函数设计和网络结构细节在论文中进行了详细描述,但未在摘要中体现。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在LongVILBench基准测试中,现有方法表现不佳,而该论文提出的框架显著优于现有方法,为长时程视觉模仿学习建立了一个强大的基线。具体的性能数据和提升幅度需要在论文中查找,摘要中未提供。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、游戏AI等领域。通过模仿人类专家的演示,机器人可以学习执行复杂的装配、导航或决策任务。在自动驾驶领域,可以学习人类驾驶员的驾驶策略,提高自动驾驶系统的安全性和可靠性。在游戏AI领域,可以创建更智能、更逼真的游戏角色。
📄 摘要(原文)
Learning from long-horizon demonstrations with complex action sequences presents significant challenges for visual imitation learning, particularly in understanding temporal relationships of actions and spatial relationships between objects. In this paper, we propose a new agent framework that incorporates two dedicated reflection modules to enhance both plan and code generation. The plan generation module produces an initial action sequence, which is then verified by the plan reflection module to ensure temporal coherence and spatial alignment with the demonstration video. The code generation module translates the plan into executable code, while the code reflection module verifies and refines the generated code to ensure correctness and consistency with the generated plan. These two reflection modules jointly enable the agent to detect and correct errors in both the plan generation and code generation, improving performance in tasks with intricate temporal and spatial dependencies. To support systematic evaluation, we introduce LongVILBench, a benchmark comprising 300 human demonstrations with action sequences of up to 18 steps. LongVILBench emphasizes temporal and spatial complexity across multiple task types. Experimental results demonstrate that existing methods perform poorly on this benchmark, whereas our new framework establishes a strong baseline for long-horizon visual imitation learning.