Surformer v2: A Multimodal Classifier for Surface Understanding from Touch and Vision
作者: Manish Kansana, Sindhuja Penchala, Shahram Rahimi, Noorbakhsh Amiri Golilarz
分类: cs.RO
发布日期: 2025-09-04
备注: 6 pages
💡 一句话要点
Surformer v2:用于触觉与视觉表面理解的多模态分类器
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态融合 表面理解 触觉感知 视觉感知 Transformer 决策级融合 机器人操作
📋 核心要点
- 现有方法在多模态表面材料分类中,特征提取与融合方式较为固定,难以适应不同模态信息的动态变化。
- Surformer v2采用决策级融合,通过可学习权重动态调整视觉和触觉信息的重要性,提升模型对不同表面的适应性。
- 实验结果表明,Surformer v2在Touch and Go数据集上表现良好,并保持了实时性,适用于机器人应用。
📝 摘要(中文)
本文提出Surformer v2,一种增强的多模态分类架构,旨在通过后期(决策级)融合机制整合视觉和触觉感知流,以提升机器人操作和交互的触觉感知能力。Surformer v2基于我们之前的Surformer v1框架,将特征提取过程集成到模型中,并转向后期融合。视觉分支采用基于CNN的分类器(Efficient V-Net),而触觉分支采用仅编码器Transformer模型,使每个模态能够提取针对分类优化的模态特定特征。该模型不是融合特征图,而是通过使用可学习的加权和组合输出logits来执行决策级融合,从而能够根据数据上下文和训练动态自适应地强调每个模态。我们在Touch and Go数据集上评估了Surformer v2,这是一个包含表面图像和相应触觉传感器读数的多模态基准。结果表明,Surformer v2表现良好,保持了具有竞争力的推理速度,适合实时机器人应用。这些发现强调了决策级融合和基于Transformer的触觉建模在增强多模态机器人感知中的表面理解方面的有效性。
🔬 方法详解
问题定义:论文旨在解决机器人触觉感知中,如何有效融合视觉和触觉信息以进行表面材料分类的问题。现有方法,如Surformer v1,采用手工特征提取和中间层融合,限制了模型对模态特定特征的自主学习能力,且融合方式不够灵活,难以适应不同模态信息的动态变化。
核心思路:论文的核心思路是采用后期(决策级)融合,允许视觉和触觉模态分别提取各自的特征,并在决策层通过可学习的权重进行融合。这种方式能够使模型更好地学习模态特定特征,并根据数据上下文动态调整各模态的重要性。
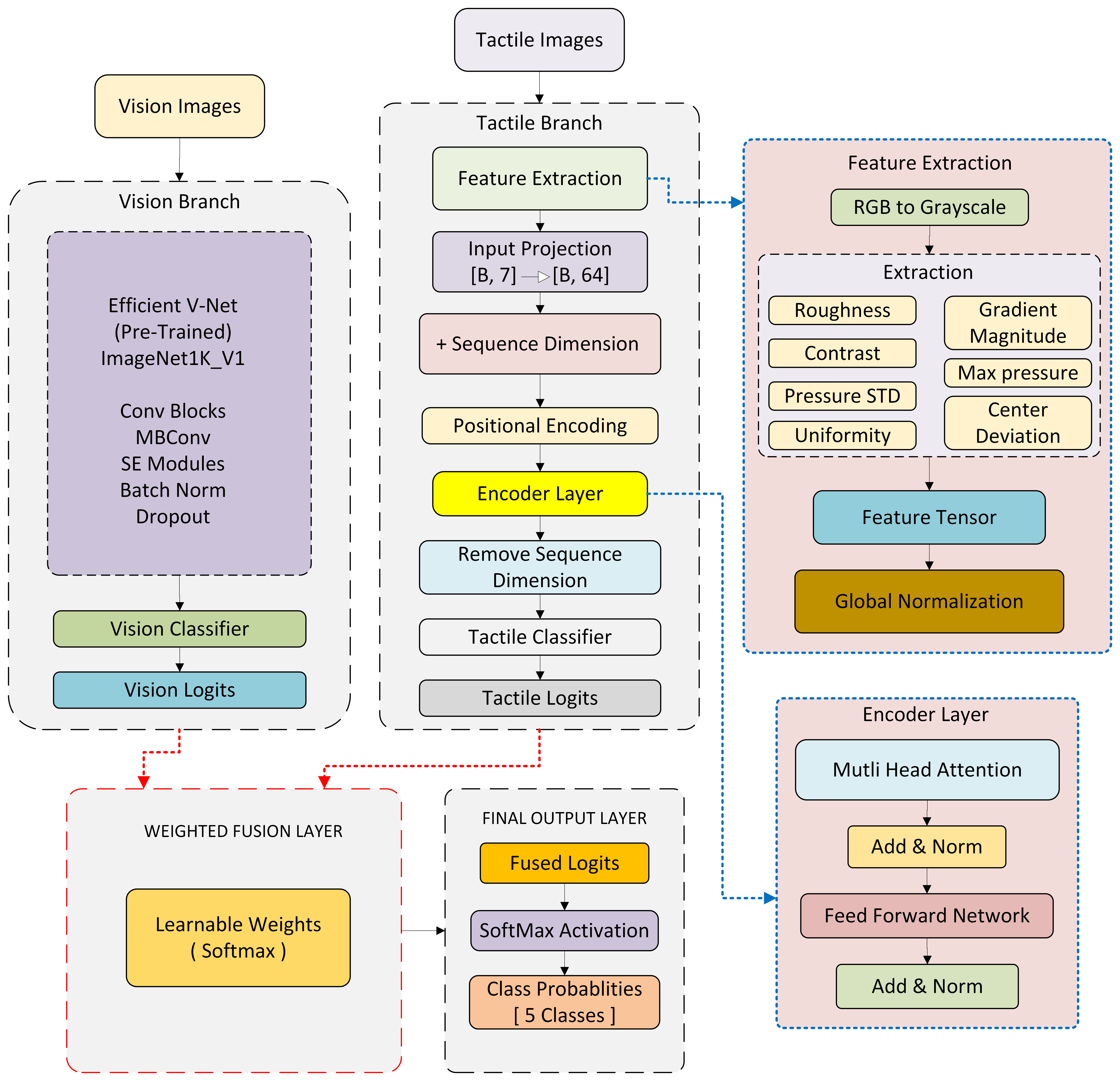
技术框架:Surformer v2包含视觉和触觉两个分支。视觉分支使用Efficient V-Net进行特征提取和分类,触觉分支使用仅编码器的Transformer模型进行特征提取和分类。两个分支分别输出logits,然后通过一个可学习的加权和来融合这些logits,得到最终的分类结果。
关键创新:最重要的技术创新点在于决策级融合和Transformer在触觉数据建模上的应用。决策级融合允许模型根据数据自适应地调整各模态的权重,而Transformer模型能够有效地捕捉触觉数据中的时序关系。与Surformer v1相比,Surformer v2将特征提取集成到模型中,避免了手工特征提取的局限性。
关键设计:视觉分支采用Efficient V-Net,这是一种轻量级的CNN架构,适合实时应用。触觉分支使用仅编码器的Transformer模型,输入是触觉传感器的时序数据。决策级融合使用一个可学习的权重向量,用于加权视觉和触觉分支的输出logits。损失函数采用交叉熵损失,用于训练整个模型。
🖼️ 关键图片

📊 实验亮点
Surformer v2在Touch and Go数据集上进行了评估,结果表明其性能优于Surformer v1。虽然论文中没有给出具体的性能数据和提升幅度,但强调了Surformer v2保持了具有竞争力的推理速度,适合实时机器人应用。这表明决策级融合和Transformer-based触觉建模在提高表面理解能力的同时,也保证了模型的实时性。
🎯 应用场景
该研究成果可应用于机器人操作、物体识别、表面质量检测等领域。例如,机器人可以利用该技术更好地识别和抓取不同材质的物体,从而提高自动化生产线的效率。此外,该技术还可以用于检测物体表面的缺陷,例如划痕或污渍,从而提高产品质量。未来,该技术有望应用于更广泛的机器人感知和交互任务中。
📄 摘要(原文)
Multimodal surface material classification plays a critical role in advancing tactile perception for robotic manipulation and interaction. In this paper, we present Surformer v2, an enhanced multi-modal classification architecture designed to integrate visual and tactile sensory streams through a late(decision level) fusion mechanism. Building on our earlier Surformer v1 framework [1], which employed handcrafted feature extraction followed by mid-level fusion architecture with multi-head cross-attention layers, Surformer v2 integrates the feature extraction process within the model itself and shifts to late fusion. The vision branch leverages a CNN-based classifier(Efficient V-Net), while the tactile branch employs an encoder-only transformer model, allowing each modality to extract modality-specific features optimized for classification. Rather than merging feature maps, the model performs decision-level fusion by combining the output logits using a learnable weighted sum, enabling adaptive emphasis on each modality depending on data context and training dynamics. We evaluate Surformer v2 on the Touch and Go dataset [2], a multi-modal benchmark comprising surface images and corresponding tactile sensor readings. Our results demonstrate that Surformer v2 performs well, maintaining competitive inference speed, suitable for real-time robotic applications. These findings underscore the effectiveness of decision-level fusion and transformer-based tactile modeling for enhancing surface understanding in multi-modal robotic perception.