Planning from Point Clouds over Continuous Actions for Multi-object Rearrangement
作者: Kallol Saha, Amber Li, Angela Rodriguez-Izquierdo, Lifan Yu, Ben Eisner, Maxim Likhachev, David Held
分类: cs.RO
发布日期: 2025-09-04
备注: Conference on Robot Learning (CoRL) 2025 (https://planning-from-point-clouds.github.io/)
💡 一句话要点
提出SPOT:一种基于点云变换搜索的多物体重排规划方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 长时程规划 点云处理 多物体重排 搜索算法 动作规划 强化学习
📋 核心要点
- 长时程机器人操作规划面临着对一系列动作在3D场景中效果的推理难题,传统方法需要离散化状态和动作空间。
- 论文提出SPOT,利用学习模型作为先验,在连续动作空间中搜索点云变换序列,实现多物体重排规划。
- 实验表明,SPOT在仿真和真实环境中均能成功生成规划,优于策略学习方法,并验证了搜索规划的重要性。
📝 摘要(中文)
针对机器人操作中的长时程规划难题,该论文提出了一种混合学习与规划方法,利用学习模型作为领域先验,指导高维连续动作空间中的搜索。论文引入了SPOT(Search over Point cloud Object Transformations),通过搜索从初始场景点云到满足目标场景的点云序列变换来进行规划。SPOT从学习到的建议器中采样候选动作,这些建议器作用于部分观测的点云,从而避免了离散化动作或对象关系。在多对象重排任务中,SPOT在仿真和真实环境中都取得了成功,优于策略学习方法,并验证了基于搜索的规划的重要性。
🔬 方法详解
问题定义:论文旨在解决机器人多物体重排任务中的长时程规划问题。现有方法,如传统任务规划,需要将连续的状态和动作空间离散化为符号描述,这限制了其在高维连续空间的适用性,并且难以处理复杂的对象关系。策略学习方法虽然可以直接学习控制策略,但在长时程任务中往往难以训练和泛化。
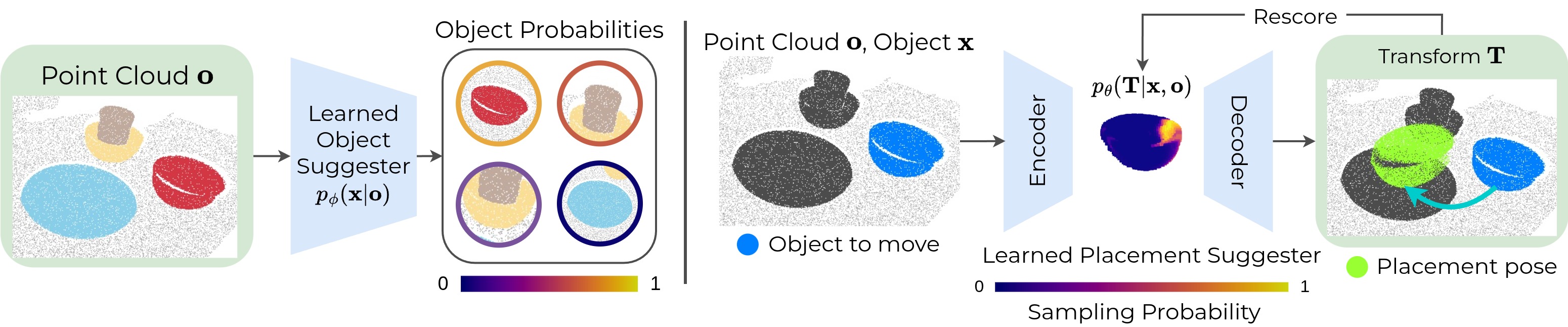
核心思路:论文的核心思路是结合学习和规划的优势。通过学习得到领域相关的先验知识,并利用这些先验知识指导在连续动作空间中的搜索。具体而言,论文学习一个动作建议器,该建议器能够根据当前场景的点云信息,提出可能的动作候选。然后,利用搜索算法在这些候选动作中寻找最优的动作序列,从而实现多物体重排。
技术框架:SPOT的整体框架包含以下几个主要模块:1) 点云观测模块:从环境中获取场景的点云信息。2) 动作建议器:基于点云信息,生成候选动作。该模块通过学习得到,可以预测在当前状态下哪些动作更有可能成功。3) 搜索算法:在候选动作空间中搜索最优的动作序列。论文采用了一种基于采样的搜索算法,例如RRT*。4) 评估函数:评估每个动作序列的质量。评估函数可以基于物理引擎模拟或学习得到。
关键创新:SPOT的关键创新在于将学习到的动作建议器与搜索算法相结合,从而能够在高维连续动作空间中进行有效的规划。与传统任务规划方法相比,SPOT不需要离散化状态和动作空间,可以直接处理连续的场景信息。与策略学习方法相比,SPOT利用搜索算法来探索动作空间,可以更好地处理长时程任务。
关键设计:动作建议器通常采用神经网络结构,输入是部分观测的点云,输出是候选动作的概率分布。损失函数可以采用交叉熵损失或hinge loss,鼓励建议器预测正确的动作。搜索算法可以采用RRT*或其他基于采样的算法。评估函数可以基于物理引擎模拟,也可以通过学习得到。关键参数包括建议器的网络结构、学习率、搜索算法的采样率等。
🖼️ 关键图片


📊 实验亮点
实验结果表明,SPOT在多物体重排任务中取得了显著的成功。在仿真环境中,SPOT的规划成功率明显高于策略学习方法。在真实环境中,SPOT也能够成功完成复杂的重排任务,验证了其在实际应用中的可行性。消融实验表明,基于搜索的规划对于SPOT的成功至关重要。
🎯 应用场景
该研究成果可应用于自动化仓库、家庭服务机器人、工业机器人等领域。通过该方法,机器人可以自主完成复杂的物体重排任务,提高工作效率和智能化水平。未来,该技术有望扩展到更复杂的机器人操作任务,例如装配、拆卸等。
📄 摘要(原文)
Long-horizon planning for robot manipulation is a challenging problem that requires reasoning about the effects of a sequence of actions on a physical 3D scene. While traditional task planning methods are shown to be effective for long-horizon manipulation, they require discretizing the continuous state and action space into symbolic descriptions of objects, object relationships, and actions. Instead, we propose a hybrid learning-and-planning approach that leverages learned models as domain-specific priors to guide search in high-dimensional continuous action spaces. We introduce SPOT: Search over Point cloud Object Transformations, which plans by searching for a sequence of transformations from an initial scene point cloud to a goal-satisfying point cloud. SPOT samples candidate actions from learned suggesters that operate on partially observed point clouds, eliminating the need to discretize actions or object relationships. We evaluate SPOT on multi-object rearrangement tasks, reporting task planning success and task execution success in both simulation and real-world environments. Our experiments show that SPOT generates successful plans and outperforms a policy-learning approach. We also perform ablations that highlight the importance of search-based planning.