Learning Multi-Stage Pick-and-Place with a Legged Mobile Manipulator
作者: Haichao Zhang, Haonan Yu, Le Zhao, Andrew Choi, Qinxun Bai, Yiqing Yang, Wei Xu
分类: cs.RO
发布日期: 2025-09-04 (更新: 2025-09-08)
备注: Accepted to IEEE Robotics and Automation Letters (RA-L). Tech Report: arXiv:2501.09905
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出基于强化学习的多阶段移动操作方法,解决四足机器人复杂操作任务
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 四足机器人 移动操作 强化学习 抓取放置 Sim-to-Real
📋 核心要点
- 四足移动操作机器人需要掌握多种技能,任务周期长,且存在部分可观测性问题,这给机器人控制带来了巨大挑战。
- 论文提出了一种基于强化学习的策略,完全在模拟环境中训练,能够有效执行搜索、接近、抓取、运输和放置等动作。
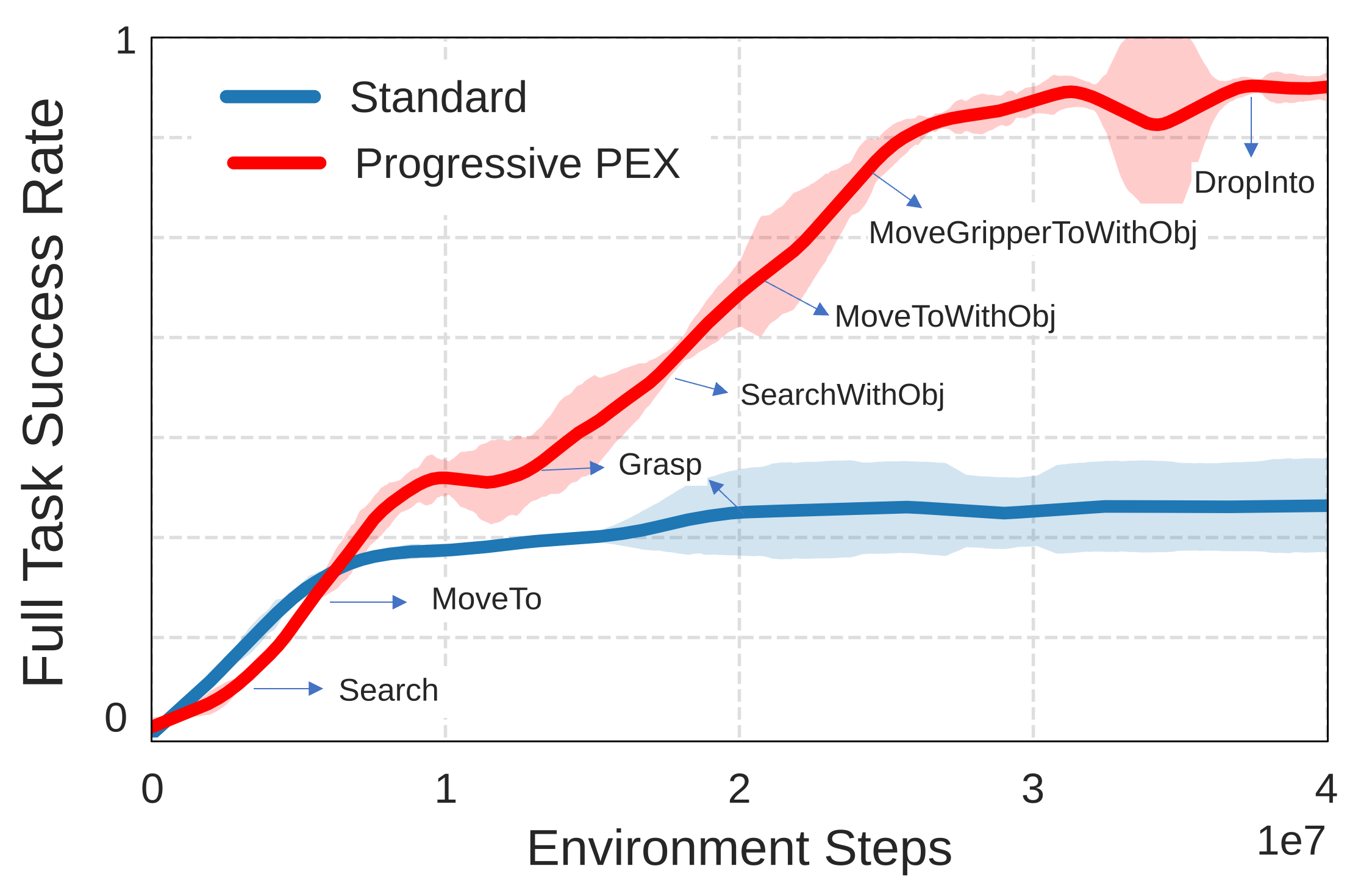
- 实验结果表明,该方法在真实世界中实现了近80%的成功率,并在各种室内和室外环境中进行了部署验证。
📝 摘要(中文)
基于四足机器人的移动操作由于所需技能的多样性、任务时间跨度长以及部分可观测性,在机器人领域提出了重大挑战。本文将多阶段抓取放置任务作为一个简洁而充分丰富的设置,以捕捉基于四足机器人的移动操作的关键需求。我们提出了一种完全在模拟环境中训练视觉运动策略的方法,并在现实世界中实现了近80%的成功率。该策略有效地执行搜索、接近、抓取、运输和放置等动作,并涌现出诸如重新抓取和任务链等行为。我们进行了一系列广泛的真实世界实验,并通过消融研究突出了有效训练和有效的模拟到真实迁移的关键技术。额外的实验证明了在各种室内和室外环境中的部署。
🔬 方法详解
问题定义:论文旨在解决四足移动操作机器人在复杂环境下的多阶段抓取放置任务。现有方法通常难以应对技能多样性、长任务周期和部分可观测性带来的挑战,导致泛化能力和鲁棒性不足。
核心思路:论文的核心思路是利用强化学习在模拟环境中训练一个能够执行多阶段任务的视觉运动策略。通过精心设计的奖励函数和训练流程,使机器人能够自主学习搜索、接近、抓取、运输和放置等动作,并具备一定的泛化能力。
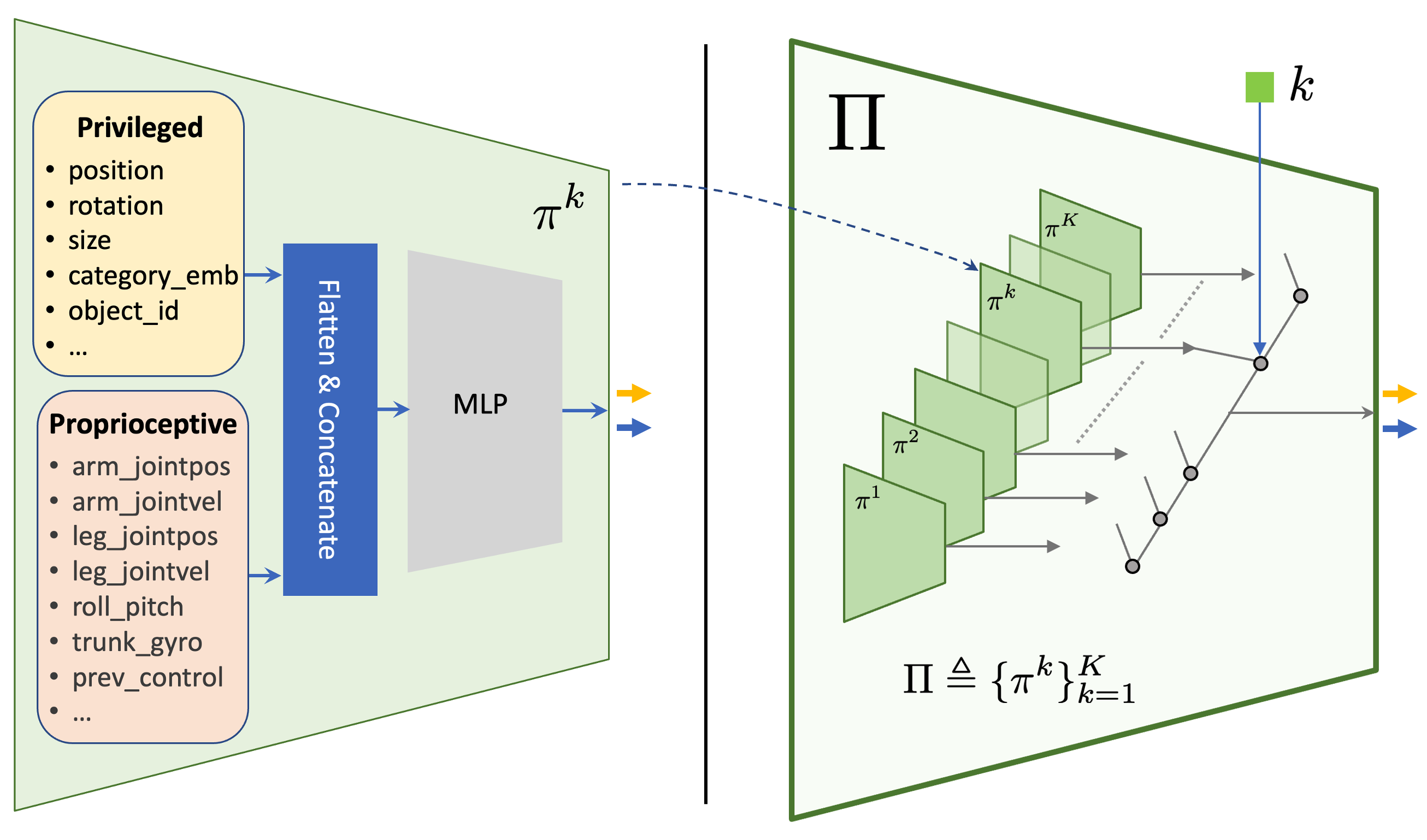
技术框架:整体框架包含以下几个主要阶段:1) 搜索:机器人利用视觉信息搜索目标物体;2) 接近:机器人调整自身姿态,靠近目标物体;3) 抓取:机器人执行抓取动作;4) 运输:机器人携带目标物体移动到目标位置;5) 放置:机器人将目标物体放置到指定位置。整个过程通过一个统一的强化学习策略进行控制。
关键创新:最重要的技术创新在于能够完全在模拟环境中训练出一个鲁棒的视觉运动策略,并通过有效的sim-to-real迁移技术,使其能够在真实世界中成功部署。此外,该方法还能够涌现出一些复杂的行为,例如重新抓取和任务链。
关键设计:论文中使用了GAIL(Generative Adversarial Imitation Learning)算法进行策略学习,并设计了针对性的奖励函数,鼓励机器人完成各个阶段的任务。为了提高sim-to-real的迁移效果,论文还采用了domain randomization等技术,增加模拟环境的多样性。
🖼️ 关键图片
📊 实验亮点
该方法在真实世界中实现了近80%的抓取放置成功率,显著优于传统的基于规则或优化的方法。通过消融实验,验证了各个模块和技术的有效性,例如domain randomization对于提高sim-to-real迁移效果至关重要。此外,该方法还在多种室内和室外环境中进行了部署验证,证明了其泛化能力。
🎯 应用场景
该研究成果可应用于物流、仓储、家庭服务、灾难救援等领域。例如,在物流仓储中,四足机器人可以自主完成货物的拣选和搬运;在家庭服务中,可以帮助人们完成一些日常的物品整理和放置;在灾难救援中,可以进入危险区域搜寻和搬运物资。该研究为四足移动操作机器人的实际应用奠定了基础。
📄 摘要(原文)
Quadruped-based mobile manipulation presents significant challenges in robotics due to the diversity of required skills, the extended task horizon, and partial observability. After presenting a multi-stage pick-and-place task as a succinct yet sufficiently rich setup that captures key desiderata for quadruped-based mobile manipulation, we propose an approach that can train a visuo-motor policy entirely in simulation, and achieve nearly 80\% success in the real world. The policy efficiently performs search, approach, grasp, transport, and drop into actions, with emerged behaviors such as re-grasping and task chaining. We conduct an extensive set of real-world experiments with ablation studies highlighting key techniques for efficient training and effective sim-to-real transfer. Additional experiments demonstrate deployment across a variety of indoor and outdoor environments. Demo videos and additional resources are available on the project page: https://horizonrobotics.github.io/gail/SLIM.