Multi-Embodiment Locomotion at Scale with extreme Embodiment Randomization
作者: Nico Bohlinger, Jan Peters
分类: cs.RO, cs.LG
发布日期: 2025-09-02
💡 一句话要点
提出基于极端形态随机化的多形态通用运动策略,实现零样本迁移
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人运动控制 强化学习 形态随机化 零样本迁移 具身智能
📋 核心要点
- 现有运动控制策略难以泛化到不同形态的机器人,需要为每种机器人单独设计控制器。
- 论文提出一种基于极端形态随机化的通用运动策略,通过在大量形态各异的机器人上训练,提高策略的泛化能力。
- 实验表明,该策略能够零样本迁移到真实世界的人形和四足机器人上,无需针对特定机器人进行微调。
📝 摘要(中文)
本文提出了一种通用的运动策略,该策略在包含50种不同腿式机器人的多样化集合上进行训练。通过结合改进的具身感知架构(URMAv2)和基于性能的极端形态随机化课程,我们的策略学会控制数百万种形态变异。该策略实现了对未见过的真实世界人形和四足机器人的零样本迁移。
🔬 方法详解
问题定义:现有机器人运动控制方法通常针对特定机器人设计,难以泛化到不同形态的机器人上。为每种新机器人设计控制器耗时耗力。因此,需要一种能够控制多种不同形态机器人的通用运动策略。
核心思路:论文的核心思路是通过极端形态随机化来训练一个通用的运动策略。具体来说,在训练过程中,随机改变机器人的形态参数,例如腿长、关节角度范围、质量分布等,从而使策略能够适应各种不同的机器人形态。这种方法类似于数据增强,可以提高策略的泛化能力。
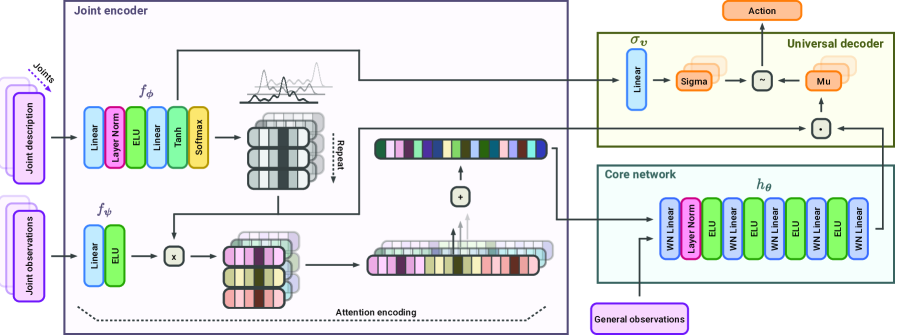
技术框架:整体框架包含以下几个主要模块:1) 具身感知模块:用于提取机器人的形态信息,例如腿长、关节角度等。论文使用URMAv2架构,该架构能够更好地捕捉机器人的形态特征。2) 运动控制模块:根据具身感知模块提取的形态信息,生成机器人的运动控制指令。3) 训练模块:使用强化学习算法训练运动控制模块,目标是使机器人能够稳定行走或完成其他运动任务。论文使用基于性能的课程学习方法,逐步增加训练难度。
关键创新:最重要的技术创新点是极端形态随机化。与传统的形态随机化方法相比,论文提出的方法能够生成更加多样化的机器人形态,从而使策略能够适应更加广泛的机器人类型。此外,URMAv2架构也提高了具身感知模块的性能。
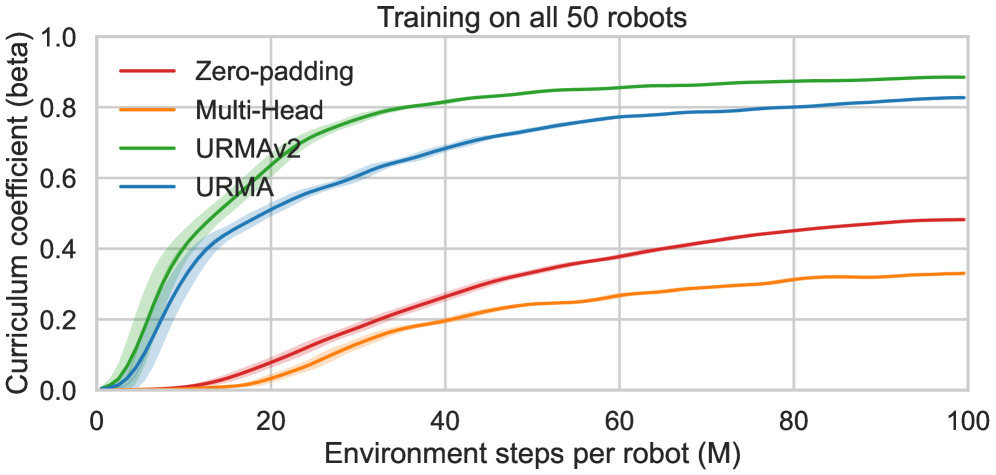
关键设计:论文使用了一种基于性能的课程学习方法,逐步增加训练难度。具体来说,首先在简单的机器人形态上训练策略,然后逐渐增加机器人形态的复杂度和随机性。这种方法可以避免策略在训练初期就陷入局部最优解。损失函数包括运动稳定性损失、运动速度损失和能量消耗损失。网络结构采用循环神经网络(RNN),能够处理时序信息。
🖼️ 关键图片

📊 实验亮点
该策略在50种不同腿式机器人上进行训练,并成功实现了对未见过的真实世界人形和四足机器人的零样本迁移。实验结果表明,该策略能够使这些机器人稳定行走,并完成一些基本的运动任务。与传统的运动控制方法相比,该策略具有更强的泛化能力和适应性。
🎯 应用场景
该研究成果可应用于各种需要多形态机器人协同工作的场景,例如搜救、物流、探索等。通过训练一个通用的运动策略,可以大大降低机器人控制器的开发成本,并提高机器人的适应性和灵活性。未来,该技术有望应用于人形机器人、四足机器人、甚至软体机器人等各种类型的机器人。
📄 摘要(原文)
We present a single, general locomotion policy trained on a diverse collection of 50 legged robots. By combining an improved embodiment-aware architecture (URMAv2) with a performance-based curriculum for extreme Embodiment Randomization, our policy learns to control millions of morphological variations. Our policy achieves zero-shot transfer to unseen real-world humanoid and quadruped robots.