Disentangled Multi-Context Meta-Learning: Unlocking robust and Generalized Task Learning
作者: Seonsoo Kim, Jun-Gill Kang, Taehong Kim, Seongil Hong
分类: cs.RO
发布日期: 2025-09-01
备注: Accepted to The Conference on Robot Learning (CoRL) 2025 Project Page: seonsoo-p1.github.io/DMCM
💡 一句话要点
提出解耦多上下文元学习框架,提升任务泛化性和鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 元学习 解耦表示 多上下文学习 领域泛化 机器人控制
📋 核心要点
- 现有元学习方法依赖隐式适应,导致任务因素纠缠,难以解释和泛化。
- 提出解耦多上下文元学习,将每个任务因素显式分配给不同的上下文向量。
- 实验表明,该方法在正弦回归和四足机器人运动任务中均提升了鲁棒性和泛化性。
📝 摘要(中文)
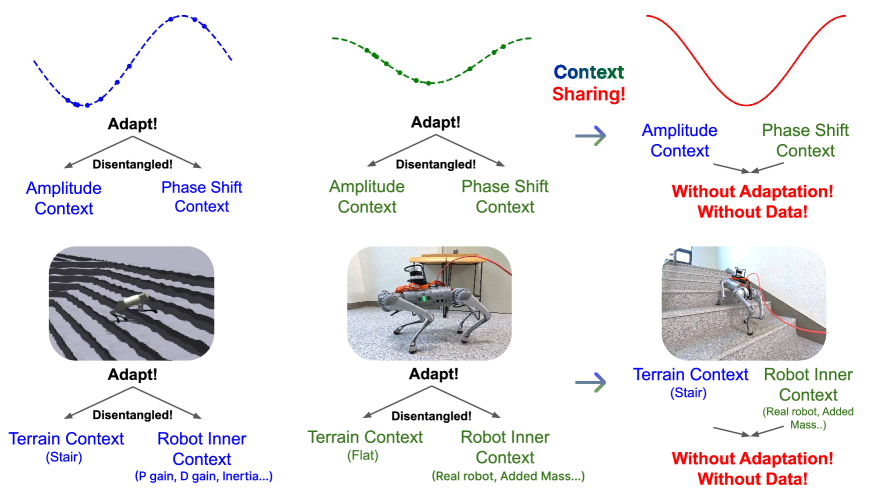
在元学习及其下游任务中,许多方法依赖于对任务变化的隐式适应,其中多个因素混合在单一的纠缠表示中。这使得难以解释哪些因素驱动性能,并可能阻碍泛化。本文提出了一种解耦多上下文元学习框架,该框架显式地将每个任务因素分配给一个不同的上下文向量。通过解耦这些变化,我们的方法通过更深入的任务理解提高了鲁棒性,并通过在具有共享因素的任务之间共享上下文向量来增强泛化。我们在两个领域评估了我们的方法。首先,在正弦回归任务中,我们的模型在分布外任务上优于基线,并通过共享与共享振幅或相移相关的上下文向量来泛化到未见过的正弦函数。其次,在四足机器人运动任务中,我们解耦了机器人特定的属性和机器人动力学模型中地形的特征。通过将从动力学模型中获得的解耦上下文向量转移到强化学习中,所得到的策略在分布外条件下实现了改进的鲁棒性,超过了依赖于单一统一上下文的基线。此外,通过有效地共享上下文,我们的模型能够成功地将模拟到真实的策略转移到具有分布外机器人特定属性的具有挑战性的地形,仅使用来自平坦地形的20秒真实数据,这是单任务适应无法实现的结果。
🔬 方法详解
问题定义:现有元学习方法在处理具有复杂变化的任务时,通常将多个影响因素(例如,不同的环境参数、机器人属性等)混合在单一的表示中。这种“纠缠”的表示使得模型难以理解哪些因素对性能起关键作用,从而限制了模型在新的、未见过的任务上的泛化能力。此外,当某些因素超出训练分布时,模型的鲁棒性也会受到影响。
核心思路:本文的核心思路是将任务中不同的影响因素解耦,并为每个因素分配一个独立的上下文向量。通过这种方式,模型可以更清晰地理解每个因素对任务的影响,并能够更好地利用这些信息进行学习和泛化。此外,当不同的任务共享某些因素时,模型可以通过共享相应的上下文向量来实现知识迁移。
技术框架:该框架包含以下几个主要模块:1) 上下文编码器:用于将任务信息编码成多个解耦的上下文向量,每个向量对应一个特定的任务因素。2) 任务解码器:利用这些解耦的上下文向量来预测任务相关的参数或行为。3) 解耦损失:用于鼓励上下文向量之间的独立性,从而实现因素的解耦。整体流程是,给定一个任务,首先使用上下文编码器提取解耦的上下文向量,然后使用任务解码器利用这些向量进行预测或控制。
关键创新:该论文最重要的创新点在于提出了一个显式解耦任务因素的元学习框架。与以往的隐式适应方法不同,该方法能够更清晰地理解任务的内在结构,并能够更好地利用这些结构进行学习和泛化。此外,该方法还能够通过共享上下文向量来实现知识迁移,从而提高学习效率。
关键设计:在上下文编码器方面,可以使用多种神经网络结构,例如多层感知机或循环神经网络。解耦损失可以使用多种方法来实现,例如互信息最小化或对抗训练。在四足机器人运动任务中,作者将机器人特定的属性(例如,质量、摩擦力)和地形的特征作为需要解耦的因素。他们使用对比学习来学习地形的表示,并使用对抗训练来解耦机器人属性和地形特征。
🖼️ 关键图片


📊 实验亮点
在正弦回归任务中,该模型在分布外任务上优于基线,并通过共享上下文向量泛化到未见过的正弦函数。在四足机器人运动任务中,该模型在分布外条件下实现了改进的鲁棒性,超过了依赖于单一统一上下文的基线。更重要的是,该模型仅使用20秒的真实数据,就成功地将模拟到真实的策略转移到具有挑战性的地形,而单任务适应无法实现。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、医疗诊断等领域。例如,在机器人控制中,可以利用该方法训练出能够适应不同环境和机器人属性的鲁棒控制策略。在自动驾驶中,可以利用该方法提高车辆在复杂交通场景下的感知和决策能力。在医疗诊断中,可以利用该方法分析患者的多种生理指标,从而更准确地诊断疾病。
📄 摘要(原文)
In meta-learning and its downstream tasks, many methods rely on implicit adaptation to task variations, where multiple factors are mixed together in a single entangled representation. This makes it difficult to interpret which factors drive performance and can hinder generalization. In this work, we introduce a disentangled multi-context meta-learning framework that explicitly assigns each task factor to a distinct context vector. By decoupling these variations, our approach improves robustness through deeper task understanding and enhances generalization by enabling context vector sharing across tasks with shared factors. We evaluate our approach in two domains. First, on a sinusoidal regression task, our model outperforms baselines on out-of-distribution tasks and generalizes to unseen sine functions by sharing context vectors associated with shared amplitudes or phase shifts. Second, in a quadruped robot locomotion task, we disentangle the robot-specific properties and the characteristics of the terrain in the robot dynamics model. By transferring disentangled context vectors acquired from the dynamics model into reinforcement learning, the resulting policy achieves improved robustness under out-of-distribution conditions, surpassing the baselines that rely on a single unified context. Furthermore, by effectively sharing context, our model enables successful sim-to-real policy transfer to challenging terrains with out-of-distribution robot-specific properties, using just 20 seconds of real data from flat terrain, a result not achievable with single-task adaptation.