EO-1: Interleaved Vision-Text-Action Pretraining for General Robot Control
作者: Delin Qu, Haoming Song, Qizhi Chen, Zhaoqing Chen, Xianqiang Gao, Xinyi Ye, Qi Lv, Modi Shi, Guanghui Ren, Cheng Ruan, Maoqing Yao, Haoran Yang, Jiacheng Bao, Bin Zhao, Dong Wang
分类: cs.RO, cs.AI
发布日期: 2025-08-28 (更新: 2025-10-15)
💡 一句话要点
EO-1:用于通用机器人控制的交错式视觉-文本-动作预训练模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 多模态学习 具身智能 预训练模型 视觉-语言-动作 交错式学习 开放世界 长时程操作
📋 核心要点
- 现有VLA模型在通用机器人控制方面取得进展,但仍缺乏人类在交错推理和交互方面的灵活性。
- EO-1通过统一架构和大规模多模态数据集,实现无缝机器人动作生成和多模态具身推理。
- 实验验证了EO-1在开放世界理解和泛化方面的有效性,尤其是在长时程灵巧操作任务中。
📝 摘要(中文)
本文提出了EO-Robotics,它包含EO-1模型和EO-Data1.5M数据集。EO-1是一个统一的具身基础模型,通过交错式的视觉-文本-动作预训练,在多模态具身推理和机器人控制方面实现了卓越的性能。EO-1的开发基于两个关键支柱:(i) 一个不加区分地处理多模态输入(图像、文本、视频和动作)的统一架构,以及 (ii) 一个大规模、高质量的多模态具身推理数据集EO-Data1.5M,其中包含超过150万个样本,重点关注交错式的视觉-文本-动作理解。EO-1通过自回归解码和流匹配去噪之间的协同作用在EO-Data1.5M上进行训练,从而实现无缝的机器人动作生成和多模态具身推理。大量实验证明了交错式视觉-文本-动作学习对于开放世界理解和泛化的有效性,并通过跨多个embodiment的各种长时程、灵巧操作任务进行了验证。本文详细介绍了EO-1的架构、EO-Data1.5M的数据构建策略以及训练方法,为开发先进的具身基础模型提供了宝贵的见解。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在机器人控制方面取得了一定进展,但它们在开放世界中进行多模态推理和物理交互时,仍然缺乏人类级别的灵活性。这些模型难以在视觉、文本和动作之间进行流畅的交错推理和交互,限制了其在复杂任务中的应用。
核心思路:EO-1的核心思路是通过交错式的视觉-文本-动作预训练,使模型能够更好地理解和生成多模态信息。通过构建一个统一的架构,模型可以不加区分地处理各种模态的输入,并学习它们之间的关联。此外,EO-Data1.5M数据集的构建也旨在提供高质量的交错式数据,从而提高模型的推理和泛化能力。
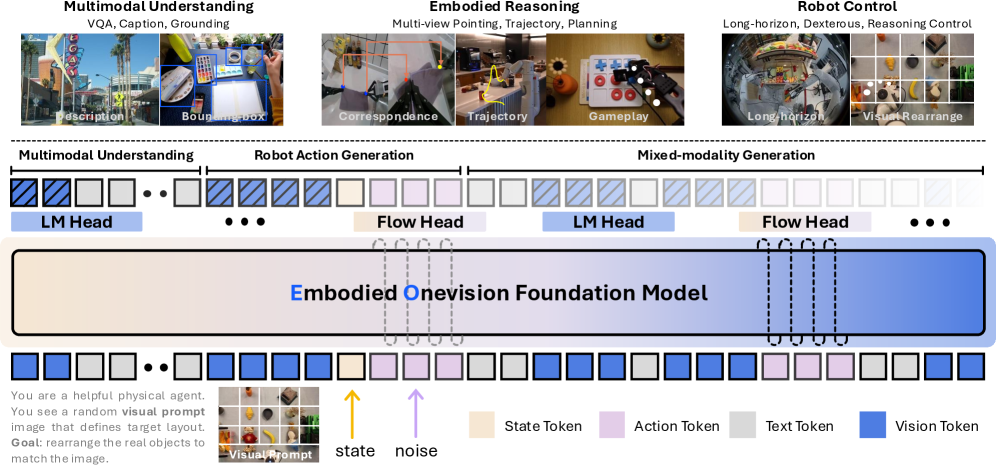
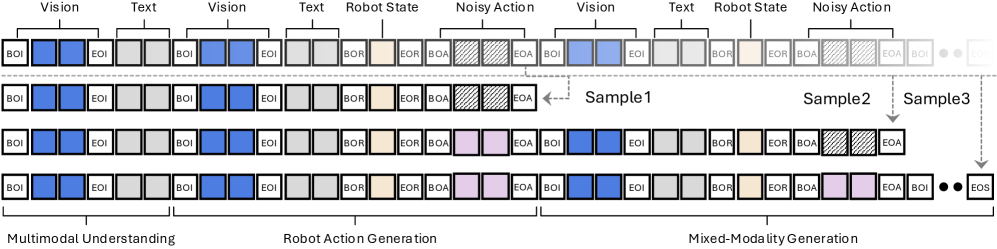
技术框架:EO-1采用统一的架构,可以处理图像、文本、视频和动作等多种模态的输入。模型通过自回归解码和流匹配去噪两种方式进行训练。自回归解码用于生成动作序列,而流匹配去噪则用于提高模型的鲁棒性和泛化能力。EO-Data1.5M数据集包含超过150万个样本,涵盖了各种机器人控制任务和场景。
关键创新:EO-1的关键创新在于其交错式的视觉-文本-动作预训练方法和统一的架构。与以往的模型相比,EO-1能够更好地理解和生成多模态信息,从而在机器人控制任务中表现出更高的性能。此外,EO-Data1.5M数据集的构建也为模型的训练提供了高质量的数据支持。
关键设计:EO-1的训练采用了自回归解码和流匹配去噪两种方法。自回归解码使用Transformer架构,通过预测下一个动作来生成动作序列。流匹配去噪则通过添加噪声到输入数据中,然后训练模型来恢复原始数据,从而提高模型的鲁棒性。EO-Data1.5M数据集的构建采用了多种数据增强技术,以提高模型的泛化能力。具体参数设置和网络结构细节在论文中有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
EO-1在多个长时程、灵巧操作任务中表现出色,验证了交错式视觉-文本-动作学习的有效性。具体性能数据和对比基线在论文中有详细描述(未知),但总体而言,EO-1在开放世界理解和泛化方面取得了显著提升,证明了其在机器人控制领域的潜力。
🎯 应用场景
EO-1具有广泛的应用前景,可用于各种机器人控制任务,如家庭服务机器人、工业自动化机器人和医疗机器人等。该模型可以帮助机器人更好地理解人类指令,并在复杂环境中执行任务。此外,EO-1还可以用于开发更智能的虚拟助手和游戏角色,从而提高人机交互的自然性和流畅性。
📄 摘要(原文)
The human ability to seamlessly perform multimodal reasoning and physical interaction in the open world is a core goal for general-purpose embodied intelligent systems. Recent vision-language-action (VLA) models, which are co-trained on large-scale robot and visual-text data, have demonstrated notable progress in general robot control. However, they still fail to achieve human-level flexibility in interleaved reasoning and interaction. In this work, introduce EO-Robotics, consists of EO-1 model and EO-Data1.5M dataset. EO-1 is a unified embodied foundation model that achieves superior performance in multimodal embodied reasoning and robot control through interleaved vision-text-action pre-training. The development of EO-1 is based on two key pillars: (i) a unified architecture that processes multimodal inputs indiscriminately (image, text, video, and action), and (ii) a massive, high-quality multimodal embodied reasoning dataset, EO-Data1.5M, which contains over 1.5 million samples with emphasis on interleaved vision-text-action comprehension. EO-1 is trained through synergies between auto-regressive decoding and flow matching denoising on EO-Data1.5M, enabling seamless robot action generation and multimodal embodied reasoning. Extensive experiments demonstrate the effectiveness of interleaved vision-text-action learning for open-world understanding and generalization, validated through a variety of long-horizon, dexterous manipulation tasks across multiple embodiments. This paper details the architecture of EO-1, the data construction strategy of EO-Data1.5M, and the training methodology, offering valuable insights for developing advanced embodied foundation models.