Learning on the Fly: Rapid Policy Adaptation via Differentiable Simulation
作者: Jiahe Pan, Jiaxu Xing, Rudolf Reiter, Yifan Zhai, Elie Aljalbout, Davide Scaramuzza
分类: cs.RO
发布日期: 2025-08-28 (更新: 2026-01-14)
期刊: IEEE Robotics and Automation Letters (RA-L), 2026
💡 一句话要点
提出基于可微仿真的在线自适应学习框架,实现四旋翼飞行器快速策略调整。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 可微仿真 在线学习 策略自适应 残差动力学 四旋翼控制
📋 核心要点
- 现有方法难以应对真实世界中未建模的动态和环境扰动,导致策略性能下降,离线重训练成本高昂。
- 该方法提出一种在线自适应学习框架,通过可微仿真融合残差动力学学习和实时策略调整,实现快速策略更新。
- 实验结果表明,该框架在四旋翼控制中显著降低了悬停误差,并在视觉控制中表现出良好的鲁棒性。
📝 摘要(中文)
本文提出了一种在线自适应学习框架,旨在解决仿真策略向真实世界迁移时性能下降的问题。该框架将残差动力学学习与实时策略调整相结合,嵌入到可微仿真中。从简单的动力学模型出发,框架利用真实世界数据持续优化模型,捕捉未建模的效应和扰动,如载荷变化和风力。改进后的动力学模型被嵌入到可微仿真框架中,从而能够通过动力学进行梯度反向传播,实现快速、高效的策略更新,超越了传统强化学习方法(如PPO)的能力。系统的所有组件都为快速适应而设计,使策略能够在5秒内调整以适应未知的扰动。在模拟和真实世界的各种扰动下,对敏捷四旋翼控制进行了验证。结果表明,与L1-MPC相比,悬停误差降低了高达81%,与DATT相比降低了55%,并且在没有显式状态估计的情况下,展示了基于视觉控制的鲁棒性。
🔬 方法详解
问题定义:现有方法,如域随机化和Real2Sim2Real流水线,在提高策略鲁棒性方面存在局限性。域随机化难以泛化到分布外的条件,而Real2Sim2Real流水线需要昂贵的离线重训练。因此,需要一种能够在真实世界中快速适应的在线学习方法,以应对未建模的动力学和环境扰动。
核心思路:核心思路是在线学习残差动力学模型,并将其嵌入到可微仿真环境中。通过真实世界的数据不断优化动力学模型,使其能够捕捉未建模的效应和扰动。利用可微仿真,可以计算策略梯度,从而实现快速的策略更新。这种方法避免了离线重训练的需要,并且能够快速适应新的环境。
技术框架:该框架包含以下主要模块:1) 初始动力学模型;2) 残差动力学学习模块,用于学习未建模的动力学;3) 可微仿真环境,将动力学模型嵌入其中,并支持梯度反向传播;4) 策略优化模块,利用梯度信息更新策略。整个流程是:首先,使用初始动力学模型进行仿真训练得到一个初始策略。然后,在真实世界中部署该策略,并收集数据。利用收集到的数据学习残差动力学模型,并更新可微仿真环境。最后,利用可微仿真环境计算策略梯度,并更新策略。
关键创新:最重要的技术创新点是将残差动力学学习与可微仿真相结合,实现快速的在线策略适应。与传统的强化学习方法相比,该方法能够利用梯度信息进行策略更新,从而实现更高的样本效率和更快的适应速度。与离线重训练方法相比,该方法能够避免昂贵的计算成本,并且能够快速适应新的环境。
关键设计:残差动力学模型可以使用神经网络进行建模,损失函数可以设计为预测误差的均方误差。可微仿真环境可以使用现有的物理引擎,例如MuJoCo或PyBullet,并对其进行修改以支持梯度反向传播。策略优化可以使用梯度下降算法,例如Adam或SGD。关键参数包括学习率、残差动力学模型的网络结构、仿真步长等。
🖼️ 关键图片
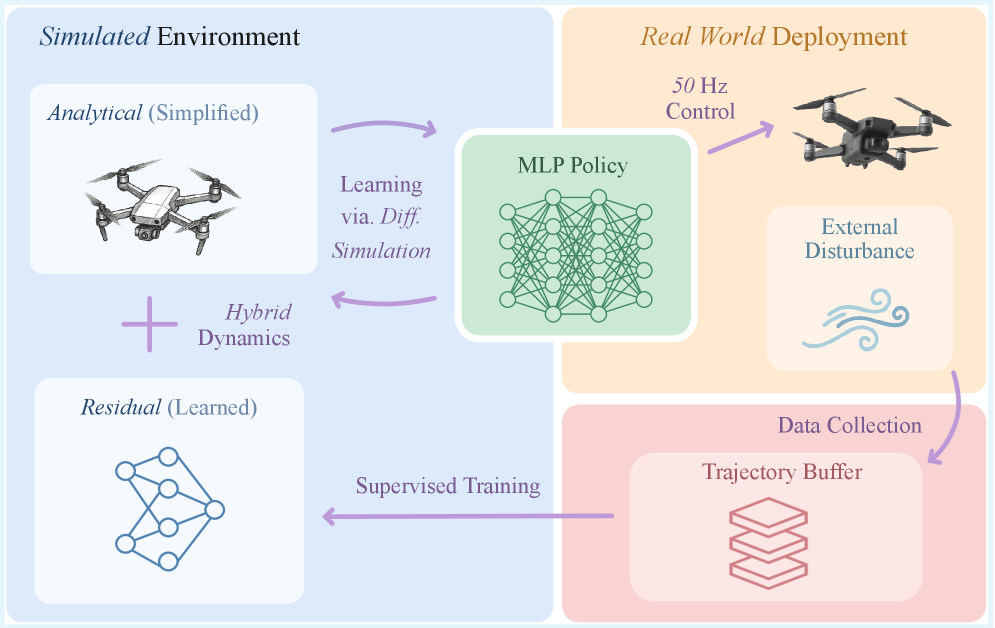

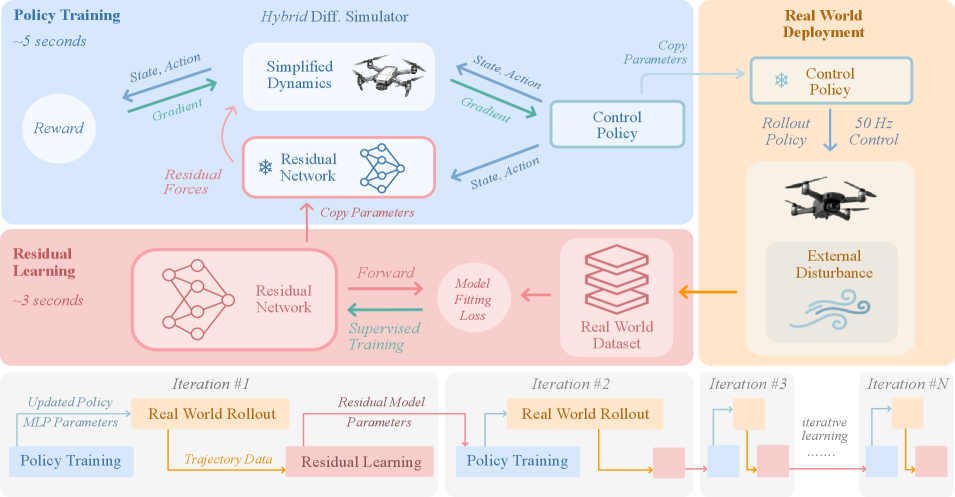
📊 实验亮点
实验结果表明,该框架在四旋翼控制任务中取得了显著的性能提升。与L1-MPC相比,悬停误差降低了高达81%,与DATT相比降低了55%。此外,该框架还在视觉控制任务中展示了良好的鲁棒性,无需显式状态估计。该框架能够在5秒内调整策略以适应未知的扰动,证明了其快速适应能力。
🎯 应用场景
该研究成果可应用于各种需要快速适应环境变化的机器人控制任务,例如无人机自主导航、机器人操作、自动驾驶等。特别是在复杂、动态的环境中,该方法能够显著提高机器人的鲁棒性和适应性,降低开发和维护成本。未来,该方法有望推动机器人技术在更多领域的应用,例如物流、农业、医疗等。
📄 摘要(原文)
Learning control policies in simulation enables rapid, safe, and cost-effective development of advanced robotic capabilities. However, transferring these policies to the real world remains difficult due to the sim-to-real gap, where unmodeled dynamics and environmental disturbances can degrade policy performance. Existing approaches, such as domain randomization and Real2Sim2Real pipelines, can improve policy robustness, but either struggle under out-of-distribution conditions or require costly offline retraining. In this work, we approach these problems from a different perspective. Instead of relying on diverse training conditions before deployment, we focus on rapidly adapting the learned policy in the real world in an online fashion. To achieve this, we propose a novel online adaptive learning framework that unifies residual dynamics learning with real-time policy adaptation inside a differentiable simulation. Starting from a simple dynamics model, our framework refines the model continuously with real-world data to capture unmodeled effects and disturbances such as payload changes and wind. The refined dynamics model is embedded in a differentiable simulation framework, enabling gradient backpropagation through the dynamics and thus rapid, sample-efficient policy updates beyond the reach of classical RL methods like PPO. All components of our system are designed for rapid adaptation, enabling the policy to adjust to unseen disturbances within 5 seconds of training. We validate the approach on agile quadrotor control under various disturbances in both simulation and the real world. Our framework reduces hovering error by up to 81% compared to L1-MPC and 55% compared to DATT, while also demonstrating robustness in vision-based control without explicit state estimation.