Learning Primitive Embodied World Models: Towards Scalable Robotic Learning
作者: Qiao Sun, Liujia Yang, Wei Tang, Wei Huang, Kaixin Xu, Yongchao Chen, Mingyu Liu, Jiange Yang, Haoyi Zhu, Yating Wang, Tong He, Yilun Chen, Xili Dai, Nanyang Ye, Qinying Gu
分类: cs.RO, cs.AI, cs.MM
发布日期: 2025-08-28 (更新: 2025-11-24)
💡 一句话要点
提出原始具身世界模型(PEWM),提升机器人学习的可扩展性和数据效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 具身智能 世界模型 机器人学习 视频生成 视觉语言模型
📋 核心要点
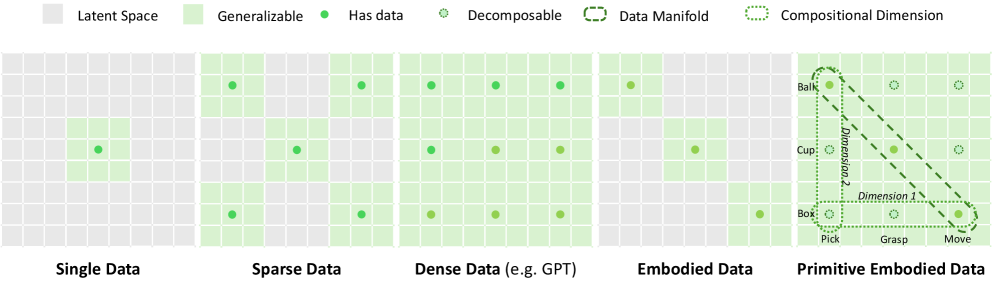
- 现有基于视频生成的具身世界模型依赖大量交互数据,数据收集困难且维度高,限制了语言与动作的对齐粒度。
- 论文提出原始具身世界模型(PEWM),通过限制短视域视频生成,实现细粒度对齐,降低学习复杂度,提升数据效率。
- PEWM结合VLM规划器和SGG机制,实现灵活闭环控制,支持复杂任务中原始策略的组合泛化。
📝 摘要(中文)
本文提出了一种新的世界建模范式——原始具身世界模型(PEWM),旨在解决基于视频生成的具身世界模型对大规模具身交互数据的依赖问题。PEWM通过将视频生成限制在固定的短视域内,实现了语言概念与机器人动作视觉表示之间的细粒度对齐,降低了学习复杂性,提高了具身数据收集的数据效率,并降低了推理延迟。PEWM配备了模块化的视觉-语言模型(VLM)规划器和起始-目标热图引导机制(SGG),进一步实现了灵活的闭环控制,并支持原始级别策略在扩展的复杂任务上的组合泛化。该框架利用视频模型中的时空视觉先验和VLM的语义感知能力,弥合了细粒度物理交互和高层次推理之间的差距,为可扩展、可解释和通用的具身智能铺平了道路。
🔬 方法详解
问题定义:现有基于视频生成的具身世界模型需要大量的具身交互数据,而这些数据的收集成本高昂,且数据维度很高。这导致语言和动作之间的对齐粒度受限,并且加剧了长时域视频生成的难度,阻碍了生成模型在具身领域取得突破。
核心思路:论文的核心思路是观察到具身数据的多样性远超可能的原始运动空间。因此,通过将视频生成限制在固定的短视域内,可以简化学习过程,并实现语言概念与机器人动作视觉表示之间的细粒度对齐。这种方法旨在提高数据效率,并降低推理延迟。
技术框架:PEWM框架包含以下主要模块:1) 短视域视频生成模型,用于预测给定动作后的视觉状态;2) 模块化的视觉-语言模型(VLM)规划器,用于根据语言指令生成动作序列;3) 起始-目标热图引导机制(SGG),用于指导VLM规划器生成更有效的动作序列。整体流程是,首先使用VLM规划器和SGG机制生成动作序列,然后使用短视域视频生成模型预测执行动作后的视觉状态,最后根据预测结果调整动作序列,实现闭环控制。
关键创新:最重要的技术创新点在于将世界模型分解为原始运动的组合,并限制视频生成在短视域内。这与现有方法直接生成长时域视频不同,显著降低了学习的复杂性,并提高了数据效率。此外,结合VLM规划器和SGG机制,实现了更灵活的控制和组合泛化能力。
关键设计:论文中使用了模块化的VLM,允许灵活地替换不同的VLM模型。SGG机制通过生成起始和目标状态的热图,引导VLM规划器生成更有效的动作序列。损失函数可能包含视频生成损失、语言对齐损失和控制损失等,具体细节未知。
🖼️ 关键图片


📊 实验亮点
论文提出的PEWM框架在数据效率和推理速度方面取得了显著提升。具体性能数据未知,但通过限制短视域视频生成,PEWM能够使用更少的数据学习到更有效的世界模型。此外,模块化的VLM规划器和SGG机制也显著提高了控制的灵活性和泛化能力。与直接生成长时域视频的现有方法相比,PEWM在复杂任务上的表现更具优势。
🎯 应用场景
该研究成果可应用于各种机器人任务,例如家庭服务机器人、工业自动化机器人和自动驾驶等。通过学习原始运动的组合,机器人可以更有效地完成复杂的任务,并具备更强的泛化能力。此外,该方法还可以用于开发更智能的人机交互系统,使机器人能够更好地理解人类的指令。
📄 摘要(原文)
While video-generation-based embodied world models have gained increasing attention, their reliance on large-scale embodied interaction data remains a key bottleneck. The scarcity, difficulty of collection, and high dimensionality of embodied data fundamentally limit the alignment granularity between language and actions and exacerbate the challenge of long-horizon video generation--hindering generative models from achieving a "GPT moment" in the embodied domain. There is a naive observation: the diversity of embodied data far exceeds the relatively small space of possible primitive motions. Based on this insight, we propose a novel paradigm for world modeling--Primitive Embodied World Models (PEWM). By restricting video generation to fixed short horizons, our approach 1) enables fine-grained alignment between linguistic concepts and visual representations of robotic actions, 2) reduces learning complexity, 3) improves data efficiency in embodied data collection, and 4) decreases inference latency. By equipping with a modular Vision-Language Model (VLM) planner and a Start-Goal heatmap Guidance mechanism (SGG), PEWM further enables flexible closed-loop control and supports compositional generalization of primitive-level policies over extended, complex tasks. Our framework leverages the spatiotemporal vision priors in video models and the semantic awareness of VLMs to bridge the gap between fine-grained physical interaction and high-level reasoning, paving the way toward scalable, interpretable, and general-purpose embodied intelligence.