Exploiting Policy Idling for Dexterous Manipulation
作者: Annie S. Chen, Philemon Brakel, Antonia Bronars, Annie Xie, Sandy Huang, Oliver Groth, Maria Bauza, Markus Wulfmeier, Nicolas Heess, Dushyant Rao
分类: cs.RO, cs.LG
发布日期: 2025-08-21
备注: A similar version to this paper was accepted at IROS 2025
💡 一句话要点
提出Pause-Induced Perturbations方法,提升灵巧操作策略的探索与泛化能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 灵巧操作 强化学习 策略探索 机器人控制 扰动策略
📋 核心要点
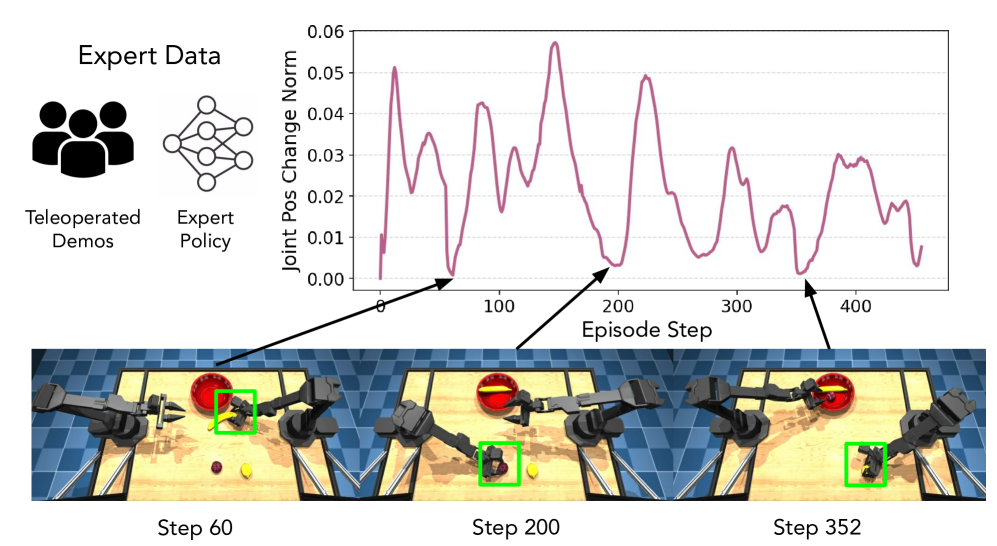
- 现有灵巧操作策略常出现“空转”现象,即在关键状态附近停止探索,导致策略鲁棒性不足。
- 论文提出Pause-Induced Perturbations (PIP)方法,通过在检测到的空转状态施加扰动,引导策略跳出局部最优。
- 实验表明,PIP方法在模拟和真实世界的插入任务中均能显著提升策略的成功率和泛化能力。
📝 摘要(中文)
近年来,基于学习的灵巧操作方法取得了显著进展。然而,学习到的策略通常缺乏可靠性,并且对重要的变化因素的鲁棒性有限。一个常见的失败模式是策略“空转”,即当到达某些状态时,策略停止移动并停留在小范围内。这种空转通常反映了训练数据的问题,例如,在需要高精度运动的区域(如准备抓取物体或物体插入时)数据包含小动作。先前的工作试图通过过滤训练数据或修改控制频率来缓解此问题,但这些方法可能会以其他方式对策略性能产生负面影响。作为替代方案,我们研究如何利用空转行为的可检测性来指导探索和策略改进。我们的方法,Pause-Induced Perturbations (PIP),在检测到的空转状态下应用扰动,从而帮助策略逃脱有问题的吸引盆。在一系列具有挑战性的模拟双臂任务中,我们发现这种简单的方法可以显著提高测试时的性能,而无需额外的监督或训练。此外,由于机器人倾向于在运动的关键点空转,我们还发现,与先前的方法相比,从生成的episode中学习可以实现更好的迭代策略改进。我们的扰动策略还在需要复杂多指操作的真实插入任务中实现了15-35%的绝对成功率提升。
🔬 方法详解
问题定义:论文旨在解决灵巧操作任务中,学习到的策略容易陷入“空转”状态的问题。这种空转通常发生在需要高精度操作的关键状态附近,例如抓取或插入操作的准备阶段。现有方法,如过滤数据或调整控制频率,虽然可以缓解空转,但可能损害策略在其他方面的性能。
核心思路:论文的核心思路是利用空转行为的可检测性,主动引导策略进行探索。具体而言,当检测到策略进入空转状态时,施加一个小的扰动,迫使策略离开当前的吸引盆,探索新的状态空间。这种方法无需额外的监督或训练,且能有效利用策略在关键点附近空转的特性。
技术框架:PIP方法主要包含以下几个阶段:1) 策略执行:使用当前策略控制机器人执行任务。2) 空转检测:实时监测机器人的状态,判断是否进入空转状态。空转状态的定义可以是速度低于某个阈值,或者位置变化小于某个范围。3) 扰动施加:如果检测到空转状态,则对机器人的控制指令施加一个随机扰动。扰动的大小和方向可以根据任务的特点进行调整。4) 策略更新:收集扰动后的episode,用于策略的迭代改进。
关键创新:PIP方法的关键创新在于其主动探索的策略。与传统的被动探索方法不同,PIP方法能够有针对性地在策略容易失败的关键状态附近进行探索,从而更有效地提升策略的鲁棒性和泛化能力。此外,PIP方法无需额外的监督或训练,易于集成到现有的强化学习框架中。
关键设计:空转检测的阈值是关键参数,需要根据任务的特点进行调整。扰动的大小和方向也需要仔细设计,以避免对策略造成过大的干扰。论文中,扰动的大小通常设置为一个较小的值,方向可以是随机的,也可以是根据任务的特点进行选择。策略更新可以使用任何现有的强化学习算法,例如PPO或SAC。
🖼️ 关键图片


📊 实验亮点
在模拟双臂操作任务中,PIP方法显著提高了测试时的性能,无需额外的监督或训练。在真实世界的插入任务中,PIP方法实现了15-35%的绝对成功率提升,表明该方法具有良好的泛化能力和实用价值。实验结果表明,从扰动后的episode中学习可以实现更好的迭代策略改进。
🎯 应用场景
该研究成果可应用于各种需要高精度操作的机器人任务,例如工业装配、医疗手术、家庭服务等。通过提高机器人的操作精度和鲁棒性,可以显著提升自动化水平,降低人工成本,并提高生产效率。此外,该方法还可以用于训练更加智能的机器人,使其能够更好地适应复杂和动态的环境。
📄 摘要(原文)
Learning-based methods for dexterous manipulation have made notable progress in recent years. However, learned policies often still lack reliability and exhibit limited robustness to important factors of variation. One failure pattern that can be observed across many settings is that policies idle, i.e. they cease to move beyond a small region of states when they reach certain states. This policy idling is often a reflection of the training data. For instance, it can occur when the data contains small actions in areas where the robot needs to perform high-precision motions, e.g., when preparing to grasp an object or object insertion. Prior works have tried to mitigate this phenomenon e.g. by filtering the training data or modifying the control frequency. However, these approaches can negatively impact policy performance in other ways. As an alternative, we investigate how to leverage the detectability of idling behavior to inform exploration and policy improvement. Our approach, Pause-Induced Perturbations (PIP), applies perturbations at detected idling states, thus helping it to escape problematic basins of attraction. On a range of challenging simulated dual-arm tasks, we find that this simple approach can already noticeably improve test-time performance, with no additional supervision or training. Furthermore, since the robot tends to idle at critical points in a movement, we also find that learning from the resulting episodes leads to better iterative policy improvement compared to prior approaches. Our perturbation strategy also leads to a 15-35% improvement in absolute success rate on a real-world insertion task that requires complex multi-finger manipulation.