Hardware Implementation of a Zero-Prior-Knowledge Approach to Lifelong Learning in Kinematic Control of Tendon-Driven Quadrupeds
作者: Hesam Azadjou, Suraj Chakravarthi Raja, Ali Marjaninejad, Francisco J. Valero-Cuevas
分类: cs.RO
发布日期: 2025-08-21
💡 一句话要点
提出一种零先验知识的终身学习方法,用于肌腱驱动四足机器人的运动控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 四足机器人 肌腱驱动 强化学习 零先验知识 终身学习
📋 核心要点
- 现有机器人控制方法通常依赖于对机器人结构和环境的完整知识,难以适应持续变化。
- 论文提出一种名为G2P的算法,模仿生物学习过程,通过泛化运动和后续细化来实现控制。
- 实验结果表明,该方法能够使肌腱驱动四足机器人在几分钟内学习复杂的周期性运动控制。
📝 摘要(中文)
本文提出了一种受生物启发的学习算法,即从泛化到特化(G2P),并将其应用于自主开发和制造的肌腱驱动四足机器人系统。该机器人首先进行五分钟的广义运动 babbling 阶段,然后进行 15 次细化试验(每次 20 秒),以实现特定的周期性运动。这个过程模仿了哺乳动物中观察到的探索-利用范式。通过每次细化,机器人在其最初的“足够好”的解决方案上逐步改进。结果验证了硬件在环系统中,仅需几分钟即可学习控制具有冗余的肌腱驱动四足机器人,从而实现功能性和适应性的周期性非凸运动。通过推进机器人运动中的自主控制,该方法为能够动态适应新环境的机器人铺平了道路,确保了持续的适应性和性能。
🔬 方法详解
问题定义:论文旨在解决四足机器人,特别是肌腱驱动型四足机器人,在缺乏先验知识的情况下,如何快速学习并适应复杂运动控制的问题。现有方法通常需要精确的机器人模型和环境信息,难以应对实际应用中模型不确定性和环境变化带来的挑战。此外,传统方法在面对冗余驱动系统时,控制策略的设计也更加复杂。
核心思路:论文的核心思路是模仿生物的学习机制,采用一种从泛化到特化(General-to-Particular, G2P)的学习策略。该策略首先通过广义的运动探索(motor babbling)来建立一个初步的、泛化的控制策略,然后通过一系列的细化试验,逐步优化该策略,使其能够适应特定的任务需求。这种方法避免了对精确模型的依赖,并且能够有效地利用冗余驱动系统。
技术框架:整体框架包含两个主要阶段:1) 广义运动探索阶段:机器人随机执行一系列运动,以探索其运动空间,并建立一个初步的控制策略。2) 细化学习阶段:机器人根据任务目标,通过一系列的试验,逐步调整控制策略,使其能够更好地完成任务。在每个试验中,机器人执行当前的控制策略,并根据结果调整控制参数。
关键创新:该方法的主要创新在于其零先验知识的学习能力和对生物学习机制的模仿。与传统的基于模型的控制方法不同,该方法不需要精确的机器人模型和环境信息,而是通过自主探索和学习来获得控制策略。此外,G2P算法能够有效地利用冗余驱动系统,提高机器人的运动能力和适应性。
关键设计:G2P算法的关键设计包括:1) 运动探索策略:采用随机运动探索策略,以覆盖尽可能多的运动空间。2) 细化学习算法:采用基于梯度的优化算法,根据任务目标调整控制参数。3) 奖励函数设计:设计合适的奖励函数,以引导机器人学习期望的运动行为。具体参数设置和网络结构(如果使用)在论文中可能包含更详细的描述,但摘要中未提及。
🖼️ 关键图片

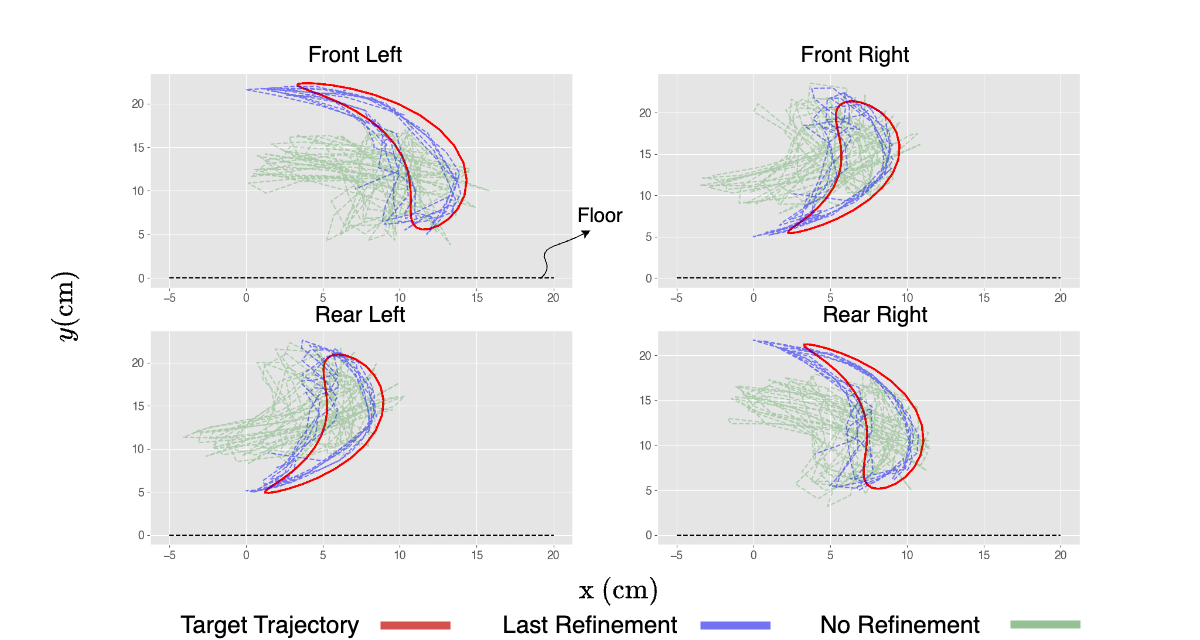
📊 实验亮点
实验结果表明,该方法能够使肌腱驱动四足机器人在短短几分钟内学习复杂的周期性运动控制。通过15次细化试验,机器人能够显著提高其运动性能,并实现功能性和适应性的周期性非凸运动。该结果验证了硬件在环系统中,该方法在实际机器人系统中的有效性。
🎯 应用场景
该研究成果可应用于各种需要在未知或变化环境中进行自主运动控制的机器人系统,例如搜救机器人、探索机器人和辅助机器人。该方法能够使机器人在没有预先编程的情况下,快速适应新的环境和任务,从而提高机器人的自主性和适应性。此外,该方法还可以应用于其他类型的机器人系统,例如人形机器人和水下机器人。
📄 摘要(原文)
Like mammals, robots must rapidly learn to control their bodies and interact with their environment despite incomplete knowledge of their body structure and surroundings. They must also adapt to continuous changes in both. This work presents a bio-inspired learning algorithm, General-to-Particular (G2P), applied to a tendon-driven quadruped robotic system developed and fabricated in-house. Our quadruped robot undergoes an initial five-minute phase of generalized motor babbling, followed by 15 refinement trials (each lasting 20 seconds) to achieve specific cyclical movements. This process mirrors the exploration-exploitation paradigm observed in mammals. With each refinement, the robot progressively improves upon its initial "good enough" solution. Our results serve as a proof-of-concept, demonstrating the hardware-in-the-loop system's ability to learn the control of a tendon-driven quadruped with redundancies in just a few minutes to achieve functional and adaptive cyclical non-convex movements. By advancing autonomous control in robotic locomotion, our approach paves the way for robots capable of dynamically adjusting to new environments, ensuring sustained adaptability and performance.