Utilizing Vision-Language Models as Action Models for Intent Recognition and Assistance
作者: Cesar Alan Contreras, Manolis Chiou, Alireza Rastegarpanah, Michal Szulik, Rustam Stolkin
分类: cs.RO, cs.AI, cs.HC
发布日期: 2025-08-14
备注: Accepted at Human-Centered Robot Autonomy for Human-Robot Teams (HuRoboT) at IEEE RO-MAN 2025, Eindhoven, the Netherlands
💡 一句话要点
利用视觉-语言模型增强机器人意图识别与辅助能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 人机协作 意图识别 视觉-语言模型 机器人辅助 语义理解
📋 核心要点
- 现有机器人协作系统在快速推断用户意图方面存在不足,缺乏透明的推理过程。
- 本文提出利用视觉-语言模型和文本语言模型,构建语义先验,过滤无关对象,提升意图识别的准确性。
- 未来的工作将在真实机器人平台上进行实验验证,评估系统在实时辅助方面的性能。
📝 摘要(中文)
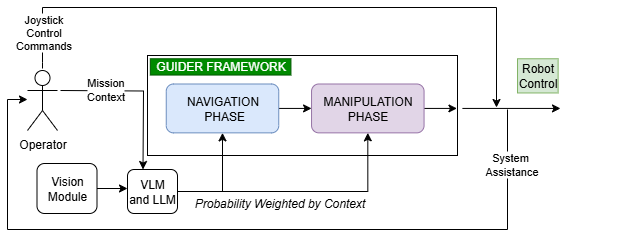
本文提出了一种增强GUIDER框架的方法,用于推断导航和操作意图,以实现人机协作。该方法利用视觉-语言模型(VLM)和纯文本语言模型(LLM)形成语义先验,根据任务提示过滤对象和位置。视觉流程(YOLO用于对象检测,Segment Anything Model用于实例分割)将候选对象裁剪输入VLM,VLM根据操作员提示对相关性进行评分;此外,检测到的对象标签列表由纯文本LLM进行排序。这些分数用于加权GUIDER现有的导航和操作层,选择上下文相关的目标,同时抑制不相关的对象。一旦组合置信度超过阈值,自主性发生变化,使机器人能够导航到所需区域并检索所需对象,同时适应操作员意图的任何变化。未来的工作将在Isaac Sim上使用Franka Emika机械臂和Ridgeback底盘评估该系统,重点是实时辅助。
🔬 方法详解
问题定义:现有的人机协作系统难以快速准确地推断用户的意图,并且缺乏透明的推理过程,导致机器人难以提供有效的辅助。现有方法通常依赖于预定义的规则或简单的视觉特征,无法很好地理解用户的复杂指令和动态变化的需求。
核心思路:本文的核心思路是利用视觉-语言模型(VLM)和文本语言模型(LLM)的强大语义理解能力,构建一个语义先验,从而过滤掉与用户意图无关的对象和位置,提高意图识别的准确性和效率。通过将视觉信息和语言信息相结合,机器人可以更好地理解用户的指令,并根据上下文选择合适的行动。
技术框架:该方法在GUIDER框架的基础上进行增强,主要包含以下几个模块:1) 视觉感知模块:使用YOLO进行对象检测,使用Segment Anything Model进行实例分割,提取候选对象区域。2) 语义理解模块:使用VLM对候选对象区域进行评分,评估其与用户指令的相关性;使用LLM对检测到的对象标签进行排序,进一步筛选相关对象。3) 意图推理模块:将VLM和LLM的评分结果加权融合到GUIDER的导航和操作层,选择上下文相关的目标。4) 行为执行模块:当组合置信度超过阈值时,机器人自主导航到目标区域并检索目标对象。
关键创新:该方法最重要的创新点在于将视觉-语言模型和文本语言模型引入到机器人意图识别和辅助系统中,利用其强大的语义理解能力来提高意图识别的准确性和鲁棒性。与传统的基于规则或简单视觉特征的方法相比,该方法能够更好地理解用户的复杂指令和动态变化的需求。
关键设计:VLM的选择和训练、LLM的选择和训练、VLM和LLM评分的加权融合方式、置信度阈值的设定等是关键的设计细节。论文中提到使用YOLO和Segment Anything Model进行视觉感知,但没有详细说明VLM和LLM的具体选择和训练方式,以及加权融合的具体公式。这些细节将直接影响系统的性能。
🖼️ 关键图片

📊 实验亮点
论文目前处于仿真阶段,未来的工作将在Isaac Sim上使用Franka Emika机械臂和Ridgeback底盘评估该系统,重点是实时辅助。虽然没有给出具体的性能数据,但该研究为机器人意图识别和辅助提供了一种新的思路,具有潜在的应用价值。
🎯 应用场景
该研究成果可应用于各种人机协作场景,例如:智能家居、仓储物流、医疗康复等。在智能家居中,机器人可以根据用户的语音指令和视觉信息,帮助用户完成各种家务任务。在仓储物流中,机器人可以根据订单信息和环境感知,自主完成货物的拣选和搬运。在医疗康复中,机器人可以根据患者的需求和身体状况,提供个性化的康复训练。
📄 摘要(原文)
Human-robot collaboration requires robots to quickly infer user intent, provide transparent reasoning, and assist users in achieving their goals. Our recent work introduced GUIDER, our framework for inferring navigation and manipulation intents. We propose augmenting GUIDER with a vision-language model (VLM) and a text-only language model (LLM) to form a semantic prior that filters objects and locations based on the mission prompt. A vision pipeline (YOLO for object detection and the Segment Anything Model for instance segmentation) feeds candidate object crops into the VLM, which scores their relevance given an operator prompt; in addition, the list of detected object labels is ranked by a text-only LLM. These scores weight the existing navigation and manipulation layers of GUIDER, selecting context-relevant targets while suppressing unrelated objects. Once the combined belief exceeds a threshold, autonomy changes occur, enabling the robot to navigate to the desired area and retrieve the desired object, while adapting to any changes in the operator's intent. Future work will evaluate the system on Isaac Sim using a Franka Emika arm on a Ridgeback base, with a focus on real-time assistance.