3D FlowMatch Actor: Unified 3D Policy for Single- and Dual-Arm Manipulation
作者: Nikolaos Gkanatsios, Jiahe Xu, Matthew Bronars, Arsalan Mousavian, Tsung-Wei Ke, Katerina Fragkiadaki
分类: cs.RO
发布日期: 2025-08-14 (更新: 2025-08-20)
备注: Project page: https://3d-flowmatch-actor.github.io/
💡 一句话要点
提出3D FlowMatch Actor,加速3D机器人操作策略学习,并在单双臂任务上取得领先。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 流匹配 3D视觉 策略学习 深度学习 双臂机器人 单臂机器人
📋 核心要点
- 现有3D扩散策略训练和推理速度慢,限制了其在机器人操作中的应用。
- 3DFA结合流匹配和3D预训练视觉表示,利用3D相对注意力加速策略学习。
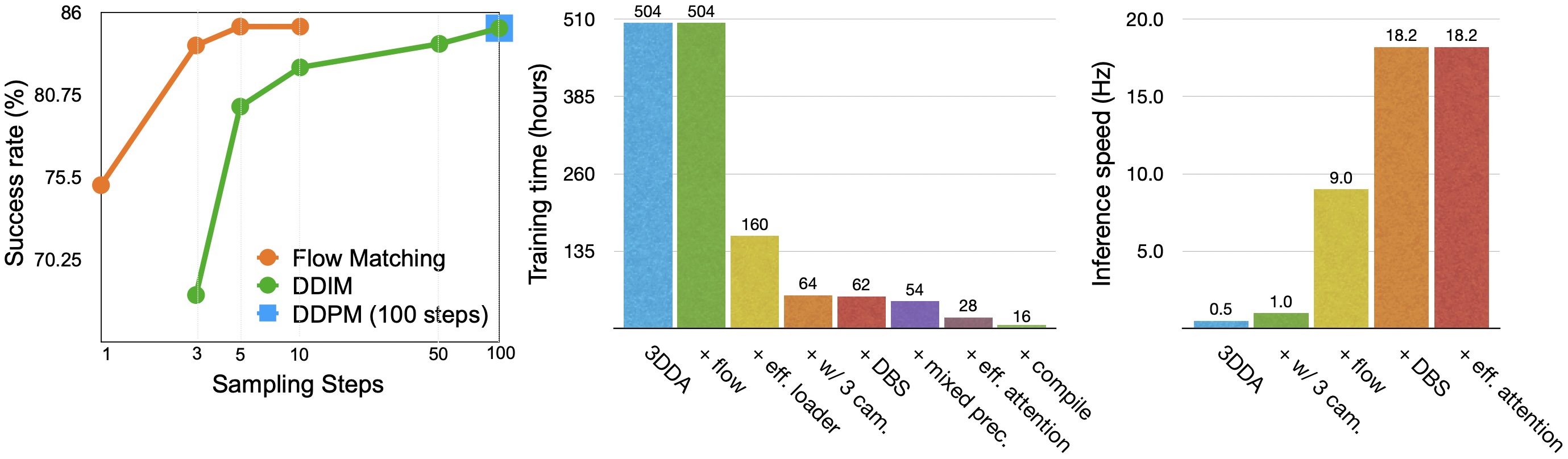
- 实验表明,3DFA在单双臂任务上均取得显著性能提升,并大幅提升训练和推理效率。
📝 摘要(中文)
本文提出了一种名为3D FlowMatch Actor (3DFA) 的机器人操作3D策略架构,它结合了用于轨迹预测的流匹配和用于从演示中学习的3D预训练视觉场景表示。3DFA利用动作和视觉tokens之间的3D相对注意力进行动作去噪,并建立在先前基于3D扩散的单臂策略学习工作之上。通过流匹配以及有针对性的系统级和架构优化,3DFA实现了比以前的基于3D扩散的策略快30倍以上的训练和推理速度,且不牺牲性能。在双臂PerAct2基准测试中,它建立了新的state-of-the-art,超过了次优方法41.4%。在广泛的真实世界评估中,它超越了具有高达1000倍参数和更多预训练的强大基线。在单臂设置中,它通过直接预测密集的末端执行器轨迹,在74个RLBench任务上设置了新的state-of-the-art,无需运动规划。全面的消融研究强调了我们的设计选择对于策略有效性和效率的重要性。
🔬 方法详解
问题定义:现有基于3D扩散的机器人操作策略存在训练和推理速度慢的问题,这限制了它们在实际机器人应用中的部署。尤其是在需要快速响应和实时控制的场景下,高延迟的策略学习方法难以满足需求。此外,如何有效地利用视觉信息来指导动作生成也是一个挑战。
核心思路:3DFA的核心思路是将流匹配(Flow Matching)技术与3D预训练视觉场景表示相结合,从而加速轨迹预测过程,并提高策略的学习效率。通过在动作去噪过程中引入3D相对注意力机制,使得策略能够更好地理解动作和视觉信息之间的关系,从而生成更精确的动作序列。
技术框架:3DFA的整体框架包括以下几个主要模块:1) 3D视觉场景表示模块,用于提取场景的3D特征;2) 流匹配模块,用于预测轨迹;3) 动作去噪模块,利用3D相对注意力机制对动作进行优化。该框架首先利用3D视觉场景表示模块提取场景特征,然后使用流匹配模块生成初始轨迹,最后通过动作去噪模块对轨迹进行优化,得到最终的动作序列。
关键创新:3DFA的关键创新在于以下几个方面:1) 结合流匹配和3D预训练视觉表示,显著提高了训练和推理速度;2) 引入3D相对注意力机制,增强了策略对动作和视觉信息之间关系的理解;3) 通过系统级和架构优化,进一步提升了策略的效率和性能。与现有方法相比,3DFA在保证性能的同时,大幅降低了计算成本。
关键设计:3DFA的关键设计包括:1) 使用预训练的3D视觉模型来初始化视觉表示模块;2) 设计特定的损失函数来优化流匹配过程;3) 采用Transformer架构来实现3D相对注意力机制;4) 通过调整网络结构和参数,优化策略的效率和性能。具体的参数设置和网络结构细节需要在论文中查找。
🖼️ 关键图片


📊 实验亮点
3DFA在bimanual PerAct2基准测试中取得了state-of-the-art的结果,超越了次优方法41.4%。在真实世界评估中,3DFA超越了具有高达1000倍参数和更多预训练的强大基线。在单臂设置中,3DFA在74个RLBench任务上设置了新的state-of-the-art,无需运动规划。训练和推理速度比之前的3D扩散策略快30倍以上。
🎯 应用场景
该研究成果可广泛应用于各种机器人操作任务,如工业自动化、家庭服务、医疗辅助等。通过提高机器人操作策略的学习效率和性能,可以实现更智能、更灵活的机器人系统,从而提升生产效率和服务质量。未来,该技术有望推动机器人技术在更多领域的应用。
📄 摘要(原文)
We present 3D FlowMatch Actor (3DFA), a 3D policy architecture for robot manipulation that combines flow matching for trajectory prediction with 3D pretrained visual scene representations for learning from demonstration. 3DFA leverages 3D relative attention between action and visual tokens during action denoising, building on prior work in 3D diffusion-based single-arm policy learning. Through a combination of flow matching and targeted system-level and architectural optimizations, 3DFA achieves over 30x faster training and inference than previous 3D diffusion-based policies, without sacrificing performance. On the bimanual PerAct2 benchmark, it establishes a new state of the art, outperforming the next-best method by an absolute margin of 41.4%. In extensive real-world evaluations, it surpasses strong baselines with up to 1000x more parameters and significantly more pretraining. In unimanual settings, it sets a new state of the art on 74 RLBench tasks by directly predicting dense end-effector trajectories, eliminating the need for motion planning. Comprehensive ablation studies underscore the importance of our design choices for both policy effectiveness and efficiency.