TLE-Based A2C Agent for Terrestrial Coverage Orbital Path Planning
作者: Anantha Narayanan, Battu Bhanu Teja, Pruthwik Mishra
分类: cs.RO, cs.AI
发布日期: 2025-08-14
备注: 8 pages, 6 figures, 5 tables
💡 一句话要点
提出基于TLE的A2C算法,解决LEO卫星地面覆盖轨道规划问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 轨道规划 A2C算法 低地球轨道 卫星任务规划
📋 核心要点
- 低地球轨道日益拥挤,对地球观测卫星的有效部署和安全运行构成挑战,需要考虑避碰风险。
- 利用A2C算法,通过调整卫星的半长轴、偏心率等轨道参数,实现对特定地面区域的精准覆盖。
- 实验表明,A2C算法在累积奖励和收敛速度上均优于PPO算法,证明了其在轨道控制方面的优势。
📝 摘要(中文)
本文提出了一种基于强化学习的框架,使用优势演员-评论家(A2C)算法来优化卫星轨道参数,以实现预定义表面半径内的精确地面覆盖。该方法将问题建模为OpenAI Gymnasium环境中的马尔可夫决策过程(MDP),并使用经典的开普勒元素模拟轨道动力学。智能体逐步学习调整五个轨道参数——半长轴、偏心率、倾角、升交点赤经和近地点幅角——以实现目标地面覆盖。与近端策略优化(PPO)的比较评估表明,A2C具有更优越的性能,实现了5.8倍的累积奖励(10.0 vs 9.263025),同时收敛速度快31.5倍(2,000 vs 63,000步)。A2C智能体在不同的目标坐标下始终满足任务目标,同时保持了适用于实时任务规划应用的计算效率。该方法为可扩展和智能的LEO任务规划建立了一种计算高效的强化学习替代方案。
🔬 方法详解
问题定义:论文旨在解决低地球轨道(LEO)日益拥挤带来的卫星部署和运行挑战,特别是如何高效、安全地规划卫星轨道,以实现对特定地面区域的精确覆盖。现有方法难以兼顾任务需求和日益增长的碰撞风险,计算复杂度高,难以适应实时任务规划。
核心思路:论文的核心思路是将轨道规划问题建模为马尔可夫决策过程(MDP),并利用强化学习算法(A2C)训练智能体,使其能够自主学习并优化卫星的轨道参数,从而在满足地面覆盖要求的同时,降低碰撞风险,提高任务效率。这种方法能够自适应地调整轨道参数,应对不同的任务需求和环境变化。
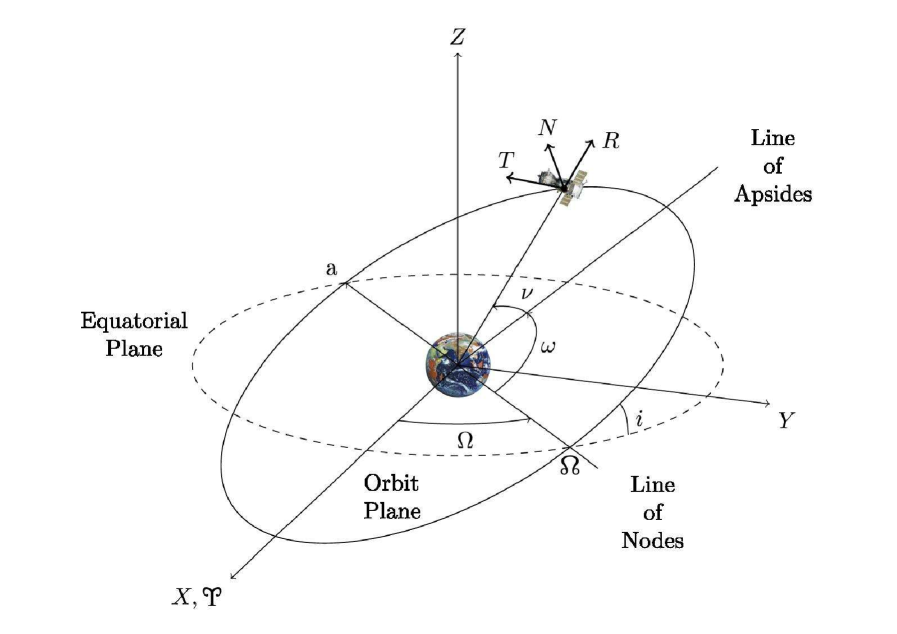
技术框架:整体框架包括一个基于TLE(Two-Line Element)的轨道仿真环境,该环境模拟了卫星的轨道动力学,并考虑了物理约束。A2C智能体与该环境交互,通过不断试错学习,调整五个轨道参数(半长轴、偏心率、倾角、升交点赤经和近地点幅角)。智能体根据当前状态(卫星轨道参数和目标地面位置)选择动作(轨道参数调整),环境返回奖励(地面覆盖效果和碰撞风险),智能体根据奖励更新策略。
关键创新:最重要的技术创新点在于将强化学习应用于卫星轨道规划,并验证了Actor-Critic方法在连续轨道控制中的优越性。与传统的基于信任域的方法(如PPO)相比,A2C算法能够更快地收敛,并获得更高的累积奖励。此外,该方法还提出了一个基于TLE的轨道仿真环境,能够更真实地模拟卫星的轨道动力学。
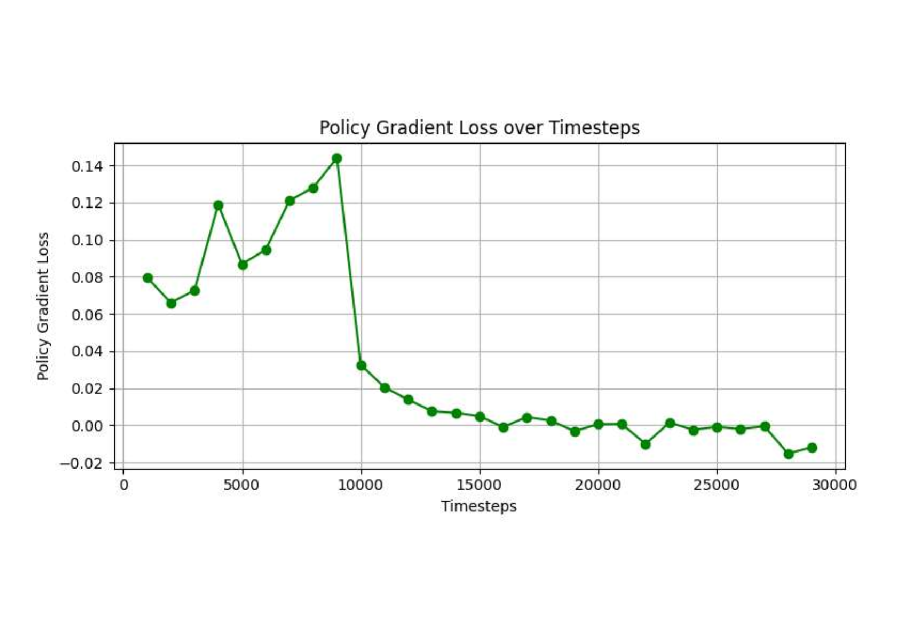
关键设计:论文使用A2C算法作为强化学习智能体,该算法结合了Actor和Critic两个网络。Actor网络负责选择动作(轨道参数调整),Critic网络负责评估当前状态的价值。损失函数包括Actor网络的策略梯度损失和Critic网络的均方误差损失。奖励函数的设计至关重要,它需要综合考虑地面覆盖效果和碰撞风险。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,A2C算法在轨道规划任务中表现优异,相较于PPO算法,A2C的累积奖励提高了5.8倍(10.0 vs 9.263025),收敛速度加快了31.5倍(2,000 vs 63,000步)。这些数据表明,A2C算法在连续轨道控制方面具有显著优势,能够更快速、更有效地实现目标地面覆盖。
🎯 应用场景
该研究成果可应用于地球观测卫星的任务规划、星座部署和在轨管理等领域。通过强化学习优化卫星轨道,可以提高地面覆盖效率,降低碰撞风险,并实现卫星的自适应部署。该方法还可扩展到其他航天任务,如空间碎片清除和深空探测等,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
The increasing congestion of Low Earth Orbit (LEO) poses persistent challenges to the efficient deployment and safe operation of Earth observation satellites. Mission planners must now account not only for mission-specific requirements but also for the increasing collision risk with active satellites and space debris. This work presents a reinforcement learning framework using the Advantage Actor-Critic (A2C) algorithm to optimize satellite orbital parameters for precise terrestrial coverage within predefined surface radii. By formulating the problem as a Markov Decision Process (MDP) within a custom OpenAI Gymnasium environment, our method simulates orbital dynamics using classical Keplerian elements. The agent progressively learns to adjust five of the orbital parameters - semi-major axis, eccentricity, inclination, right ascension of ascending node, and the argument of perigee-to achieve targeted terrestrial coverage. Comparative evaluation against Proximal Policy Optimization (PPO) demonstrates A2C's superior performance, achieving 5.8x higher cumulative rewards (10.0 vs 9.263025) while converging in 31.5x fewer timesteps (2,000 vs 63,000). The A2C agent consistently meets mission objectives across diverse target coordinates while maintaining computational efficiency suitable for real-time mission planning applications. Key contributions include: (1) a TLE-based orbital simulation environment incorporating physics constraints, (2) validation of actor-critic methods' superiority over trust region approaches in continuous orbital control, and (3) demonstration of rapid convergence enabling adaptive satellite deployment. This approach establishes reinforcement learning as a computationally efficient alternative for scalable and intelligent LEO mission planning.