CorrectNav: Self-Correction Flywheel Empowers Vision-Language-Action Navigation Model
作者: Zhuoyuan Yu, Yuxing Long, Zihan Yang, Chengyan Zeng, Hongwei Fan, Jiyao Zhang, Hao Dong
分类: cs.RO, cs.AI, cs.CL, cs.CV
发布日期: 2025-08-14
💡 一句话要点
提出CorrectNav,利用自校正飞轮机制提升视觉-语言-动作导航模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言导航 自校正学习 机器人导航 错误纠正 后训练 飞轮机制
📋 核心要点
- 现有视觉-语言导航模型易偏离正确轨迹,缺乏有效纠错能力,难以从错误中恢复。
- 提出自校正飞轮范式,利用模型错误轨迹生成自校正数据,迭代训练提升导航能力。
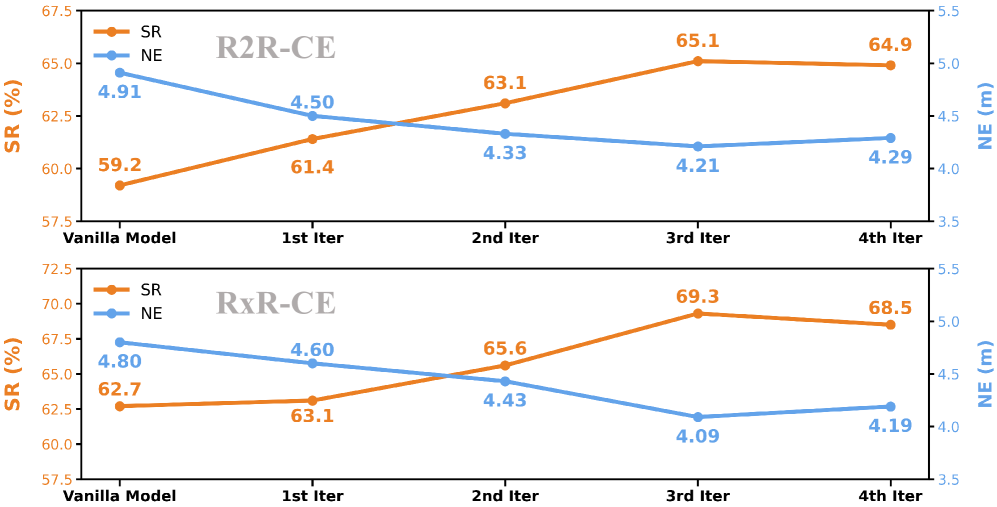
- CorrectNav在R2R-CE和RxR-CE上分别取得65.1%和69.3%的成功率,显著超越现有技术。
📝 摘要(中文)
现有的视觉-语言导航模型在执行指令时经常偏离正确轨迹,并且缺乏有效的纠错能力,难以从错误中恢复。为了解决这个问题,我们提出了一种新颖的后训练范式——自校正飞轮。我们的范式没有将模型在训练集上的错误轨迹视为缺点,而是强调了它们作为宝贵数据源的重要性。我们开发了一种方法来识别这些错误轨迹中的偏差,并设计了创新的技术来自动生成用于感知和动作的自校正数据。这些自校正数据作为燃料,为模型的持续训练提供动力。当我们在训练集上重新评估模型时,会发现新的错误轨迹,此时自校正飞轮开始旋转。通过多次飞轮迭代,我们逐步增强了基于单目RGB的VLA导航模型CorrectNav。在R2R-CE和RxR-CE基准测试中,CorrectNav取得了新的state-of-the-art成功率,分别为65.1%和69.3%,超过了之前最好的VLA导航模型8.2%和16.4%。在各种室内和室外环境中的真实机器人测试表明,该方法具有卓越的纠错、动态避障和长指令跟随能力。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作导航(VLA Navigation)模型在执行指令时容易出错,且缺乏有效纠错能力的问题。现有方法通常将训练集上的错误轨迹视为需要避免的负面因素,而忽略了其中蕴含的纠错信息。这些错误会导致模型在实际应用中偏离目标,尤其是在复杂或未知的环境中。
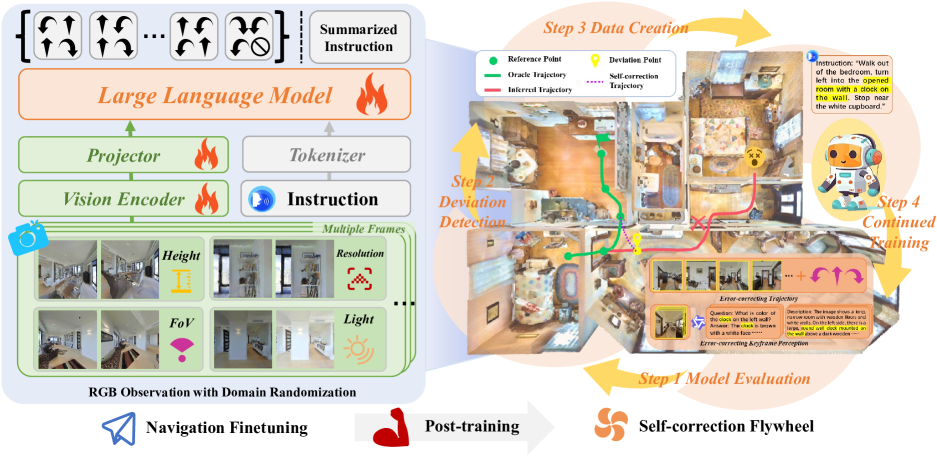
核心思路:论文的核心思路是将模型自身的错误轨迹视为宝贵的数据来源,通过分析这些轨迹中的偏差,自动生成自校正数据,并利用这些数据进行持续训练,从而提升模型的纠错能力。这种“自校正飞轮”机制能够不断挖掘新的错误,并针对性地进行改进,实现性能的迭代提升。
技术框架:CorrectNav的整体框架包含以下几个主要阶段:1) 初始模型训练:使用标准的VLA导航数据集训练一个初始模型。2) 错误轨迹识别:在训练集上运行初始模型,记录其产生的错误轨迹,并识别轨迹中的偏差。3) 自校正数据生成:根据识别出的偏差,自动生成用于感知和动作的自校正数据。4) 模型再训练:使用原始训练数据和生成的自校正数据,对模型进行再训练。5) 迭代优化:重复步骤2-4,形成自校正飞轮,不断提升模型性能。
关键创新:论文最重要的技术创新在于提出了自校正飞轮范式,将模型的错误轨迹转化为有价值的训练数据。与传统的监督学习方法不同,该方法能够主动挖掘模型自身的弱点,并针对性地进行改进。此外,自动生成自校正数据的方法也降低了人工标注的成本。
关键设计:论文中关于自校正数据的生成方法是关键设计之一。具体而言,对于感知方面的错误,可以通过图像增强、视角变换等方式生成更具挑战性的训练样本。对于动作方面的错误,可以通过模仿学习或强化学习的方式,让模型学习正确的动作序列。损失函数方面,可以使用交叉熵损失或hinge loss来鼓励模型输出正确的动作。具体的网络结构细节(如使用的Transformer层数、embedding维度等)在论文中可能没有详细描述,属于实现细节,需要参考相关VLA导航模型的文献。
🖼️ 关键图片

📊 实验亮点
CorrectNav在R2R-CE和RxR-CE基准测试中取得了显著的性能提升,成功率分别达到65.1%和69.3%,超越了之前最好的VLA导航模型8.2%和16.4%。此外,在真实机器人实验中,CorrectNav也展现出卓越的纠错、动态避障和长指令跟随能力,验证了该方法的有效性和实用性。
🎯 应用场景
CorrectNav技术可广泛应用于机器人导航、自动驾驶、智能家居等领域。通过提升机器人自主导航的准确性和鲁棒性,可以实现更高效的物流配送、更安全的自动驾驶以及更智能的家庭服务。该研究有望推动机器人技术在复杂环境中的应用,并为人类生活带来便利。
📄 摘要(原文)
Existing vision-and-language navigation models often deviate from the correct trajectory when executing instructions. However, these models lack effective error correction capability, hindering their recovery from errors. To address this challenge, we propose Self-correction Flywheel, a novel post-training paradigm. Instead of considering the model's error trajectories on the training set as a drawback, our paradigm emphasizes their significance as a valuable data source. We have developed a method to identify deviations in these error trajectories and devised innovative techniques to automatically generate self-correction data for perception and action. These self-correction data serve as fuel to power the model's continued training. The brilliance of our paradigm is revealed when we re-evaluate the model on the training set, uncovering new error trajectories. At this time, the self-correction flywheel begins to spin. Through multiple flywheel iterations, we progressively enhance our monocular RGB-based VLA navigation model CorrectNav. Experiments on R2R-CE and RxR-CE benchmarks show CorrectNav achieves new state-of-the-art success rates of 65.1% and 69.3%, surpassing prior best VLA navigation models by 8.2% and 16.4%. Real robot tests in various indoor and outdoor environments demonstrate \method's superior capability of error correction, dynamic obstacle avoidance, and long instruction following.